DeepSeek 在春节前夕迅速走红,到现在热度依然没有降低。DeepSeek 完全走上了开源的道路,它的大模型不仅性能十分出色,而且训练成本和使用成本都非常低,这使得人工智能从业者心中燃起了“我也可以做到”的希望,也让各个行业都燃起了“赶快把人工智能运用起来吧”的热情。
这些振奋人心的消息相伴而来,同时也有一些说法在流传,这些说法真假难辨。比如,DeepSeek颠覆了人工智能的发展方向,且其水平已超过人工智能行业的领头羊 OpenAI;又或者,DeepSeek 是个巨大泡沫,只是“蒸馏”了 OpenAI 的模型。
这些天我研读了很多资料,目的是搞清楚这些说法。同时,我还请教了一些专家。通过这些,我对 DeepSeek 究竟创新了什么以及能否持续创新有了初步的答案。
DeepSeek 的大模型采用了高效的模型架构方法、训练框架和算法,这是一项巨大的工程创新。然而,它并非是从 0 到 1 的颠覆式创新。DeepSeek 没有改变人工智能行业的发展方向,却极大地加快了人工智能的发展速度。
为何会得出这个结论?我们需要先了解人工智能技术的发展脉络。
人工智能简史
人工智能起始于上世纪 40 年代,至今已历经近 80 年的发展。其奠基人是英国的计算机科学家艾伦·图林(Alan Turing)。以他的名字命名的图林奖,在计算机科学界享有如同诺贝尔奖般的地位。
如今,大模型技术主导着人工智能行业,生成式 AI 主导着应用,包括生成语义、语音、图像、视频。DeepSeek 系列、OpenAI 的 GPT 系列、豆包、Kimi、通义千问、文心一言都属于大模型家族。
大模型的理论基础为神经网络,神经网络是一种力图让计算机模仿人脑进行工作的理论。该理论与人工智能同时开始,但在最初的 40 年里都未成为主流。到了 20 世纪 80 年代中后期,多层感知机模型和反向传播算法得以完善,神经网络理论这才拥有了施展才能的地方。有多人对某事物作出了关键贡献。在这些人中,最为我们所熟悉的是杰弗里・辛顿(Geoffrey Hinton),他在去年获得了诺贝尔物理学奖,并且拥有英国和加拿大双重国籍。
神经网络理论后来演变成了深度学习理论。其中,除了被誉为“深度学习之父”的杰弗里・辛顿之外,还有法国人杨·勒昆(Yann LeCun,中文名杨立昆)以及德国人尤尔根・施密德胡伯(jürgen schmidhuber)这两位关键贡献者。他们提出了深度信念网络(DBN,2006),这是一种模型架构方法;他们完善了卷积神经网络(CNN,1998),这也是一种模型架构方法;他们还提出了循环神经网络(RNN,1997),同样是一种模型架构方法。通过这些,使得基于多层神经网络的机器深度学习得以实现。
但到目前为止,处于小模型时代。DBN 和 RNN 的参数量一般是几万到几百万。CNN 的参数量最大,也仅仅只有几亿。所以它们只能完成特定的任务。例如基于 CNN 架构的谷歌 AlphaGo,战胜了顶尖的人类围棋手柯洁和李世石,然而它除了下围棋之外,其他什么都不会。
2014 年,谷歌 DeepMind 团队开发了 AlphaGo。该团队首次提出了“注意力机制”。同年年底,蒙特利尔大学教授约书亚·本吉奥(Yoshua Bengio)以及他的两名博士生发表了一篇更详尽的论文。这篇论文是神经网络理论的重大进步,它极大地增强了建模能力,提高了计算效率,使得大规模处理复杂任务得以实现。
杰弗里・辛顿获得了 2019 年的图林奖。
2017 年,谷歌提出了一种架构,这种架构完全基于注意力机制。此架构开启了大模型时代。到目前为止,包括 DeepSeek 在内的主流大模型都采用了这种架构。强化学习理论(Reinforcement Learning)和混合专家模型(Mixture of Experts,又译稀疏模型)是大模型的关键支撑。这些相关理论在上世纪 90 年代就已提出,在 21 世纪 10 年代后期,谷歌率先将其用于产品开发。
澄清一个普遍误解,MOE 不是与 Transformer 并列的另一种模型架构方法,它是用于优化 Transformer 架构的一种方法。
今天的主流大模型,参数量已经达到了万亿级规模。其中,DeepSeek V3 的参数量是 6710 亿。这样规模巨大的模型,对算力有着惊人的需求。而英伟达的 GPU 芯片恰好能够提供算力支持。英伟达在 AI 芯片领域处于垄断地位,这使得它成为了全球市值最高的公司,同时也让它成为了中国 AI 公司的一个痛点。
谷歌在大模型时代处于领先地位。然而,近些年来,站在风口上的并非谷歌,而是 2015 年成立的 OpenAI。OpenAI 的各类大模型一直被视为业界的顶尖水平,各路追赶者都以其为标准进行对标。这表明在人工智能领域,那些看似不可动摇的巨头,实际上并非无法被挑战。人工智能技术发展了 80 年,但其真正加速是在最近十几年,进入爆发期则是最近两三年,后来者一直有机会。DeepSeek 公司于 2023 年 7 月成立,它的母体幻方量化成立于 2016 年 2 月,比 OpenAI 年轻。人工智能是一个英雄出少年的行业。
开发出通用人工智能系统(Artificial General Intelligence,AGI),使其能够像人一样自主思考、自主学习并自主解决新问题,这是 AI 业界的终极目标。奥特曼和梁文峰都将此视为自己的使命,并且他们都选择了大模型方向,而大模型方向也是业界的主流方向。
沿着大模型的方向发展,实现 AGI 需要多久呢?乐观的估计是 3 到 5 年,保守的估计是 5 到 10 年。这意味着业界认为最晚到 2035 年,AGI 就能够实现。
大模型的竞争具有重要意义。大模型处于各行各业人工智能应用的最上游位置。它如同人的大脑一般,大脑能够指挥四肢。大脑的质量会对整个人的学习、工作、生活质量产生决定作用。
大模型不是通往 AGI 的唯一途径。上世纪 90 年代后,“深度学习 - 大模型”路线颠覆了人工智能前几十年的“规则系统 - 专家系统”路线,而“深度学习 - 大模型”路线也有被颠覆的可能,只是目前我们无法得知谁会是颠覆者。
DeepSeek创新了什么?
如今,DeepSeek 成为了挑战者。它真的超越了 OpenAI 吗?并非如此。DeepSeek 在局部上超过了 OpenAI 的水平,然而整体来看,OpenAI 依然处于领先地位。
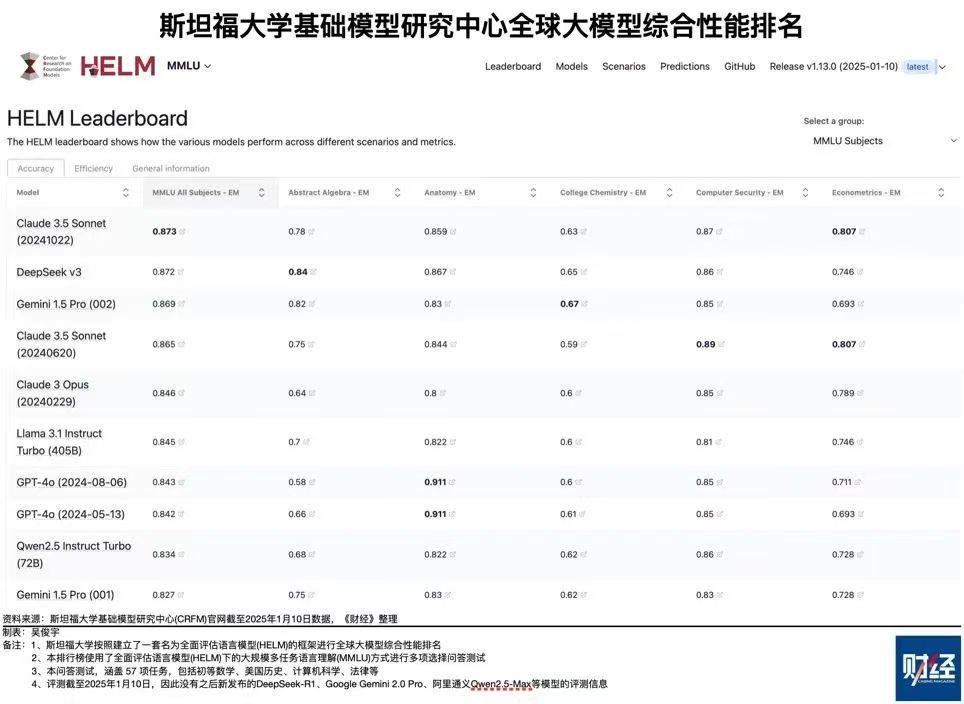
首先来看双方的基础大模型,OpenAI 所发布的是 2024 年 5 月的 GPT4-o 。其次,DeepSeek 发布的时间是 2024 年 12 月 26 日,其版本为 V3 。斯坦福大学基础模型研究中心存在一个全球大模型综合排名。这个排名是在今年 1 月 10 日得出的。该排名一共有六个指标。将各指标得分加总后,DeepSeek V3 的总分为 4.835,在排名中名列第一。而 GPT4-o(5 月版)的总分是 4.567,仅在排名中列第六。第二名是 Claude 3.5 Sonnet,它是美国模型,总分 4.819。开发这个模型的 Anthropic 公司在 2021 年 2 月才成立,且第二到第五名均为美国模型。
推理模型是大模型的新发展方向。它的思维模式更像人。前面已经提到,开发出能像人一样自主思考、自主学习、自主解决新问题的通用人工智能,这是 AI 业界的终极目标。
2024 年 9 月 12 日,OpenAI 推出了世界上首个推理大模型猎户座 1 号(orion1 ,o1)。o1 在处理数学、编程以及科学问题方面的能力有了显著提升。然而,OpenAI 采取了闭源的路线,既不公布技术原理,也不透露技术细节。在这种情况下,如何复刻 o1 便成为了全世界 AI 从业者所追求的目标。
今年 1 月 20 日,仅仅过了四个月。DeepSeek 发布了世界第二款推理大模型 R1,其名字较为朴实,R 是推理(Reasoning)的缩写。测评结果表明,DeepSeek-R1 和 OpenAI-o1 的水平是一样的。然而,OpenAI 在 2024 年 12 月 20 日推出了升级版 o3,其性能比 o1 有了极大的提升。目前还没有R1和o3的直接测评对比数据。
多模态是大模型的重要发展方向。它既能生成语义,像写代码这种也属于语义范畴;又能生成语音、图像和视频。在这些方面中,视频生成是最难的,并且消耗的计算资源也是最多的。DeepSeek 在 2024 年 10 月发布了首个多模态模型 Janus。今年 1 月 28 日,发布了其升级版 Janus-Pro-7B。该模型的图像生成能力在测试中表现很出色。然而,其视频能力如何目前还不得而知。GPT-4 是多模态模型,但它不能生成视频。不过,OpenAI 拥有专门的视频生成模型 Sora。
模型做小做精且少消耗计算资源是另一个业界趋势,混合专家模型的设计思路旨在达到此目的,推理模型也能降低通用大模型的惊人消耗。在这方面,DeepSeek的表现比 OpenAI 好很多,这些天人们谈论最多的是 DeepSeek 的模型训练成本仅为 OpenAI 的 1/10,使用成本仅为 1/30。DeepSeek 能达到如此高的性价比,原因在于其模型中包含杰出的工程创新。这些创新并非单点的,而是密集型的,每个环节都有杰出的创新表现。以下仅列举三例。
模型架构方面,采用了经过大为优化的 Transformer 与 MOE 相结合的架构。
这两个技术是谷歌率先提出并采用的,前面已有提及。DeepSeek 在使用这两个技术设计自己的模型时进行了巨大优化,并且首次将多头潜在注意力机制(Multi-head Latent Attention,MLA)引入模型中,这样就大大降低了算力和存储资源的消耗。
模型训练环节:FP8混合精度训练框架。
传统上,大模型训练采用 32 位浮点数(FP32)格式进行计算与存储。这种方式能确保精度,然而其计算速度较慢,且存储空间占用较大。怎样在计算成本与计算精度之间达成平衡,始终是业界面临的难题。2022 年,英伟达、Arm 和英特尔共同提出了 8 位浮点数格式(FP8)。但由于美国公司并不缺乏算力,所以该技术只是初步尝试便停止了。DeepSeek 构建了 FP8 混合精度训练框架。它会依据不同的计算任务以及数据特点,去动态地选择 FP8 或者 FP32 精度来展开计算。通过这样的方式,将训练速度提升了 50%,同时把内存占用降低了 40%。
算法环节:新的强化学习算法GRPO。
强化学习的目的在于让计算机能够在没有明确的人类编程指令的情形下,自行进行学习,并且自行完成任务,它是通向通用人工智能的一种重要方式。强化学习起初是由谷歌引领的。在训练 AlphaGo 时使用了强化学习算法。然而,OpenAI 后来居上。2015 年和 2017 年,OpenAI 接连推出了两种新算法,分别是 TRPO(Trust Region Policy Optimization,信任区域策略优化)和 PPO(Proximal Policy Optimization,近端策略优化)。DeepSeek 更是更进一步,推出了新的强化学习算法 GRPO(Group Relative Policy Optimization,组相对策略优化)。它在显著降低计算成本的同时,还提高了模型的训练效率。

GRPO 算法公式。该公式来源于 DeepSeek-R1 论文。
看到这里后,对于“DeepSeek 仅仅是‘蒸馏’了 OpenAI 模型”这一说法,你必然已经有了属于自己的判断。然而,DeepSeek 的创新是否是从 0 到 1 的颠覆式创新呢?
显然不是这样。颠覆式创新指的是开辟全新赛道的创新,或者是致使既有赛道发生彻底转向的创新。例如,汽车的发明对交通行业进行了颠覆,使得马车行业消失了;智能手机取代了功能手机,虽然没有让手机行业消失,却彻底改变了手机的发展方向。
回顾人工智能的简史,我们清晰地看到,DeepSeek 是沿着业界的主流方向在不断前行。他们进行了许多卓越的工程创新,从而使得中美 AI 之间的差距得以缩短。不过,目前他们仍处于追赶的状态。白宫人工智能顾问大卫·萨克斯(David Sacks)作出评价,称 DeepSeek - R1 让中美的差距从 6 - 12 个月缩短到了 3 - 6 个月。
萨克斯所提及的是模型的性能,然而更具重要意义的是性价比。其训练成本仅为原本的 1/10,使用成本更是仅有 1/30,这使得尖端的 AI 技术能够真正飞入寻常百姓家。在最近的两周时间里,各个行业的领军企业纷纷与 DeepSeek 大模型相连接,并部署本行业的应用,对 AI 的热情达到了前所未有的程度。
我必须再次进行提醒,大模型技术的进步速度较为迅速。不能对其阶段性的成果表现得过于乐观。并且大模型在人工智能的生态体系里处于最顶端的位置,它是所有下游应用得以存在的依托。所以,基础大模型的质量会对各行各业中人工智能应用的质量起到决定性作用。
DeepSeek能否持续创新?
在 DeepSeek 的影响下,萨姆·奥特曼于 2 月 13 日透露了 OpenAI 的发展计划。他表示在未来几周内会发布 GPT-4.5,在未来几个月内会发布 GPT-5。GPT-5 会将推理模型 o3 的功能整合进去,它是一个具备多种功能的多模态系统,包含语义、语音、可视化图像创作、搜索、深度研究等功能。奥特曼表示,以后用户无需在众多模型里进行选择。GPT-5 将会承担所有任务,达成“如同魔法般的统一智能”。倘若真如所说,那么 GPT-5 距离通用人工智能就又向前迈进了一步。
从用户的角度来看,一个模型能够解决所有需求,这肯定会带来很大的便利。就如同在早年的时候,手机仅仅只能用来打电话,那时出门你还需要携带银行卡、购物卡、交通卡等诸多物品,而现在一部智能手机就可以全部搞定。然而,在实现全部搞定的同时,所需要的计算资源也会变得高得令人惊讶。例如,iPhone16 的算力是当年功能机的几千万倍。奇迹在于,我们使用 iPhone16 时的成本比使用诺基亚 8210 时的成本更低。希望这种奇迹能在人工智能行业也发生。
美国除了 OpenAI 之外,还有很多顶尖的人工智能公司,这些公司的水平较为接近。从前面提到的斯坦福大学的排名就能够知晓,总分第一名和第十名之间的分数差异仅仅是 0.335,平均到每个指标上的差距还不到 0.06。而且,各种测评榜的排名虽然是重要的参考依据,但并不能等同于实际能力的高低。DeepSeek 认为,OpenAI 是强劲对手,Anthropic 是强劲对手,谷歌是强劲对手,meta 是强劲对手,xAI 也是强劲对手。2 月 18 日,xAI 发布了马斯克自称“地球最强 AI”的大模型 Grok - 3。这个模型训练时使用了超过 10 万块 H100 芯片。它将大模型的 scaling law 推向了极致,也就是计算和数据资源投入越多,模型效果越好。同时,也让 scaling law 的边际效益递减现象完全展现了出来。
当然,中国并非只有 DeepSeek 在进行相关工作,中国还有许多优秀的人工智能公司。实际上,在这些年里,全球的人工智能领域一直呈现出中美双峰并立的态势,只是美国的那座峰相对更高一些。
我对梁文峰和 DeepSeek 团队有信心。从他为数不多的采访可知,他既具理想主义,又脚踏实地且有敏锐商业头脑。他自身懂技术,却非技术天才,可能是像乔布斯、马斯克那样能聚集技术天才做出伟大产品的技术型企业家。
梁文峰在接受《暗涌》专访时表示:我们的核心技术岗位,大多是应届以及毕业一两年的人。我们选拔人的标准一直以来都是热爱与好奇心。在招人时要确保价值观保持一致,接着通过企业文化来保证步调一致。
最重要的是投身于全球创新的浪潮之中。在过去三十多年的 IT 浪潮期间,我们基本上未曾参与到真正的技术创新当中。大多数中国公司习惯于追随,而非进行创新。中国的 AI 与美国真正的差距在于原创与模仿。倘若这种状况不发生改变,那么中国永远只能充当追随者。
创新首先关乎信念。为何硅谷具备如此强的创新精神呢?首先在于敢于尝试。我们正在从事最为艰难的工作。对于顶级人才而言,最具吸引力的必然是去攻克世界上最为困难的问题。
乔布斯曾有一句名言,那就是只有那些疯狂到以为自己能够改变世界的人,才真的有可能改变世界。在梁文峰的身上,我察觉到了这句名言所蕴含的那种特质。
但是,我们绝不能对中国 AI 超越美国盲目乐观。DeepSeek 并未颠覆算力算法数据三要素的大模型发展路径。DeepSeek 的许多创新是由于芯片受限而产生的,比如英伟达 H100 的通信带宽为每秒 900GB,而 H800 仅为每秒 400GB,但 DeepSeek 只能使用 H800 来训练模型。
这些天我看了很多太平洋两岸关于 DeepSeek 的评论。有一句源自古希腊的谚语,即“necessity is the mother of invention(迫不得已是创新之母)”,不同的牛人多次提到了这句谚语。但是从另一个角度思考,DeepSeek 能够与 OpenAI 的同款产品取得平局的结果,是凭借通过逼迫而获得的算法优势来弥补自身在算力方面的劣势。然而,其对手已经被唤醒,如果他们研发出同样优秀的算法,并且再加上更优良的芯片,那么中美大模型之间的差距是否会再次增大呢?
一方面,DeepSeek 能够适配国产芯片。然而,鉴于性能方面存在差距,算力的劣势在短期内无法得到解决。只有我们能够再次创造出电动车反转燃油车那样的局面,实现换道超车,例如,用量子芯片来替代硅基芯片。
陷入这种思考是一个悲剧。技术创新原本应该造福全人类,然而却被地缘政治因素给扭曲了。因此,我们更应该为 DeepSeek 坚决走开源路线而鼓掌。

海量资讯、精准解读,尽在新浪财经APP
