认知智能全国重点实验室&华为诺亚方舟投稿
量子位| 公众号QbitAI
推荐大模型也可生成式,并且首次在国产升腾NPU上成功部署!
在信息呈爆炸式增长的时代,推荐系统已然成为生活当中不可或缺的一个部分。 meta率先把生成式推荐范式HSTU 给提了出来,并且把推荐的参数拓展到了万亿这个级别,从而取得了非常显着的成果。
近期,中科大和华为展开了合作,共同开发了推荐大模型的部署方案,此方案能够应用在多个不同的场景之中。
探索过程中还有哪些经验与发现?最新公开分享来了。
报告亮点包括:
具备扩展定律的生成式推荐范式正在成为未来趋势

如图1 展现的那样,推荐系统的发展趋势为逐步降低对手工设计特征工程以及模型结构的依赖。在深度学习开始兴起之前,由于受到计算资源的限制,人们更倾向于运用手工设计的特征以及简单的模型(图1A)。
深度学习在不断发展。研究者将精力集中在复杂模型的设计上。这样做是为了能更好地贴合用户的偏好。同时也可以提升对GPU 并行计算的利用效率。 (图1B)
然而,深度学习能力出现了瓶颈。于是,特征工程再次受到了关注(图1C)。
如今,大语言模型的扩展定律获得了成功,这启发了推荐领域的研究者。扩展定律对模型性能与关键指标之间的关系进行了描述,这些关键指标包括参数规模、数据集规模和训练资源等,它们之间呈现幂律关系。通过增加模型的深度和宽度,并且结合大量数据,就能够提升推荐效果,如图1D 所示,这种提升推荐效果的方法被称作推荐大模型。
近期,HSTU 等生成式推荐框架在这个方向上取得了明显的成果,这些成果验证了推荐领域的扩展定律,从而引发了生成式推荐大模型研究的热潮。团队觉得,生成式推荐大模型正逐渐成为能够颠覆当前推荐系统的下一个新的范式。
在此背景之下,要去探索哪些模型确实具备可扩展性,需要理解这些模型成功应用扩展定律的缘由,并且要弄清楚怎样利用这些规律来提升推荐效果,这些都已经成为当前推荐系统领域的热门课题。
基于不同架构的生成式推荐大模型扩展性分析
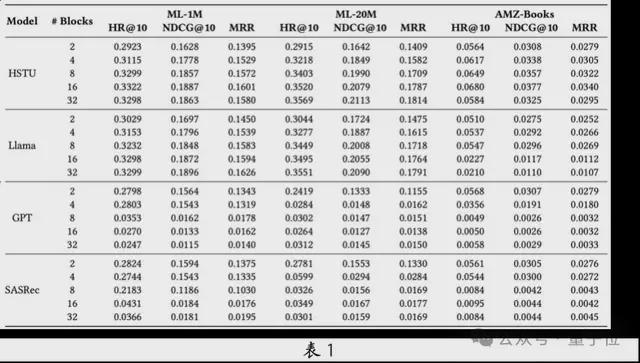
团队为了评估生成式推荐大模型在不同架构下的扩展性,对HSTU、Llama、GPT 和SASRec 这四种基于Transformer 的架构进行了对比。
在三个公开数据集上,对不同注意力模块数量下的性能表现进行了分析(见表1)。结果表明,在模型参数较小时,各架构的表现较为相似,并且最优架构会因数据集的不同而有所差异。
然而,HSTU 和Llama 的性能随着参数扩展而显着提升,GPT 和SASRec 的扩展性则存在不足。 GPT 在其他领域表现良好,但是在推荐任务上未达到预期。团队认为,这是由于GPT 和SASRec 的架构缺少专为推荐任务设计的关键组件,无法对扩展定律进行有效利用。
生成式推荐模型的可扩展性来源分析
团队进行消融实验是为了探究HSTU 等生成式推荐模型的可扩展性来源。他们分别去除了HSTU 中的关键组件,包括相对注意力偏移(RAB)、SiLU 激活函数以及特征交叉机制。
实验结果显示,从表2 可以看出,单一模块缺失时,模型的扩展性没有受到显着影响。然而,当RAB 被移除后,性能出现了明显下降,这表明RAB 具有关键作用。

团队为了进一步分析赋予模型扩展定律的相关因素,将SASRec 与扩展性良好的HSTU 和Llama 进行了比较,发现它们的主要差异在于RAB 以及注意力模块内的残差连接方式。
为了验证这些差异是否属于扩展性的关键部分,团队把HSTU 的RAB 引入到了SASRec 中,并且对其注意力模块的实现方式进行了调整。
实验结果显示,从表3 可看出,单独添加RAB 以及修改残差连接这两种情况,都没有使SASRec 的扩展性得到显着提升。但是,当把这两个组件同时进行修改之后,SASRec 就展现出了良好的扩展性。这也就意味着,残差连接模式与RAB 相结合,给传统推荐模型赋予了扩展性,并且为未来推荐系统的扩展性探索提供了重要的启示。

生成式推荐模型在复杂场景和排序任务中的表现
复杂场景中的表现
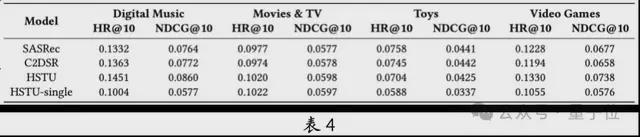
HSTU在多域方面表现出色。在多域的场景中,比如在AMZ-MD 的四个域里,HSTU一直比基线模型SASRec 和C2DSR 更优(见表4)。 HSTU 在多行为的场景中也表现良好。同时,HSTU 在辅助信息等复杂场景中也展现出了出色的性能。
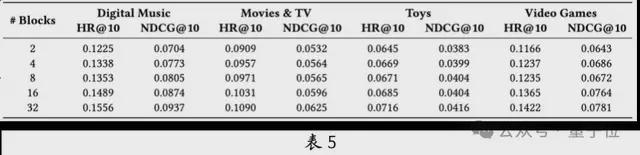
HSTU 进行多域联合训练后比单域独立训练的HSTU-single 表现更好,这证明了多域联合建模的优势。从表5 可以看出,HSTU 在多域行为数据上的扩展性较为显着,尤其是在规模较小的场景,像Digital Music 和Video Games 上。这意味着HSTU 在解决冷启动问题方面具有潜力。
在排序任务中的表现
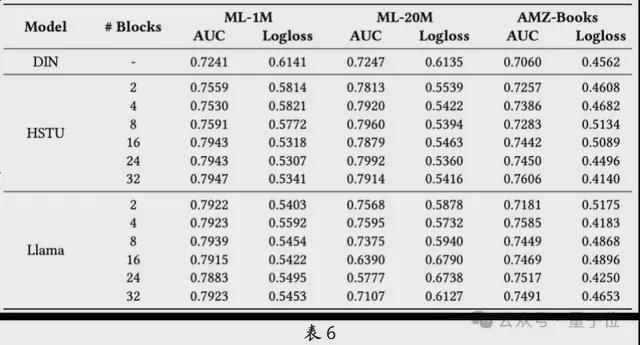
排序在推荐系统中是重要的一部分。团队对生成式推荐模型在排序任务中的有效性和扩展性进行了深入探讨。从表6 可以看出,生成式推荐大模型在性能方面比DIN 等传统推荐模型要显着优越。虽然在小规模模型中,Llama 的表现比HSTU 好,但是HSTU 在扩展性上更有优势,而Lama 在扩展性上则显得不够。
团队研究了负采样率以及评分网络架构对排序任务所产生的影响,并且进行了全面的分析。同时,也探讨了将embedding 维度进行缩减对性能带来的影响。从表7 可以看出,缩小embedding 维度提升了小数据集ML - 1M 和AMZ - Books 的性能,然而在大数据集ML - 20M 上却出现了性能下降的情况。这表明,推荐大模型的扩展定律受垂直扩展影响,垂直扩展指的是注意力模块的数量;同时,该定律也受水平规模影响,水平规模指的是embedding 的维度。

未来方向和总结
团队在技术报告中指出了一些推荐大模型未来研究的潜力方向,包括数据工程、Tokenizer 以及训练推理效率等。这些方向能够帮助解决当前面临的挑战,并且可以拓宽大模型的应用场景。
论文链接:
主页链接:
