马斯克的人工智能初创公司 xAI 发布了新的 Groke 3 大模型。马斯克将其称作“在地球上属于最为聪明的人工智能”。
Grok 3 是通过 20 万块英伟达芯片进行训练而得出的。它的运算能力比上一代要高出 10 倍。
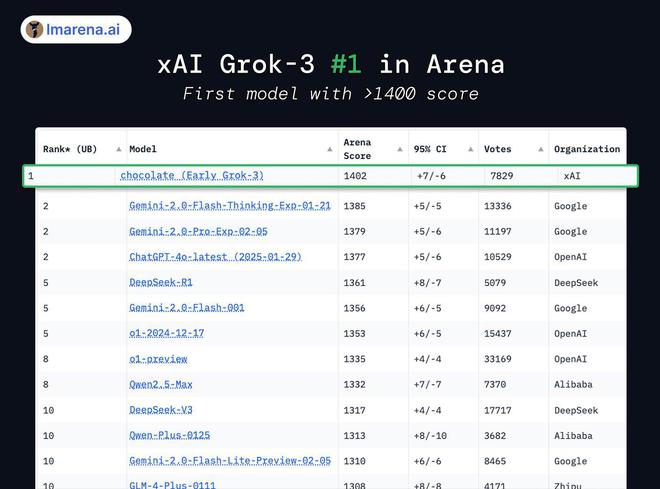
马斯克在当天的直播中与 xAI 的三位工程师一同进行了现场演示。在数学、科学和编程基准测试里,Grok 3 击败了谷歌 Gemini、DeepSeek 的 V3 模型、Anthropic 的 Claude 以及 OpenAI 的 GPT-4o。
马斯克此前曾介绍,Grok 3 是在数量众多的合成数据上进行训练的。它会对数据进行反复的检查,目的是要达到逻辑上的一致性。倘若存在错误的数据,它会进行反思并且将错误数据删除。
从目前的测试情况来看,Grok3 在 AIME'24 数学能力测试方面的成绩高于 DeepSeek,在 GPQA 科学知识评估方面的成绩也高于 DeepSeek,在 LCB Oct - Feb 编程能力测试等多项测试中成绩同样高于 DeepSeek。Grok3 拥有“思维链”推理机制,能够像人类一样逐步对复杂任务进行拆解。它的参数量达到了 1 万亿级别。
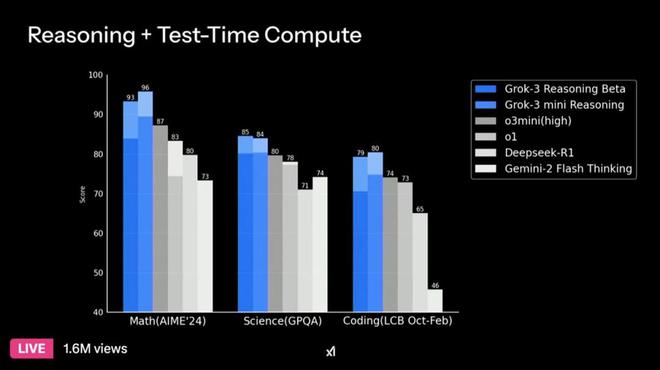
Grok3 在很多任务上表现出色,比如在处理复杂逻辑和推理任务时,它具备一定能力。然而,Grok3 通过大量使用 GPU 提升了榜单上的分数,其数学和编程方面的分数虽高,但与其他相比并没有明显优势,没有拉开差距。而 DeepSeek 的优势在于中文理解和多模态交互,它的表现一直较为稳定,在实际应用场景中已得到了许多验证。
关键问题是,Grok3 的成本极高。它的计算量是前代 Grok2 的 10 倍。有说法称其训练成本达到 30 亿美元。据相关工程师透露,xAI 旗下超算中心的算力已经翻倍。

去年 4 月,马斯克觉得 xAI 若要成功打造出最佳 AI,那唯一的办法就是自建数据中心。因为想要尽快推出 Grok 3,时间很紧张,所以就决定在四个月内把数据中心建成。最终,团队经过 122 天让第一批 10 万个 GPU 开始运行,不过要构建理想中的 AI 还得将集群规模增加一倍。发布会上有消息透露,团队实现超算集群的算力翻倍仅用了 92 天。这意味着 GPU 的数量已经达到了 20 万块。

英伟达 H100 单卡价格约为 2.5 万到 3 万美元,20 万块 GPU 的价格是多少呢?20 万块乘以 3 万美元等于 60 亿美元,这仅仅是硬件采购成本。实际部署成本更高,还需要考虑配套服务器、网络设备、电力、冷却设施等,总成本可能达到百亿美元量级,即便砍掉一半也高达 50 亿美元。
那么综合能力肯定不会比 Grok3 差。
Grok 3,印证了DeepSeek真的强
这说明了两件事。其一,马斯克投入了大量的资金,堆砌起了比 OpenAI 还要多的计算能力。其二,最终他所研发出来的产品与 OpenAI 的产品相差无几。第二,这证明了 DeepSeek 的确很强。马斯克耗费大量美金如同烧柴般搞炼丹,其效果完全依赖于堆砌硬件。并且从数据方面来看,与 DeepSeek 之间并未拉开很大差距。DeepSeek 采取低成本路线都能几乎打成平手,这就更能说明 DeepSeek 极为强大。
这是两条不同的路线。一条路线是力大拍砖,大力出奇迹,坚定地砸钱堆算力;另一条路线是创新的工程设计与高效的训练方法,通过优化节省资源,追求极致性价比。这两条路线完全不同。
堆算力的游戏,意味着 AI 成为了美国人主导算力资源分配的游戏。美国能够凭借控制 GPU 芯片出口这一手段,精准地调控全球 AI 生产力的水平。同时,它将全球获取 AI 算力划分成三个等级圈,并由自己来掌控分配,这使得其他国家陷入了绝望的境地。
特朗普投资了 5000 亿美元的“星际之门”。其目的是要将 AI 领先牢牢掌控在美国本土。他想吸引日韩、中东、欧洲等相关资金。他要把除中国外的其他实力国家牢牢捆绑在老美的 AI 战车上。
DeepSeek 打破了这种主导局面,让其他所有国家看到了自主发展 AI 的希望。它在实现与 OpenAI 模型同等性能时,只需对方 5%的算力,凭借低成本模式直接颠覆了美国的一众科技巨头,这使得所有国家都觉得自己有能力去发展 AI 了。这意味着所有国家都无需再依赖美国的高算力 GPU 芯片资源。同时,还能够使成本大幅度降低下来。

特朗普特别看重现在到处搞钱的这种能力,DeepSeek 突然出现后,英伟达、AMD 等企业很快就接入了,并且特朗普也一反常态地点赞,他们的意思就是能省成本,包括社会总成本,能给整个国家省下很多钱。
现在 AI 大模型发展到了一定阶段,实际上已经很难确切地分出模型能力的胜负了。在大指标不断趋于相同的背景之下,开源才是关键之举。知名投资人朱啸虎曾经做出一个判断,开源模型的基础就是闭源模型的斩杀线,未来闭源模型必须要达到开源基础的两到三倍,才有能够存活下去的机会。如果成本投入是原来的十倍,性能却只提高了 20%,那么即便投资方来自硅谷,也不会接受这样的结果。
用起来到底怎么样呢?只有开源的才能进行比较充分的测试。如果不开源,别人还交钱使用,并且没有特别领先的地方,那么商业模式就很难得以成立。
有 Chatgpt 和 deepseek 取得了巨大的成功,在此情况下,grok1 和 grok2 几乎无人问津,而 grok3 单纯依靠砸钱堆砌算力来实现大火并上演反转剧情的可能性并不是很大。
如果不实行开源,马斯克投入的大量资金无法转化为实际收益,或许会将其应用到自己的机器人和 FSD 中。然而需要指出的是,当下特斯拉 FSD 用户的订阅数量并不高,但是 Grok - 3 能够提升 FSD 的竞争力。
Grok 3 是以 10 万块英伟达 H100 芯片为基础进行训练的。它每秒能够处理超过 1.5 万亿的参数。它能够实时对车载摄像头、雷达等传感器的数据进行解析。它在识别暴雨天气下道路积水深度的准确率比竞品高 37%。它可以帮助自动驾驶系统更精准地感知周边环境。
此外,Grok 3 引入了“思维链”技术。这种技术能够模拟人类逐步推理的过程。在导航时,它可以综合分析实时交通数据、充电桩的可用性以及用户的日程,从而推荐路线。在自动驾驶场景中,当面对复杂路况和交通信号时,它能够做出更合理、更安全的决策。
特斯拉若将其运用到 FSD 中,这就表明新能源车企在智驾方面的竞争会愈发激烈,对此,中国的车企必须要有足够的认知并且做好相应的准备。
deepseek 的优势在于创新的工程设计与算法优化,从而实现了超低成本。其次,开源模式的生态以及技术优化能力,将会使得未来包括美国在内的许多科研人员只能在东大的 AI 模型上进行开发。这意味着东大有望成为世界 AI 的开发中心。我们举国之力给予支持,中国的成百上千个行业都在迅速接入,推动它持续进化,与千行百业相结合并进行实践,从而产生了生产力。在未来的发展潜力方面,或许不是 Grok3 所能比拟的,我们将拭目以待。
