
大语言模型(LLMs)基于逐步生成解决方案的训练范式在人工智能领域受到了广泛的关注,并且已经发展成为行业内的一种主流方法。
OpenAI 在其“12 Days of OpenAI”直播系列的第二天推出了针对O1 模型的强化微调(Reinforcement Fine-Tuning,RFT),这进一步推动了AI 定制化的发展[1]。 RFT/ReFT 的一个关键部分是进行监督微调时使用思维链注释。在DeepSeek-R1 模型中,引入了少量长的思维链冷启动数据,目的是调整模型作为初始强化学习的代理。
然而,要全面理解采用CoT 训练的策略,就需要解决以下两个关键问题:其一,其二。
在实际训练过程中,因为涉及到众多的因素,所以在分析显式CoT 训练的优势以及其潜在机制时,面临着非常显着的挑战。基于此,我们借助清晰且能够控制的数据分布,进行了细致的分析,并且揭示出了以下这些有趣的现象:
与无CoT 训练相比,CoT 训练对推理泛化能力有显着增强作用。它把推理泛化能力从仅适用于分布内(in-distribution, ID)场景,扩展到了ID 和分布外(out-of-distribution, OOD)场景,这表明了具有系统性泛化能力。并且,CoT 训练还加速了收敛速度,如图1 所示。
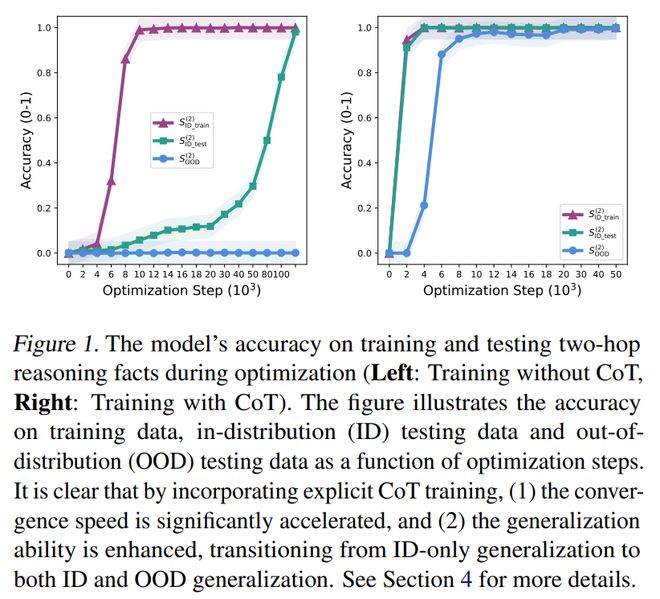
图表1 展示了模型在优化过程中针对训练两跳推理事实的准确率以及针对测试两跳推理事实的准确率。
(ii)CoT 训练即便包含一定范围的错误推理步骤,却仍能让模型学习推理模式,进而实现系统性泛化,就像图4 和图5 所展示的那样。这意味着数据质量比方法本身更为关键。训练的主要瓶颈在于收集复杂的长CoT 解决方案,而推理步骤中存在少量错误是能够被接受的。
数据分布的关键因素,比如比例λ以及模式,在形成模型的系统性泛化方面起着决定性的作用。这意味着在CoT 训练中,仅仅接触过两跳数据的模型无法直接泛化到三跳的情况,该模型需要接触过相关的模式。
通过logit 透镜和因果追踪实验,我们得知CoT 训练(基于两跳事实)会把推理步骤融入到模型里,从而构建出一个两阶段的泛化电路。并且推理电路的阶段数量与训练过程中那些显式的推理步骤的数量是相契合的。
我们将分析进一步扩展到训练数据分布上,这些训练数据在推理过程中存在错误。并且验证了这些见解在现实数据上对于更复杂的架构依然是有效的。
我们所知的是,我们的研究首次在可控制的实验里对CoT 训练的优势进行了探索,并且还提供了基于电路的CoT 训练机制的解释。这些发现为CoT 以及LLMs 实现稳健泛化的调优策略给出了宝贵的见解。

一、预备知识与定义
本部分介绍研究使用的符号定义,具体如下:
原子与多跳事实:研究采用三元组来对原子(一跳)事实进行表示。同时,依据原子事实以及连接规则,来对两跳事实以及多跳事实进行表示。





二、系统性组合泛化
本研究主要关注模型的组合能力,也就是模型要把不同的事实片段连接起来的能力。虽然显式的推理步骤表述,像思维链推理等,能够让任务表现得到提升[4-8],然而这些方法在大规模(预)训练阶段是不可行的,而这个阶段恰恰是模型核心能力形成的重要时期[9-10]。已有研究广泛探讨了基于Transformer 的语言模型是否能够执行隐式组合,且均得出了否定结论[11-12]。
具体来说,存在明显的“组合性鸿沟”[11]。模型虽然拥有所有的基础事实,但是却不能够进行有效的组合。这种现象在不同的大语言模型里都普遍存在,并且不会因为模型规模的扩大而有所减弱。
Wang 等人[13] 的研究表明,Transformer 模型在同分布泛化方面能够学习隐式推理。然而,在跨分布泛化中,它的表现不佳,如图1 左所示。
这自然引出一个问题:在训练过程中使用显式推理步骤时,模型的泛化能力会受到怎样的影响? (也就是要回答Q1:和无思维链训练相比,基于思维链的训练具备哪些优势?)
思维链训练显着提升推理泛化能力
我们展示了模型在训练和测试两跳事实上的准确率随优化过程的变化,如图1 所示,并且其中的λ等于7.2。


关键影响因素探究
研究开展了消融实验,目的是评估不同因素在思维链训练中的影响。
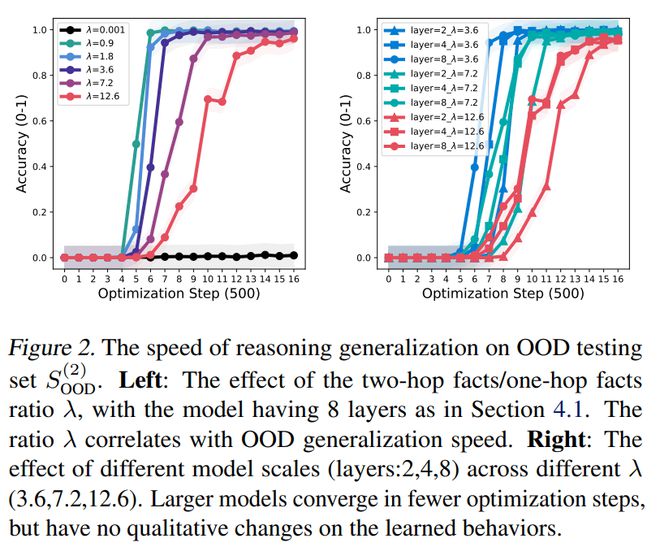
图表2: 分布外测试集上的推理泛化速度。
适当的λ值有加速模型收敛的作用。图2(左)把不同λ值下的分布外测试准确率展示了出来。能够看出,λ值和泛化速度之间有强相关性。更有意思的是,较小的λ值能加速由思维链训练所带来的分布外泛化能力的提升,这样就能减少对长时间训练的需求。不过,λ值不是越小就越好,因为如果λ值过小,可能会使模型无法学习相关规则。
不同模型规模、层数以及训练集大小会产生影响。我们开展实验时,模型层数处于{2,4,8}之中,λ处于{3.6,7.2,12.6}范围内。总体来看,能够发现扩大模型规模并不会从本质上对其泛化行为进行改变,主要的趋势是较大的模型能够在更少量的优化步骤中完成收敛。我们的结果在训练集大小(|E|)的影响方面与[13] 一致。当把λ 值固定下来后,训练集大小不会对模型的泛化能力造成本质性的影响。
两跳到多跳分析


总结:在此,我们已证明在受控实验里引入显式思维链训练,能够让推理泛化能力得到显着提升。这种提升使得推理泛化能力从仅局限于分布内泛化,扩展到既能涵盖分布内泛化,又能涵盖分布外泛化。数据分布的关键因素,像比例和模式等,在塑造模型的系统性泛化能力方面起着重要的作用。然而,这些改进的驱动内部机制尚不明确。我们会进一步展开探讨,以回答Q2 的问题,即如果存在优势,显式思维链训练的潜在机制是什么。
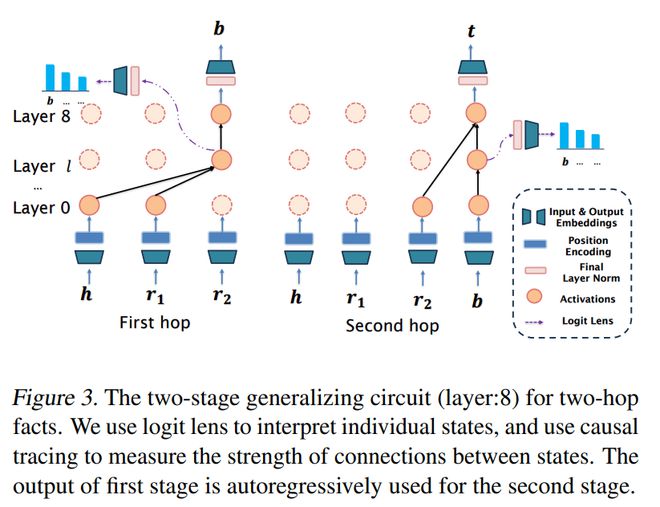
图表3 展示了两跳事实训练所对应的两阶段泛化电路,该电路的模型层数为8。
三、两阶段泛化电路
研究用两种主流方法来分析模型在泛化过程中的内部工作机制,这两种方法分别是logit lens [16] 和causal tracing [17],本部分研究采用的是表示两跳推理。


系统性泛化解释
两阶段泛化电路显示,运用思维链训练能够把推理步骤融入到模型里。这也就说明了模型在思维链训练的情况下,为何能够在跨分布测试数据上展现出良好的泛化能力。
该电路由两个阶段构成,这与训练期间模型里的显式推理步骤是相符合的。所以,当模型在思维链训练期间仅仅接触两跳数据的时候,在测试阶段是无法直接推广到三跳场景的。
四、更普适的分析
总体而言,目前的研究为通过思维链训练在受控数据分布上深入理解和增强Transformer 的泛化能力开辟了道路。然而,现实世界中的训练数据分布通常更为复杂。在本部分,我们会将分析扩展到推理过程中存在错误的分布,并且展示思维链训练能提高模型泛化能力这一结论在更复杂的场景中依然成立。
数据分布带噪
我们的目标是分析在噪声训练数据环境下,通过思维链训练所获得的系统性泛化能力的稳健性。我们通过随机挑选一个有效实体,向其引入噪声(真实训练目标为)。

需要注意的是,用ξ 来表示噪声比例。我们将会探讨不同的ξ 值所带来的影响。
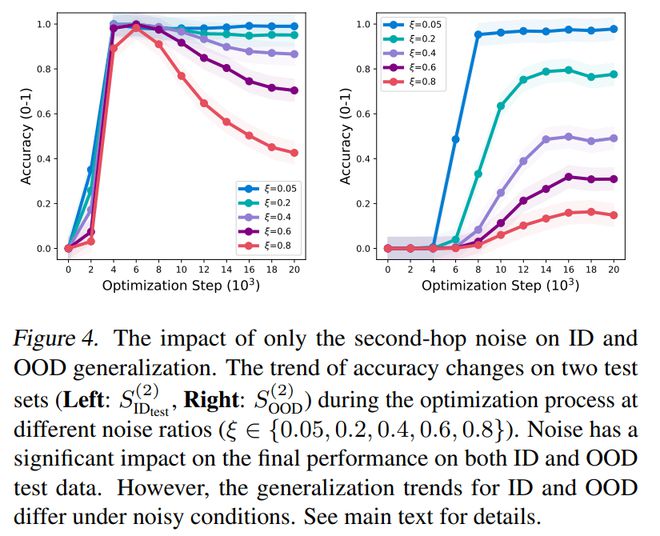
图表4: 仅第二跳噪声对分布内和分布外的影响。
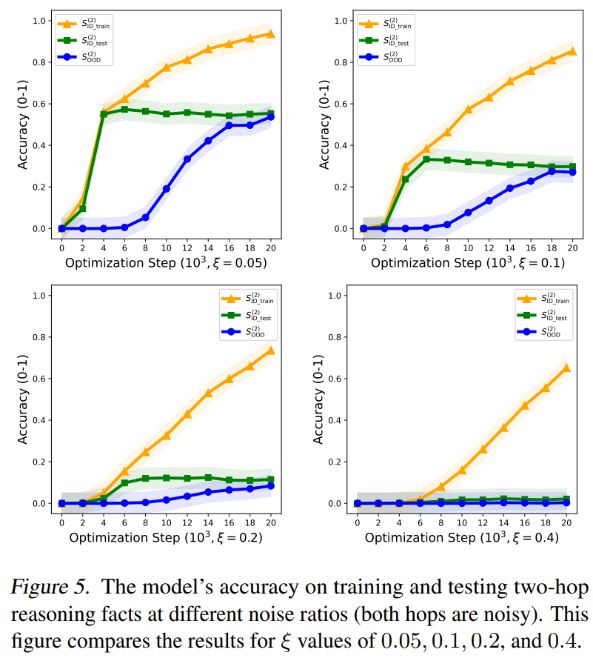
图表5 展示了模型在两跳均有噪声的不同噪声比例情况下,对训练和测试两跳推理事实的准确率。
我们对两种情况分别进行了分析。一种情况是仅第二跳有噪声,其对应的ξ(噪声比例)候选集为{0.05, 0.2, 0.4, 0.6, 0.8};另一种情况是两跳均有噪声,对应的ξ(噪声比例)候选集为{0.05, 0.1, 0.2, 0.4}。比较的结果如下:
图4 把仅第二跳噪声对分布内和分布外泛化的影响清晰地展示了出来。整体来看,在思维链训练的条件下,模型依然能够从噪声训练数据里实现系统性的泛化,不过它的泛化能力会随着噪声比例的上升而降低。
具体而言,在训练的过程中,分布外泛化起初是保持不变的状态,接着开始增加;而分布内泛化先是增加,随后又减少。分布内泛化的减少这一情况,与分布外泛化的增加是相对应的。
然而,噪声比例一旦增加,分布内的泛化最终性能会下降,分布外的泛化最终性能也会下降。尤其当噪声比例为(ξ 时,这种情况更为明显。< 0.2)相对较小时,模型几乎不受影响,这展示了思维链训练的鲁棒性。
我们检查了泛化电路。我们只在第二跳添加噪声,所以第一跳阶段的电路学习得比较好,而第二跳阶段的电路受噪声影响更大。
图5 展示了不同两跳噪声ξ 值(0.05、0.1、0.2 和0.4)时的结果对比。仅在第二跳添加噪声与在两跳都添加噪声进行比较,发现两跳都添加噪声对模型泛化的抑制效果更明显。噪声比例大于0.2 时,几乎能够消除分布内和分布外的泛化能力。
总之,即便训练数据存在噪声,但若噪声处于一定范围内,思维链训练能够让模型实现系统性泛化。尤其在噪声比例较小的时候,这些噪声数据还能助力模型学习泛化电路。

五、讨论
总结
本文在受控且可解释的环境里展示了系统性组合泛化怎样通过显式思维链(CoT)训练在Transformer 中得以产生,从而揭示了思维链训练的核心机制。具体来说:
思维链训练与无思维链训练相比,显着增强了推理泛化能力。它不仅能在分布内(ID)场景中进行泛化,还能同时涵盖分布内和分布外(OOD)场景。
我们通过logit lens 和causal tracing 实验得知,思维链训练(利用两跳事实)把推理步骤融入到了Transformer 里,从而构建出了一个两阶段泛化电路。但是,模型的推理能力会受到训练数据复杂性的制约,原因在于它难以将两跳的情况推广到三跳的情况。这表明思维链推理主要是重现了训练集中存在的推理模式。
我们把分析进一步扩展到推理过程中存在错误的训练数据分布这方面。证明在噪声保持在一定范围内的情况下,思维链训练能够让模型实现系统性泛化。此类噪声数据的结构或许对泛化电路的形成是有帮助的。
有趣的是,我们的工作突出了思维链训练的瓶颈所在,即训练数据的分布(包括比例λ和模式等方面)在引导模型实现泛化电路的过程中起着关键作用。并且模型在训练过程中需要接触过相关的模式,特别是思维链步骤的数量这一方面。
这或许解释了为何DeepSeek-R1 [4] 在冷启动阶段会构建并收集少量的长思维链数据,用以对模型进行微调。我们的这些发现为调整大语言模型(LLMs)从而达成稳健泛化的策略给出了关键的见解。
不足与未来展望
我们的自下而上研究为实际应用提供了宝贵见解,然而,我们工作存在一个关键局限,即实验和分析是以合成数据为基础的,这种合成数据或许无法完全捕捉现实世界数据集和任务的复杂性。我们的一些结论在Llama2-7B [18] 等模型中得到了验证。然而,有必要在更广泛的模型上展开进一步验证,这样才能弥合我们的理论理解与实际应用之间的差距。
我们的分析当前只局限于运用自然语言。之后,我们的目标是去探寻大型语言模型在没有限制的潜在空间里的推理潜能,尤其要通过像训练大型语言模型在连续潜在空间中进行推理这样的一些方法[19]。
最近有一种方法叫“backward lens”[20],它把语言模型的梯度投影到词汇空间,从而能够捕捉到反向信息流。这给我们完善思维链训练的潜在机制分析带来了一个新的视角。
作者介绍
并且他是国家级高层次青年人才。从事机器学习基础理论研究时间较长,发表的论文有100 余篇。其中,以第一作者或通讯作者身份发表的顶级期刊和会议论文接近50 篇。这些论文涵盖了机器学习领域的顶级期刊JMLR、IEEE TPAMI、Artificial Intelligence 以及顶级会议ICML、NeurIPS 等。获有中国人民大学的「杰出学者」称号,是中国科学院「青年创新促进会」的成员,还获得了中国科学院信息工程研究所的「引进优青」等称号。主持了国家自然科学面上/ 基金青年项目,主持了北京市面上项目,主持了中科院基础前沿科学研究计划,主持了腾讯犀牛鸟基金,主持了CCF - 华为胡杨林基金等项目。
姚鑫浩是中国人民大学高瓴人工智能学院的博士研究生,他本科毕业也来自中国人民大学高瓴人工智能学院。目前他主要的研究方向包含大模型推理以及机器学习理论。
参考文献
OpenAI. 有12 天的时间属于OpenAI. 12 天的时间,在2024 年a 月。
Trung、L、Zhang、X、Jie、Z、Sun、P、Jin、X 和Li、H 提出了ReFT:通过强化微调进行推理。在Ku、L.-W.、Martins、A. 和Srikumar、V.(编着)的《第62 届计算语言学协会年会论文集(第1 卷:长篇论文)》中,该研究发表于第7601 至7614 页,时间为2024 年。
Wei 等人Chain of thought prompting 在大型语言模型中引发了推理。 2022 年在Advances in Neural Information Processing Systems 中。 Wang X、Schuurmans D、Bosma M、brian ichter、Xia F、Chi EH、Le QV 和Zhou D 参与其中。
DeepSeek-AI 以及Guo、D、Yang、D、Zhang、H 等人。 Deepseek-r1:在2025 年通过强化学习激发大型语言模型的推理能力。 URL
Lake 和Baroni 在2018 年的国际机器学习会议论文集中发表了一篇论文。该论文题为“Generalization without systematicity: On the compositional skills of sequence-to-sequence recurrent networks”,其页码为2873 至2882 页。
Zelikman、E、Wu、Y、Mu、J 和Goodman、N 提出了STar,即通过推理来引导推理。该成果发表于2022 年的《神经信息处理系统进展》中。
Liu 等人在2023 年自然语言处理经验方法会议的论文中提出Crystal,这是一种通过自我反馈强化的自省推理器;J、Pasunuru、Hajishirzi、Choi 和Celikyilmaz 参与了该研究;该研究成果发表在会议论文集的第11557 至11572 页。
Zhou 等人在2023a 年的《神经信息处理系统进展》中指出,Lima 表明少即是多用于对齐。其中有C 的Zhou、P 的Liu、P 的Xu、S 的Iyer、J 的Sun、Y 的Mao、X 的Ma、A 的Efrat、P 的Yu、L 的YU、S 的Zhang、G 的Ghosh、M 的Lewis、L 的Zettlemoyer 以及O 的Levy。
Press, O 等人测量并缩小了语言模型中的组合性差距。他们的研究成果发表在2023 年计算语言学协会会议(EMNLP 2023)的相关文献中,该文献的页码范围是5687 至5711 页。
Yang、Gribovskaya、Kassner、Geva 和Riedel 等人在2024 年探讨了大型语言模型是否潜在地进行多跳推理。该研究的URL 为org/abs/2402.16837。
Wang、B、Yue、X、Su、Y 和Sun、H 对Transformer 中隐式推理的理解:迈向泛化边缘的机制之旅。发表于2024 年的《神经信息处理系统进展》中。
Power 等人在2022 年发表了“Grokking: Generalization beyond overfitting on small algorithmic datasets”。该论文的作者包括Power A、Burda Y、Edwards H、Babuschkin I 和Misra V。其URL 为arxiv.org/abs/2201.02177。
Cabannes 等人进行了“Iteration head: A mechanistic study of chain-of-thought”的研究。其中包括V. Cabannes、C. Arnal、W. Bouaziz、XA Yang、F. Charton 和J. Kempe。该研究成果发表在2024 年的《Advances in Neural Information Processing Systems》中。
Nostalgebraist. Gpt 被解读为:2020 年的对数透镜。
Pearl 所著的《Causality: Models, Reasoning, and Inference》由Cambridge University Press 在Cambridge 出版,出版时间为2009 年,其ISBN 为9780521426085.
Touvron、H 等人。 Llama 是开放且高效的基础语言模型。该研究成果发表在2023 年的arXiv 预印本arXiv:2302.13971 中。
Hao、S 等人在2024 年进行了训练大型语言模型以在连续潜在空间中进行推理的工作。该工作于2024b 年完成,其URL 为arxiv.org/abs/2412.06769. 。其中参与的人员有Sukhbaatar、S ,Su、D ,Li、X ,Hu、Z ,Weston、J 以及Tian、Y 。
Katz、S、Belinkov、Y、Geva、M 和Wolf、L 提出了向后镜头:将语言模型梯度投影到词汇空间中。该成果发表于2024 年自然语言处理经验方法会议的论文集中,页码为2390 - 2422 。
