2025 年,DeepSeek 和 QwQ 等这类推理大模型在全球范围内非常火爆。它们在复杂任务中展现出了强大的实力。这使得很多企业开始思考,怎样能够借助这一轮推理大模型的技术进步,去优化自身的决策,提升企业的运行效率,并且促进创新。
传统的 CPU 服务器在应对当前的 AI 推理需求时能力不足。GPU 推理服务器成本高昂,动辄上百万,这使得许多中小企业被挡在门外。
在这样的背景之下,市场迫切需要一种服务器解决方案。这种解决方案既要能够控制成本,又要能够保证性能。其目的是满足企业对于便捷且高性价比的 AI 推理服务的需求。
AI 技术快速发展,CPU 服务器持续进化。近日,浪潮信息发布了元脑 CPU 推理服务器,它可以高效运行 DeepSeek-R1 32B 和 QwQ-32B 等推理模型,这些模型适合企业日常需求。同时,它还能与企业原有的业务兼容,并且具备性价比高、运维简单等优势。
元脑CPU推理服务器,基于QwQ-32B模型生成猜数字游戏
新一代 CPU 推理服务器在 GPU 服务器之外,为企业提供了算力供给。这种算力供给快速、易获取且成本低,正成为更多企业的理想选择。
跑大模型 GPU 不是唯一的解决办法,CPU 推理服务器成为了中小企业理想的新选择。
谈及部署大模型时,很多企业的首要反应是“买卡”。确实,在大模型进行训练以及推理的场景里,GPU 加速卡凭借其强大的浮点运算能力和大规模并行处理的架构,在高吞吐量的 AI 推理任务方面展现出了显著的优势。
但GPU并不是唯一解。
CPU在处理复杂的逻辑运算以及通用计算任务方面较为擅长。GPU 在高并行计算任务上表现更优,然而 CPU 在处理多样化工作负载时,如数据库查询和业务逻辑处理,其性能表现十分优秀。并且,随着技术持续迭代,具备 AI 计算能力的 CPU 服务器开始在 AI 推理场景中显示出独特的优势。
大模型推理过程中,有不少模型会采用 KV Cache(键值缓存)。这种缓存用于存储解码过程中生成的中间结果。通过这种方式,可以减少重复计算,进而提升推理效率。随着模型规模的不断增大,KV Cache 的存储需求也会随之不断增加。
CPU 推理服务器与 GPU 服务器相比,它的硬件投入更低。它能够支持更大容量的系统内存,这样就可以轻松地存储更大规模的 KV Cache。而且,它还能避免频繁的数据交换,进而提升推理效率。此外,CPU 推理服务器可通过多通道内存系统,进一步支持大规模 KV Cache 的高效访问。
CPU 推理服务器与高效的中等尺寸推理模型相结合后,能够形成协同效应,这种协同效应是显著的。并且在保证性能的同时,还能进一步压缩成本。
业界多款 32B 推理模型为例,这些模型采用了更高效的注意力机制,降低了计算需求;采用了模型量化与压缩技术,降低了存储需求;采用了 KV Cache 优化,降低了计算和存储需求。例如,DeepSeek-R1 32B 在知识问答等方面表现优异,在智能写作等方面表现优异,在内容生成等方面表现优异;QwQ-32B 在数学推理等领域展现出强大性能,在编程任务等领域展现出强大性能,在长文本处理等领域展现出强大性能。
DeepSeek-R1 32B 的训练数据包含海量高质量中文语料库,QwQ-32B 的训练数据也包含海量高质量中文语料库,这使得它们更加适合国内企业的应用需求。
在企业的知识库问答场景中,32B 参数级别的模型通常是最佳选择,它能提供强大的能力支持。在文档写作场景中,32B 参数级别的模型也是最佳选择,同样能提供强大的能力支持。在会议纪要整理场景中,32B 参数级别的模型依然是最佳选择,依旧能提供强大的能力支持。32B 参数级别的模型既能提供强大的能力支持,又能保持合理的硬件投入。仅依靠 CPU 推理服务器,企业用户就可以实现本地化部署,从而满足对性能、成本和易用性的多重需求。
从成本方面来讲,GPU 服务器有着高昂的硬件成本,并且对电源、散热以及机架空间的要求也更为严格。而 CPU 服务器在这些方面的要求相对较为宽松。对于那些只是轻量使用且预算有限的企业来说,CPU 服务器更具有性价比。
二、软硬件协同优化成效显著,解码速度翻番、效率提升至4倍
浪潮信息本次推出的元脑 CPU 推理服务器,是一款能够支持中等尺寸模型推理的服务器,并且可以为中小企业提供高效的 AI 推理服务。

在实际测试当中,单台元脑 CPU 推理服务器在进行带思维链深度思考的短输入长输出的问答场景时,解码性能能超过 20tokens/s。并且在 20 个并发用户的情况下,总 token 数能够达到 255.2tokens/s。
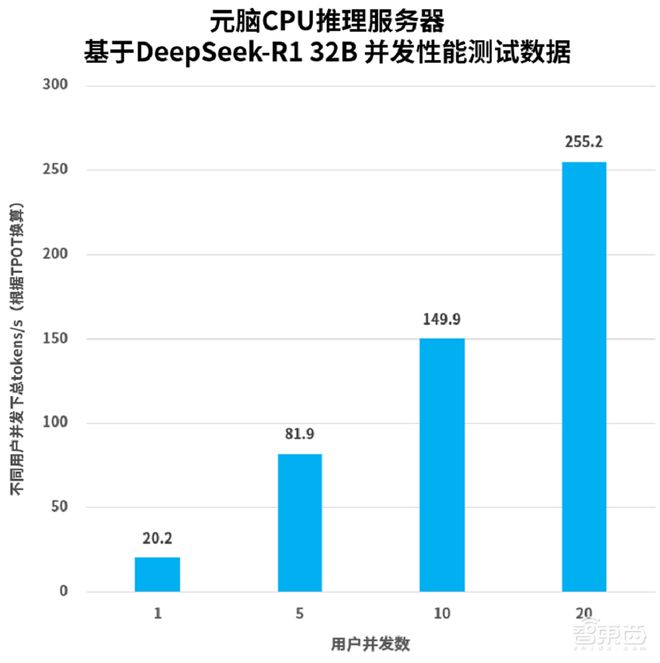
基于DeepSeek-R1 32B 并发性能测试数据
在使用 QwQ-32B 进行模型推理时,当有 20 个并发用户时,总 token 数能达到 224.3tokens/s,这样就能提供流畅稳定的用户体验。

基于QwQ-32B 并发性能测试数据
元脑 CPU 推理服务器的性能,是因为浪潮信息进行了软硬件协同优化。浪潮信息的软硬件协同优化使得元脑 CPU 推理服务器的性能得以提升。
元脑 CPU 推理服务器在算力方面,采用了 4 颗 32 核心的英特尔至强处理器 6448H。它具备 AMX(高级矩阵扩展)AI 加速功能,并且能够支持张量并行计算。与传统双路服务器方案中内存有限的情况不同,元脑 CPU 推理服务器的多通道内存系统设计可以支持 32 组 DDR5 内存。
这些硬件给予了支持,元脑 CPU 推理服务器单机拥有 BF16 精度的 AI 推理能力,内存容量最大能达到 16T,内存带宽为 1.2TB/s,这样就能更好地满足模型权重、KV Cache 等方面的计算和存储需求,能够快速地读取和存储数据,从而大幅提升大模型的推理性能。
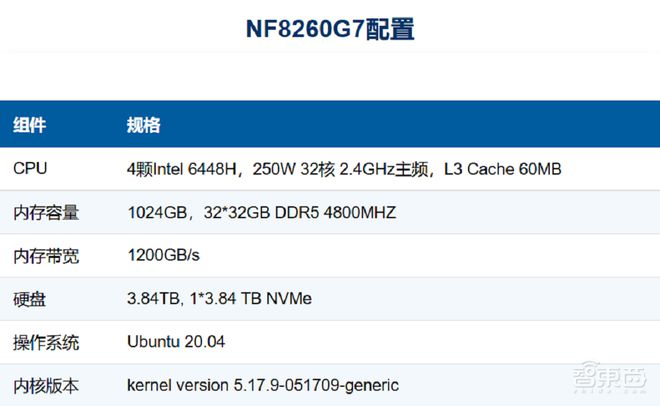
元脑CPU推理服务器NF8260G7配置
元脑 CPU 推理服务器在算法方面,对业界主流的企业级大模型推理服务框架 vLLM 进行了深度定制优化。它利用张量并行和内存绑定技术,能够充分释放服务器的 CPU 算力和内存带宽潜能,从而实现多处理器并行计算,其效率最高可提升至 4 倍。
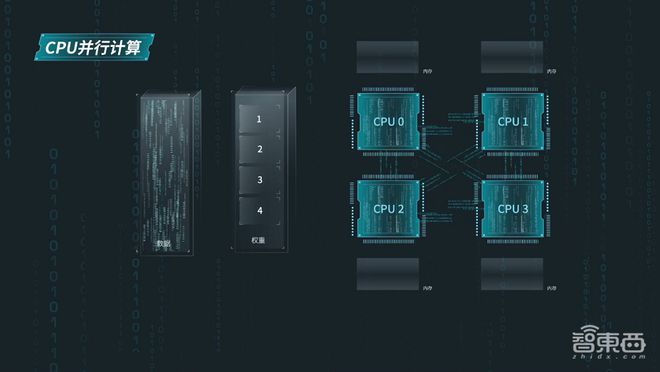
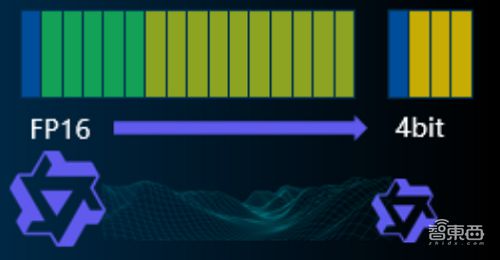
元脑 CPU 推理服务器面临内存带宽的挑战。为了进一步提升解码性能,它采用了 AWQ(Activation-aware Weight Quantization 激活感知权重量化)技术。
AWQ 技术能够明确模型中对性能影响最为显著的那少部分关键权重,并且通过对这些权重进行保护,从而减少量化所导致的误差。同时,AWQ 也避免了因混合精度计算而产生的硬件效率方面的损失。
元脑 CPU 推理服务器采用了 AWQ 后,在解码任务中的性能提升了一倍。这使得大模型在保持高性能的同时,能够跑得更快,并且更省资源。
元脑 CPU 推理服务器借助浪潮信息构建的 AI Station 平台,能够让用户灵活地挑选适配的大模型算法。这些算法涵盖 DeepSeek 全系模型,以及参数量不同的 QwQ 和 Yuan 等模型。
三、更懂中小企业需求,通用性、成本效益突出
在与浪潮信息副总经理赵帅的沟通里,我们得知,元脑 CPU 推理服务器推出仅 1 周时间,就有多家来自大模型、金融、教育等行业的客户前来咨询和进行测试,这款 CPU 推理服务器恰好填补了中小企业市场里的一个重要空白。
目前,许多企业对于将私有数据放置在云上仍持有保留的态度,它们更倾向于在本地把 AI 推理任务完成。然而,倘若企业决定使用 GPU 服务器去部署高性能的 AI 模型,通常就需要承担起高额的初始投资成本。中小企业觉得这种投资的性价比不高。它们一般不需要特别极致的 AI 性能,也不需要超高的并发处理能力。它们更注重的是那种易于部署、易于管理并且易于使用的入门级 AI 推理服务。
在这种情形下,生态较为成熟且开发工具较为健全的 CPU 推理服务器呈现出了明显的优势。CPU 推理服务器不但可以更好地融入企业现有的 IT 基础架构,还由于其具有通用性而拥有更高的灵活性。
专用 AI 硬件(如 GPU 服务器)有其特殊性,而 CPU 推理服务器则不同。在 AI 推理需求空闲期,它能够同时兼顾企业的其他通用计算需求,像数据库管理以及 ERP 系统运行等。这样一来,就可以使硬件资源的利用率达到最大化。
元脑 CPU 推理服务器在部署便捷性上表现突出,其功耗约为 2000W。这降低了对供电设备的要求,同时也使服务器的冷却需求大幅减少,仅家用级空调就能满足散热需求。这就意味着元脑 CPU 推理服务器可以轻松适应大部分企业自建的小型机房环境,无需额外投入高成本的冷却设施,也无需对现有机房进行大规模改造。
元脑 CPU 推理服务器具备高可靠性。其平均无故障时间能达到 200000 小时。这能够保障关键应用以及 AI 推理任务持续稳定运行。这一特性对企业很重要。在金融、医疗、制造等对系统稳定性要求极高的行业中尤其如此。高可靠性意味着业务中断风险更低,运营效率更高。
谈及未来时,赵帅分享道,浪潮信息将会进一步增强元脑 CPU 推理服务器的能力。凭借着在融合架构开发方面积累的经验,他们已经开始开发内存资源池化的新技术,并且会结合长文本等算法特征来进行软件优化,以便更好地满足企业的使用需求。
结语:CPU推理服务器有望推动AI普惠
AI 技术向行业深水区发展,大模型推理需求在逐步发生变化。大模型推理需求从大型企业开始,正逐渐向中小企业渗透。同时,大模型推理需求也从少部分企业所享有的“奢侈品”,转化为大部分企业的“必需品”。
在这一进程里,像元脑 CPU 推理服务器这样具备高性价比的 AI 推理解决方案,有希望成为中小企业达成 AI 普及化以及行业实现智能化的重要工具。
