要理解这一现象,就需要深入了解 AI 技术本身的演变。
传统的大语言模型训练需要大量的电力和计算时间。然而,人们正在快速找到办法,来减少用户运行大语言模型时所需的资源量。推理模型与大语言模型不同,它们以大语言模型为基础,但在实际运行过程中消耗的资源(包含芯片和电力)要多很多。
OpenAI 在 9 月发布了其首个推理模型 o1 。自那之后,AI 公司纷纷推出了竞争产品。其中有在今年年初震撼了 AI 界,并且改变了众多科技和电力公司估值的 DeepSeek R1 。另外还有埃隆·马斯克旗下的 Grok 3 推理模型。
DeepSeek 引起恐慌的原因是它展示了一种可能性,即能用其他模型成本的一小部分来训练 AI。这种可能性可能会降低对数据中心以及昂贵、先进芯片的需求。然而实际上,DeepSeek 促使 AI 行业发展资源需求量更大的推理模型,这表明基础算力设施依然是非常必要的。
推理模型的资源需求
推理模型及其相关产品,例如“Deep research”工具和 AI agent,为什么需要如此多的资源呢?答案在于它们的工作方式。
Nvidia 的 AI 产品管理副总裁 Kari Briski 近期表明,推理模型能够轻易地消耗比传统大语言模型多 100 倍的计算资源。这种消耗的倍增源于推理模型在长时间的“思维链”中会与自身进行对话(并非所有对话用户都能看见)。模型所使用的计算资源和生成的单词数量呈正比关系,所以生成 100 倍单词数量的推理模型将会消耗更多的电力和资源。
推理模型访问互联网时,资源需求量会有所增加。例如谷歌的相关模型、OpenAI 的相关模型以及 Perplexity 的 Deep research 模型等,都会使资源需求量进一步提升。
这个数量的资源需求仅仅是一个开端。谷歌计划在 2025 年支出至少一定数额的资金,微软也有相应计划,meta 同样如此,它们共同在 2025 年要支出至少 2150 亿美元,比去年增加 45%,并且其中的大部分资金将用于 AI 数据中心。
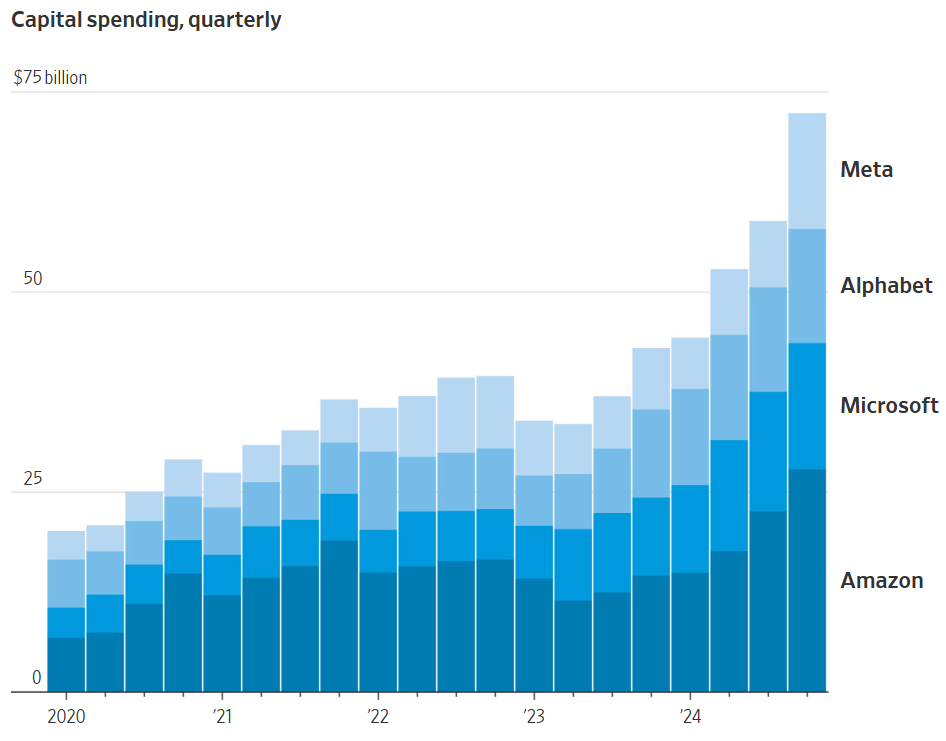
科技巨头们的季度资本支出
未来AI有多大需求?
为了预测未来 AI 的需求量,我们能够列出一个简单的等式。这个等式中的第一个值,是像 GPT 这样的大模型处理单个标记所需要的计算量。
1 月,中国 AI 模型 DeepSeek R1 发布了。此后,每个标记的成本,包括算力资源和金钱方面的成本,似乎会大幅度下降。DeepSeek 以及其相关论文展示出了一种方法,这种方法能够以比美国 AI 实验室先前披露的方法更高效的方式来训练和交付 AI。
表面上看,这似乎表明未来 AI 对算力的需求将大幅降低,例如降低到当前的十分之一。然而,推理模型在“思考”过程中所增加的需求能够弥补这一降低。简单来讲,像 DeepSeek 这样高效的 AI 模型,能将对算力的需求减少到十分之一,但倘若整个行业对推理模型的需求增加 100 倍,那么未来 AI 对算力的需求仍将是现在的 10 倍。

位于智利圣地亚哥的谷歌数据中心
1000倍增长
企业发现新的 AI 模型更为强大,于是它们会越来越频繁地调用这些模型。这样一来,算力的需求就从训练模型转变为使用模型,也就是 AI 行业里的“推理”。
baseten 的 CEO Tuhin Srivastava 称,这种向“推理”的转变正在推进。他的客户涵盖了在应用程序和服务中运用 AI 的科技公司,像 Descript 以及 PicnicHealth 等。这些客户察觉到,随着自身产品需求的迅猛增加,他们需要更多的 AI 处理能力。
未来几年,技术创新以及更先进 AI 芯片的出现或许意味着,向客户提供 AI 的系统在效率方面会比现今高出一千倍。风险投资家 Tomasz Tunguz 指出,投资者和大型科技公司在进行押注,他们认为在未来十年里,由于推理模型以及 AI 的快速普及,对 AI 模型的需求有可能会增加一万亿倍甚至更多。
你在键盘上按下的每一次按键,都将由至少一个 AI 进行转录;你对着麦克风说出的每一个音素,也都将由至少一个 AI 进行处理。Tunguz 说。他补充道,如果情况确实如此,那么 AI 市场可能很快就会比现在大 1000 倍。
更多的一手新闻,大家可以下载凤凰新闻客户端来订阅凤凰网科技。如果想看深度报道的话,就用微信搜索“凤凰网科技”。
