在日常生活里,你有没有碰到过这样的情形呢?一是在嘈杂的环境当中,语音助手无法听清你的指令;二是在进行视频通话的时候,对方的发音不是很清晰,致使你难以理解对方的意思。
自动语音识别(ASR)技术在持续进步。然而,在真实世界的视频场景里,ASR依旧遭遇诸多挑战,像噪声的干扰,口语化的表达,还有同音词的混淆等这些问题。
那么,人们能否利用视觉信息来增强语音识别的准确性呢?

最近,中国人民大学的学者们以及卡耐基梅隆大学的学者们在 AAAI 2025 会议上正式发布了他们的最新研究。这项研究名为 BPO-AVASR(Bifocal Preference Optimization for Audiovisual Speech Recognition)。
这种双焦点偏好优化方法是全新的,它可以有效提升多模态语音识别(AV-ASR)系统的性能,让该系统在真实世界视频场景下的表现更为强大。

论文链接:
代码地址:
语音识别的「视觉外挂」:为什么要结合视觉?
传统的 ASR 系统只是依靠音频输入来进行语音识别。然而在现实的场景里,仅仅凭借音频通常是不能够足够精准地识别出用户的语音的。比如:
视觉信息,尤其是视频里的物体、背景信息以及文本等,能够提供额外的线索,以便帮助 ASR 模型更准确地理解语音内容。比如,当看到屏幕上出现了一瓶“可口可乐”时,ASR 识别“cola”而不是“caller”的可能性会变得更高。正因如此,AV-ASR(音视频语音识别)便应运而生了,它将视觉与语音信息相结合,从而提升识别的准确性。
双焦点偏好优化(BPO)
多模态 ASR 在近年来取得了显著的进展,然而,目前的方法依然存在一些关键的问题:
研究者们为了解决那些问题,提出了一种全新的方法,即双焦点偏好优化(Bifocal Preference Optimization, BPO)方法,并且以 BPO - AVASR 模型作为核心。这篇工作的创新点包含以下方面:
输入端偏好优化(Focal I):利用遮挡音频或者扰动视频信息的方式,模拟现实世界里的干扰因素,让模型能够学会在音视频信息缺失的情况下做出更准确的预测。
输出端偏好优化(Focal II):利用 AI 生成的错误文本,像同音词替换、语音模糊重写等这类方式,使模型能够学会怎样避免这些常见的识别错误。
换句话说,要让模型不但学会“看”和“听”,还要让它学会在信息不完整或者错误的情形下怎样做出更优的决策,以此更好地在多模态的场景里同时运用视觉和听觉信息,进而识别出准确的文本。
如何构造偏好数据?
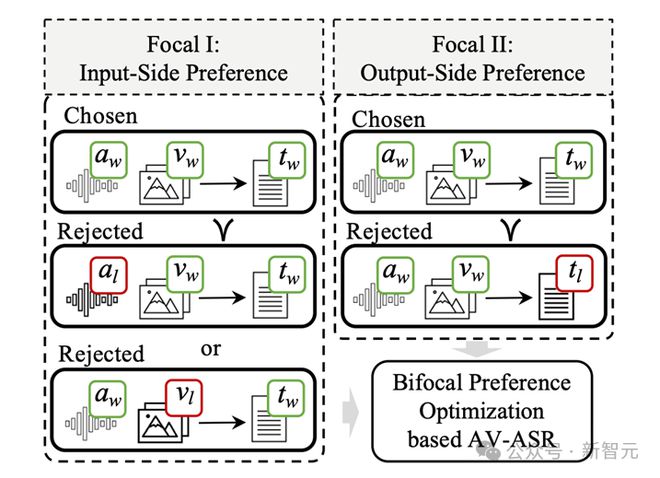
BPO-AVASR架构概览
BPO-AVASR优化 ASR 的方式是构造偏好数据,主要在输入端和输出端进行优化。
输入端偏好数据构造(Focal I)
目标是让模型学会处理不完整的音视频信息,并且提升对噪声以及模糊信息的适应能力。
输出端偏好数据构造(Focal II)
目标是让模型学会避免常见的识别错误,从而优化 ASR 预测文本的准确性。
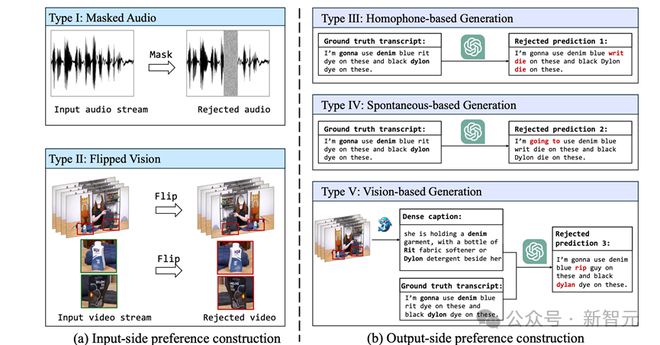
偏好数据构造方法
实验结果与结论:BPO-AVASR让ASR更强大!
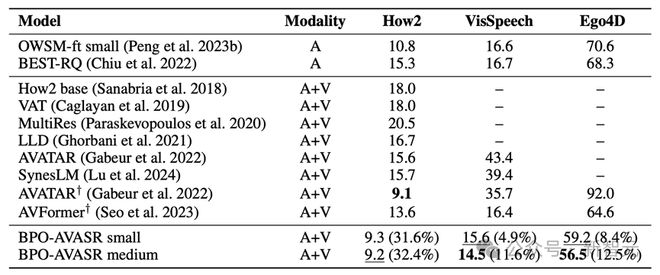
研究者们为了验证 BPO-AVASR 的效果,在多个基准数据集上进行了测试。这些基准数据集包括 How2、VisSpeech 和 Ego4D。通过在不同领域的多模态数据上进行测试,验证了该方法的有效性。
实验结果显示,BPO-AVASR 在多数测试数据集中获得了 SOTA 性能,特别是在嘈杂环境以及复杂视频场景中表现良好。比如:

未来展望:让 AI 更懂「看」与「听」
BPO-AVASR 获得了成功,这使得 ASR 模型在复杂环境中变得更加稳定。并且,它还为未来的多模态学习提供了新的思路。在未来,研究者们期望:
参考资料:
