
本周开始,DeepSeek 开启了“开源周”。它每天开源一个项目,这再度引发了全球大模型的开源潮。记者留意到,与之前推理模型的开源情况不一样,在这几天,全球大模型在多模态领域展开了竞争,国产大模型还展现出了超越 Sora 的能力。
25 日晚 10 点,阿里云宣布视觉生成基座模型万相 2.1 开源。此模型采用最宽松的开源协议,有 14B 和 1.3B 两个参数规格。同时,它还支持文生视频和图生视频任务。在性能表现方面,14B 版本的万相 2.1 优势较为突出。在权威评测集 Vbench 中,其总分达到 86.22%,超越了众多国内外模型,其中包括 OpenAI Sora。值得一提的是,1.3B 版本能够在消费级显卡上运行。它仅需 8.2GB 显存,就可以生成 480P 视频。这种特性尤其适合家庭场景以及教学场景。
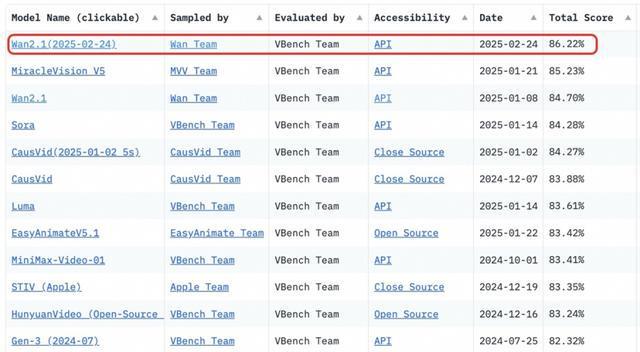
万相2.1超越Sora,位居榜单第一。
万相 2.1 开源后,阿里云达成了全模态、全尺寸大模型的开源。目前,通义大模型的衍生模型数量已超 10 万个,且它成为了全球最大的开源模型。
仅仅几个小时后,微软也放了一个大招。
26 日凌晨 3 点,微软官网将多模态智能体 Magma 进行了开源。它具备跨数字、物理世界的多模态能力,能够自动处理图像、视频、文本等不同类型的数据。同时,它还能够推测视频中人物或物体的意图以及未来的行为。
微软宣布开源Magma。
官方演示表明,Magma 与具身智能能够产生良好的协同效应。例如,用户告知 Magma 让机器人去“拿起桌子上的红色苹果并放入篮子中”,Magma 会利用视觉编码器对输入的图像或视频进行处理,从而识别出红色苹果的位置以及篮子的位置,接着调用语言模型把视觉信息和任务描述中的语言指令融合在一起,最终使机器人能够完成规定动作。
春节之后,多模态大模型呈现出开源的趋势且越来越明显。在不久之前,上海的大模型初创企业阶跃星辰对外宣布,将视频生成模型阶跃 Step-Video-T2V 进行开源,同时也将语音交互大模型阶跃 Step-Audio 进行开源。记者得知,开源已经有一周时间了。在这一周里,Step-Video-T2V吸引了海内外的创作者,这些创作者生成的视频次数超过了 13.6 万次。并且,Step-Video-T2V 已经接入了全球头部的 AI 内容创作平台 LiblibAI。
