TOKENSWIFT团队 投稿
量子位 | 公众号 QbitAI
大语言模型长序列文本生成效率新突破——
传统自回归模型生成 10 万 Token 的文本需要将近 5 个小时。现在生成 10 万 Token 的文本仅需 90 分钟。
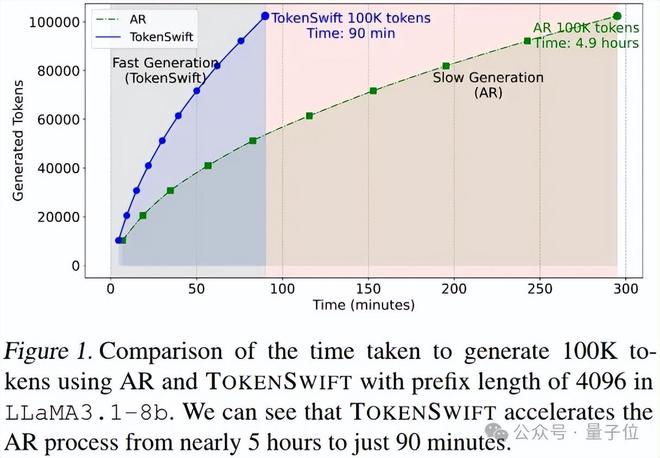
最新研究提出了一个框架名为 TOKENSWIFT,这个框架在模型加载方面进行了优化,在 KV 缓存管理方面进行了优化,在 Token 生成策略方面也进行了优化。
实验结果表明,这种方法不但可以大幅度提高生成效率,而且还能够在确保生成质量以及多样性的同时,实现没有损失的加速。
团队发布了经过微调的 DeepSeek-R1-Distill-Qwen-32B 模型,并且该模型支持 R1-Distill,同时也具备 3 倍加速效果。
来自北京通用人工智能研究院的团队完成了本研究,以下是更多的细节情况。

TOKENSWIFT框架长啥样?
LLMs 的长上下文窗口能力在不断提升,复杂任务对于超长文本生成的需求也越来越高。传统的自回归(AR)生成方式在短文本方面表现得较为良好,然而在长文本生成中却存在着明显的瓶颈,这种瓶颈主要体现在以下三个方面:
自回归生成时,每生成一个 Token 都需从 GPU 存储中重新加载模型权重,这样就使得 I/O 操作频繁且延迟较高。在生成 10 万 Token 的过程中,模型需要重复加载上万次,从而严重拖慢了整体生成速度。
在生成超长文本时,模型内部的键值对(KV Cache)会持续增长。如果直接使用全量的 KV 缓存,那么不但会超出内存预算,而且还会大幅度增加计算时间。怎样在确保关键信息不丢失的情况下,实现 KV 缓存的高效更新,这成为了一个很大的难题。
长序列生成容易出现重复和冗余的问题,这会对文本的多样性和质量产生影响。尽管重复问题不是论文的主要关注点,然而在超长文本生成过程中,仍然需要对其进行有效抑制。
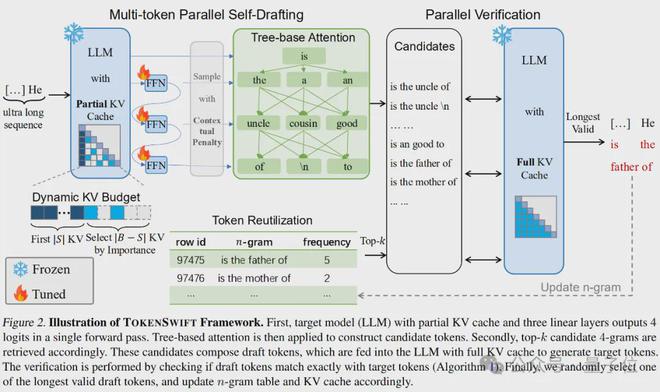
为了解决上述那些难题,论文给出了 TOKENSWIFT 这一全新的框架,该框架的目的是能够实现无损地加速超长序列的生成,它的主要创新点主要体现在如下的一些方面:
1)多Token并行生成与Token复用
论文采用了 Medusa 等方法,并且引入了额外的线性层,这样一来,模型在一次前向传播过程中就能够同时生成多个草稿 Token。
更重要的是,系统会依据生成文本中的 n-gram 频率信息,自动进行检索操作。同时,系统会复用那些高频短语。通过这些方式,能够进一步减少模型重新加载的次数,进而提升整体的效率。
2)动态KV缓存更新策略
KV缓存管理方面,TOKENSWIFT运用动态更新策略。系统在生成之际会保留初始的 KV 缓存,并且会依据 Token 的重要性来对后续的缓存进行有序的替换。
这种方式能够有效控制缓存的规模,同时确保关键信息一直被保存,从而大幅降低了因缓存加载而产生的延迟。
3)基于树结构的多候选Token验证
为了确保生成结果能和目标模型的预测保持一致,TOKENSWIFT采用了树形注意力机制。
构建一个树形结构,其中包含多个候选 Token 组合。采用并行验证的方式。从这些组合中随机挑选出最长且有效的 n-gram。将其作为最终输出。这样能确保生成过程无损,同时提升多样性。
4)上下文惩罚策略
论文为了进一步抑制重复生成问题,设计了一种上下文惩罚方法。这种方法在生成过程里,会给近期生成的 Token 施加惩罚。这样一来,模型在选择下一个 Token 时,就会更倾向于进行多样化输出,进而能够有效减少重复现象。
TOKENSWIFT效果如何?
实验部分,论文对多种模型架构进行了充分测试,这些模型架构包括 MHA 和 GQA。同时,论文也在不同规模上进行了测试,不同规模有 1.5B、7B、8B、14B。
结果表明,TOKENSWIFT 在生成 10 万 Token 长序列时,与传统自回归方法相比,平均加速达到了 3 倍以上。同时,生成结果在准确性方面和多样性方面基本没有损失。
1)加速效果
实验数据表明,在 LLaMA3.1-8B 模型的情况下,传统 AR 生成 10 万 Token 大概需要 4.9 小时,然而使用 TOKENSWIFT 之后只需要 90 分钟,这样就大大节省了时间。当是 Qwen2.5-14B 时,传统 AR 生成 10 万 Token 更是达到了 7.9 小时,经过加速之后仅仅需要 142 分钟。这一成果在实际应用中是有重要意义的。在这些场景里,需要进行实时的长文本生成,或者需要高效地生成长文本。
2)验证率与接受率
论文设计了多种指标用以评估生成质量,其中包含 Token 接受率以及 Distinct-n 指标。结果显示,TOKENSWIFT 不但在速度方面有着显著的领先优势,并且在能够保持无损生成的情况下,还可以有效地提升文本的多样性。
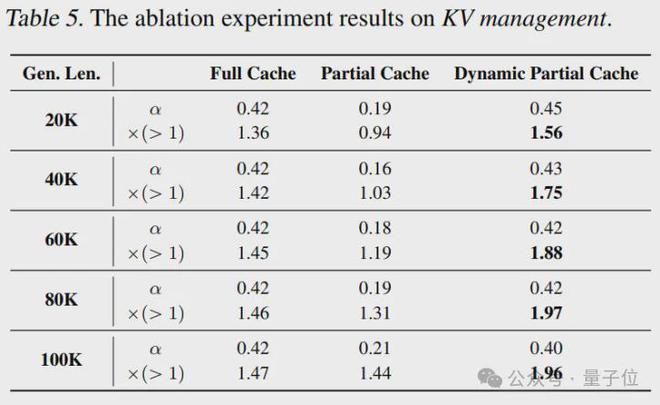
消融实验与案例分析
在对 TOKENSWIFT 的各模块贡献进行深入理解时,论文开展了全面的消融实验,同时也进行了案例分析,这些工作为优化方案提供了充足的依据。
消融实验:关键组件的作用
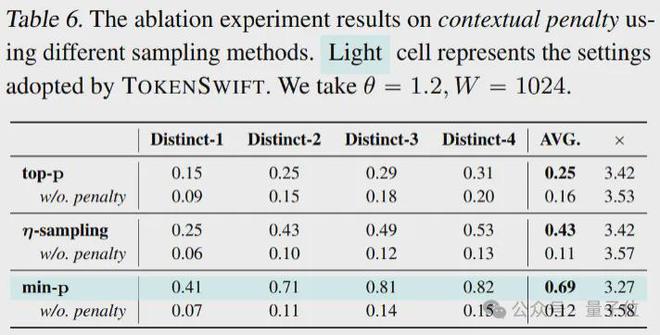
在 min-p 采样的场景当中,Distinct-n 的平均得分从 0.12 提升到了 0.69,并且仅仅带来了大概 8%的速度损失,这充分地验证了该策略在对重复生成进行抑制方面的有效性。
案例分析:真实生成对比
论文对比了在存在上下文惩罚条件时生成的文本与不存在上下文惩罚条件时生成的文本之间的差异,案例分析的结果给人留下了深刻的印象。

这些消融实验和案例分析证明了各关键技术模块的重要性,还为后续优化指明了方向,充分体现了 TOKENSWIFT 在超长文本生成领域的先进性与实用性。
Arxiv:
Github:
Blog:
