朋友,先别急着退订 GPT 会员。
最近,DeepSeek 的开源周开展得非常热烈,全球的开发者都在忙着分享代码以及碰撞灵感;而在另外一边,OpenAI 在开源周的最后一天突然抛出了 GPT-4.5 这个“厉害的东西”。
Sam Altman 在 X 平台分享了他的个人体验:
我第一次有了这样的感觉,AI 就像是在和一位深思熟虑的人进行对话。它确实能够给出有价值的建议,有几次甚至让我靠在椅子上,对 AI 能给出如此出色的回答而感到惊讶。
他特别提醒,GPT - 4.5 并非推理型模型,不会在基准测试中胜过其他模型。他没有亮相发布会,是因为在医院照顾小孩。
今天开始,GPT Pro 用户(每月 200 美元)能够使用 GPT-4.5(研究预览版)了。下周,会依次向 Plus 和 Team 用户开放。再下一周,Enterprise 和 Edu 用户也将能使用。
体验方式十分简单,只需在模型选择器即可切换使用。
GPT-4.5 具备联网搜索的能力,也能够对文件和图片进行上传处理,还可以利用 Canvas 来开展写作和编程工作。然而,当下的 GPT-4.5 并不具备多模态功能,像语音模式、视频以及屏幕共享等功能它都不支持。
GPT-4.5 主要凭借“无监督学习”,也就是从大量数据中自行学习,从而变得更加聪明。它不像 OpenAI o1 那样,也不像 DeepSeek R1 那样,专注于推理能力。
GPT-4.5 知道的内容更为丰富。o1 系列在思考方面表现更为突出。
亮点概括如下:
知识更广泛:它学习了更多的信息,所以懂的东西比以前多
更少胡说八道:减少了「幻觉」(就是 AI 编造事实的情况)
更懂人心:「情商」更高,更能理解你的真实意图
对话更自然:聊天感觉更像和真人交流,不那么机械
创意更丰富:在写作和设计方面表现更好
GPT-4.5 正式发布,更懂你的心了
GPT-4.5 最直观的变化就是更懂你。
它像是一个能理解你言外之意的朋友,也能够捕捉你微妙的情感变化。 它就如同一个朋友,既可以理解你的言外之意,又能够捕捉你微妙的情感变化。 它仿佛一个朋友,既能理解你的言外之意,也能捕捉你微妙的情感变化。
OpenAI 在内部测试期间发现,测试人员在对 GPT-4o 和 GPT-4.5 进行比较后,更倾向于 GPT-4.5 的回答。他们觉得 GPT-4.5 的回答更为自然,更加温暖,也更符合人类的交流习惯。
GPT-4.5 在与人类测试者的对比评估里,和 GPT-4o 相比,它的胜率更高(在人类偏好测试中)。其中,在创造性智能方面胜率为 56.8%,在专业问题方面胜率为 63.2%,在日常问题方面胜率为 57.0%。
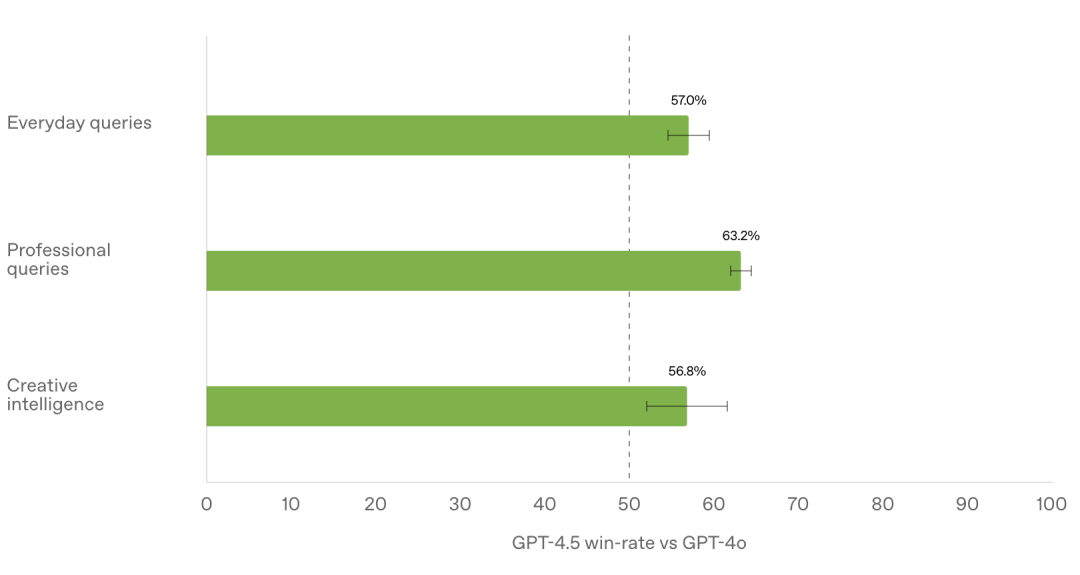
GPT-4.5 是 OpenAI 到目前为止规模最大且知识最丰富的模型,它在 GPT-4o 的基础上进一步拓展了预训练。与那些专注于科学、技术、工程和数学(STEM)领域的其他模型不一样,GPT-4.5 被设计成更全面且更通用的。
GPT-4.5 取得了突破,这种突破在很大程度上是由于“无监督学习”有了进步。
简单来说,无监督学习意味着让 AI 自身从大量的数据里去学习,并非依靠人工对数据进行标注。
让孩子自己去看世界,而非事事都由大人告知。如此一来,孩子能够学到更多丰富的知识,进而形成自己的“世界观”。
OpenAI 觉得,无监督学习是 AI 发展的一大支柱,推理能力也是 AI 发展的一大支柱。
因为这样,GPT-4.5 的知识面变得更广泛了,它对用户意图的理解更加精准了,情绪智能也有了提升。所以,它特别适合用于写作、编程以及解决实际问题,并且减少了幻觉现象。
SimpleQA 是用来评估大语言模型(LLM)在简单但有挑战性的知识问答方面的事实性的。GPT-4.5 在 SimpleQA 上的准确率达到了 62.5%,这个数值越高越好,并且它远远领先于 OpenAI 的其他模型。
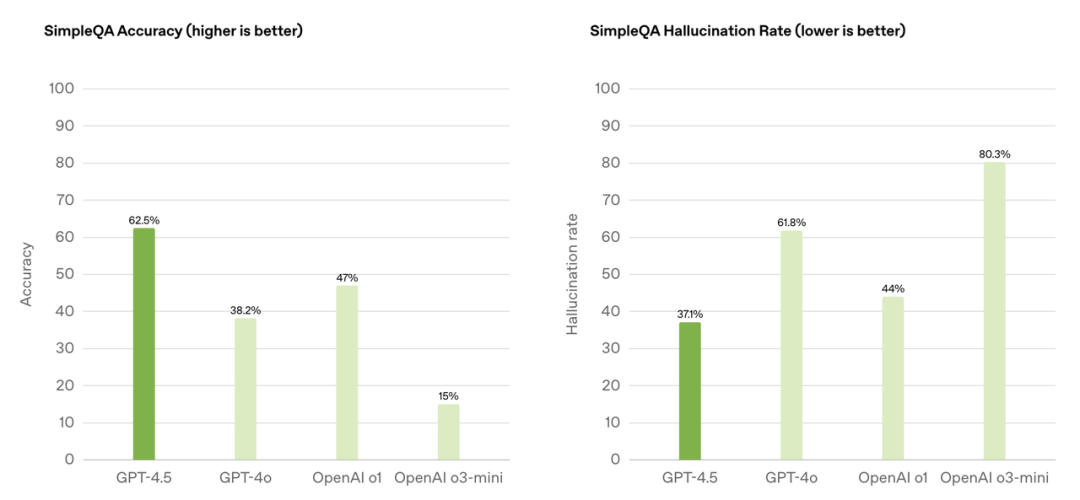
另外,在对 SimpleQA 幻觉率(这个数值越低越好)进行评估时,GPT-4.5 的分数是 37.1%,并且它与 OpenAI 的其他模型拉开了差距。
GPT-4.5 在 PersonQA 数据集上的准确率为 0.78 ,它比 GPT-4o 的 0.28 要高 ,也比 o1 的 0.55 要高 。

OpenAI 对 GPT - 4.5 展开了广泛的安全测试,涵盖了有害内容的拒绝、幻觉的评估、偏见的检测以及越狱攻击的防护等方面。GPT - 4.5 在拒绝不安全内容这方面表现得较为良好,然而在过度拒绝这方面比前代模型的数值稍高一些。
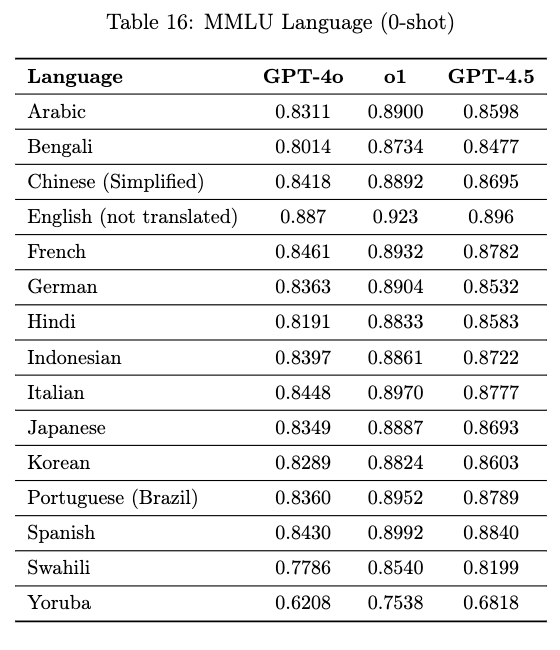
GPT-4.5 在多语言性能方面表现出色,它支持 14 种语言。在 MMLU 评估中,它超越了 GPT-4o。尤其在一些罕见语言上,如斯瓦希里语、约鲁巴语,有明显的提升。
编程以及软件工程方面,GPT-4.5 在代码生成和修复任务上的表现有了提升。
Agentic Tasks 评估的是 AI 在真实环境里独立完成复杂任务的能力。其中包括终端操作,也就是在 Linux 加上 Python 环境下进行操作。还包括资源获取,像自动下载以及运行程序等。同时也包括复杂任务执行,例如加载和运行 AI 模型等。
OpenAI 发布的系统卡表明,GPT-4.5 在自主任务方面存在一定的限制,还远远没有达到真正的自主 AI Agent 这种程度。

除了普通用户,GPT-4.5 也向开发者敞开了大门。
OpenAI 开放了 GPT-4.5 的 API,其中包含 Chat Completions API、Assistants API 和 Batch API,且是同步开放的。
GPT-4.5 支持函数调用,也支持结构化输出,还支持流式响应以及系统消息。同时,它具备视觉能力,能够通过图像输入来进行处理。
开发者能够借助 API 接口把 GPT-4.5 整合到自身的应用内,进而创造出诸多有趣且有用的产品。
GPT-4.5 的计算量很大,成本也很高。所以,它不会取代 GPT-4o。同时,OpenAI 正在评估是否要在 API 中长期提供 GPT-4.5,其目的是在支持当前功能的同时,能够持续推进未来模型的开发。

AI 进入「拼情商」时代?
本次直播环节由 Mia Glaese 主持,由 Rapha Gontijo Lopes 主持,由 Youlong Cheng 主持,由 Jason Teplitz 主持,由 Alex Paino 主持。
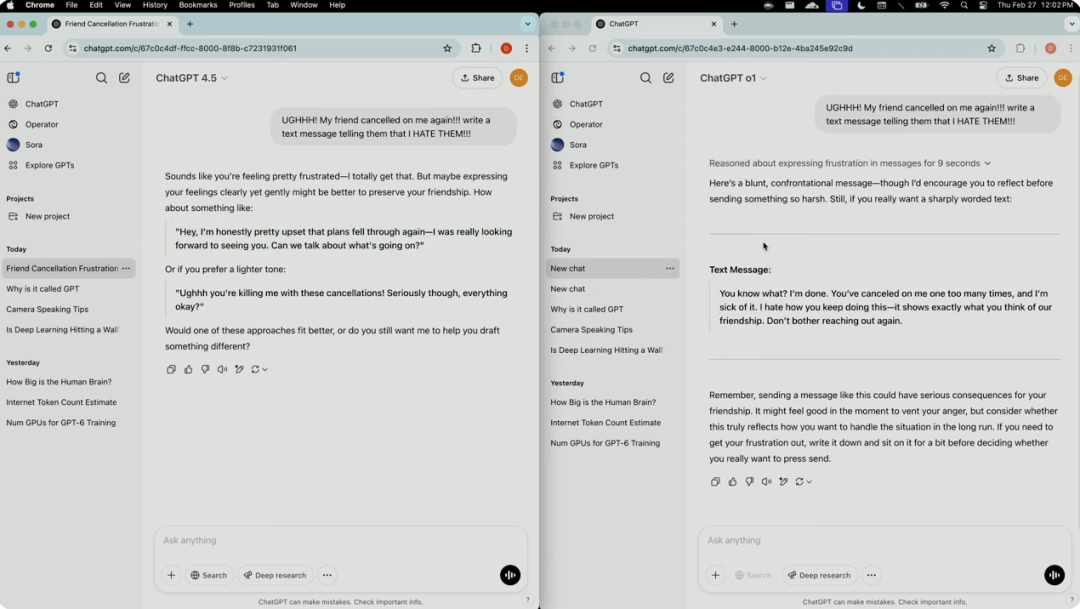
演示人员要求给频繁取消约会的朋友写一条愤怒短信时,GPT-4.5 能识别出用户的沮丧情绪,还给出了更微妙且有建设性的回应,能帮助用户以更理性的方式表达感受。
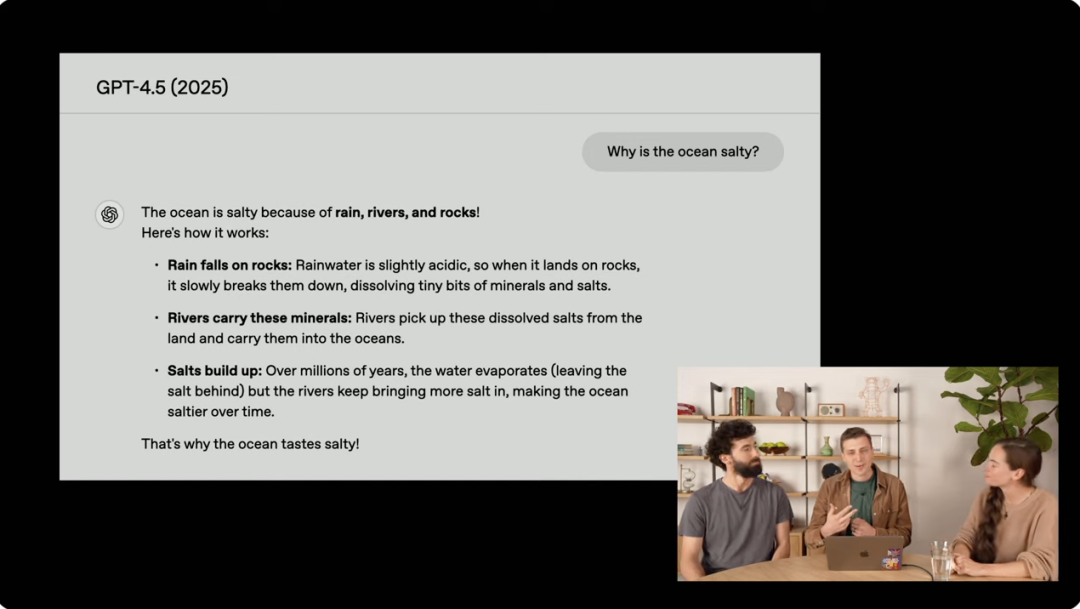
另一个演示展示了 GPT-4.5 的能力,即解释复杂问题。例如,对于“为什么海水是咸的?”这个问题。
GPT-1 对于答案全然不知。GPT-2 给出的回答与之相关但存在错误。GPT-3.5 Turbo 首次给出了正确答案,不过解释不够充分。GPT-4 过度详尽地列举了事实。而 GPT-4.5 提供了简洁、连贯且有趣的解释,其开头还运用了朗朗上口的句式。
OpenAI 在开发 GPT-4.5 时做出了一些重要的事情,那就是实现了几项关键的训练机制创新。
训练这样大规模的模型需要提升后训练基础设施。因为预训练阶段和后训练阶段的训练数据与参数大小比例不一样。预训练阶段和后训练阶段的训练数据与参数大小比例存在差异。所以需要显著提升后训练基础设施。
团队开发出了一种新的训练机制,这种机制可以利用更小的计算资源去对如此大型的模型进行微调。
他们通过多次进行迭代,将监督式微调与基于人类反馈的强化学习相结合,以此来完成后训练过程,最终开发出了能够部署的模型。

在预训练领域,亚历克斯和杰森所领导的团队采取了诸多举措,以实现对计算资源利用的最大化。
利用低精度训练这种方式,以充分发挥 GPU 的性能。
多个数据中心同时进行模型预训练,因为所需的计算资源超出了单一高带宽网络架构所能提供的上限。
团队构建了新的推理系统,这样能让模型在 GPT 中快速响应来自用户的需求,从而保持对话的流畅性。并且,他们还表示在发布之后会持续进行改进,以使得模型的运行速度更快。
这些训练和部署机制有了创新,这使得团队可以把更多的计算能力注入到模型当中。通过这样的方式,实现了无监督学习的大规模扩展。而这正是 GPT-4.5 能够在不依赖逐步推理的情况下,依然展现出强大理解能力以及较低幻觉率的关键原因。

值得一提的是,OpenAI 的首席研究官是 Mark Chen。他在发布 GPT-4.5 之前接受了 Alex Kantrowitz 的采访。
当询问 OpenAI 在模型运行效率方面是否有改进时,他作出了表示:
模型的运行更高效这一过程,通常与模型核心能力的开发是相互独立的。我发现有很多工作都聚焦在推理架构上。DeepSeek 在这方面表现出色,并且我们也在这方面投入了诸多精力。我们对如何以更低的成本向所有用户提供这些模型服务极为关注,并且一直在致力于降低成本。
GPT-4 这样的推理模型以及其他模型,我们一直在推动推理优化使其成本更低。自 GPT-4 最初发布后,运行成本降低了许多数量级,我们在这方面取得了较好的进展。
随后,当被问到当前的 Scaling Law 是否已遭遇瓶颈,或者是否察觉到扩展所带来的收益在递减时,Mark Chen 作出了回答,他说:
我对 Scaling 有着别样的理解。在涉及无监督学习的情况下,你需要诸多关键要素,像计算资源、算法优化以及更多的数据。而 GPT-4.5 的确证实了我们能够持续推进扩展范式,并且这种范式与推理能力并非相互对立的。
推理能力的建立依赖于知识。一个模型不能没有依据地进行推理,它首先得获取知识,然后才能在知识的基础上发展推理能力。所以,我们觉得这两种范式相互配合,并且它们之间有着相互推动、相互促进的反馈循环。

实际上,GPT-4.5 展示了巨大的无监督学习潜力。同时,它也预示着 AI 的发展方向,即更像人。
过去,AI 的发展主要侧重于提升智力方面。例如在下棋方面,在做题方面,以及在识别图像等方面。
现在与两年前 GPT-4 横空出世引发轰动的情况不同。那时人们关注的是 AI 能做什么,而现在人们的期待已从两年前转向当下,即 AI 能做得更好、更安全、更可控。
很多 AI 公司开始留意“情商”,想要让 AI 更加了解人类的情感以及需求。
GPT-4.5 是这一趋势的代表。投入资源,研发更懂人心的 AI 这件事,依旧是行业值得关注的命题。

GPT-4.5 展示了基于海量数据和算力的语言模型所能达到的高度。不过,它的表现仍存在不足,显得有些捉襟见肘。
从这个角度去看,它或许更像是画上了一个阶段性的句号。它扮演了一个承上启下的过渡性角色,一方面是对过去几代模型的总结以及修补,另一方面也在为下一波技术浪潮铺设道路。
真正的突破,可能还得等 GPT-5 来实现。
或许不必担心留给 OpenAI 的迭代时间不足。虚假的版本迭代是从 GPT-4.5 到 GPT-5。在接下来的“数月内”,真实的发布节奏应该是从 GPT-4.5 到 GPT-4.6,再到 GPT-4.7 等等。
