Magma架构简单介绍
Magma 实现多模态能力的关键在于其采用了视觉与大语言模型的混合架构。其中,视觉模块运用了 ConvNeXt,它能够把输入的图像以及视频数据编码成一系列离散的 tokens。
这些标记把视觉信息的核心特征给捕捉住了,其中包含物体的形状、颜色、位置以及它们相互之间的空间关系。在进行编码的时候,ConvNeXt不但会留意单个图像帧的内容,而且还能够对视频里的时间序列信息进行处理,这样就能给模型提供充足的视觉上下文。

在处理高分辨率的 UI 截图时,ConvNeXt 可以精准地捕捉到界面上的每一个细节,像那些微小的图标以及复杂的布局都能被它捕捉到;
处理动态视频时,能够连贯地对画面中的物体运动和场景变化进行跟踪,还能生成有序的标记序列,从而为后续的处理提供坚实的基础。
这些编码后的视觉标记会被输入到一个仅解码器的大语言模型中,同时输入的还有编码任务描述的语言标记。接着,会将视觉标记和语言标记进行结合,从而生成统一的、语义丰富的表示。这样一来,模型就能够理解用户的需求,并将其与视觉场景联系起来。
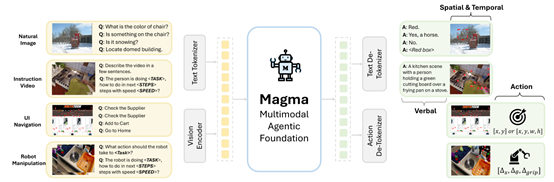
Magma 模型的自回归解码过程是实现从多模态理解到行动转化的关键机制。在解码阶段,模型依据输入的视觉和语言标记序列,逐步产出输出。此过程具有自回归性,模型在生成每个输出标记时,都会将之前已生成的内容纳入考量,从而使模型能够依据输入信息的复杂程度,灵活地调整输出,生成合理的动作指令或答案。
在一个机器人操作任务里,用户或许会让模型去“拿起桌子上的红色苹果并把它放入篮子中”。Magma 模型首先利用视觉编码器来处理输入的图像或者视频,从而识别出红色苹果所处的位置以及篮子的位置。
语言模型先将这些视觉信息进行处理,接着把处理后的视觉信息与任务描述中的语言指令相融合,最终生成一个包含动作序列的输出。
SoM与ToM
Set-of-Mark(SoM)主要是为 Magma 的行动定位而服务的。它的作用是把视觉对象标记成能够进行操作的点或者区域,以此来协助模型明确在图像或视频里需要执行操作的具体位置。
SoM 技术会在图像中对可操作对象标注边界框,同时为每个边界框分配一个独特的标记。这些标记不但有助于模型识别对象的位置,还能提供关于对象的语义方面的信息。

在 UI 导航任务里,模型会在网页截图里把所有能点击的按钮标记出来,并且给每个按钮都分配一个标记。要是用户让模型执行操作,模型就能依据这些标记迅速找到目标对象,然后生成对应的操作指令。
Trace-of-Mark(ToM)用于行动规划,它通过预测未来轨迹来帮助模型规划和执行复杂的动作序列。它主要利用视频数据中的时间信息,预测对象在未来时间点的位置和状态,以此为模型提供行动规划的依据。
Tom 技术会在视频里标注对象的运动轨迹,同时预测这些轨迹在未来时间点所处的位置。这些被预测出的轨迹一方面能帮助模型理解对象的运动模式,另一方面也为模型提供了关于未来行动的指引。比如在机器人操作任务中,模型会对机器人手臂的运动轨迹进行预测,进而规划出一系列动作,以便完成抓取物体的任务。
Tom 提升了模型的行动规划能力,并且增强了模型对时间信息的理解。模型通过预测未来轨迹,就能够更好地理解视频中的动态信息,进而在执行任务时更加准确且高效。

