一位 AI 公司的 CEO 刚刚仔细剖析了关于 Llama 4 的五个疑点。有圈内人甚至表示,Llama 4 表明 Scaling 已经结束,LLM 无法进行可靠推理。然而更令人担忧的是,全球的 AI 进步可能会完全停滞。
令人失望的Llama 4,只是前奏而已。
接下来我们恐将看到——全球局势的改变,将彻底阻止AI进步!
最近,一位 AI 的 CEO 制作了长视频。他逐层级地对 Llama 4 身上的六个疑点进行了剖析和揭露。

NYU 教授马库斯发出了一篇博客,在这篇博客中他总结了目前这段时间 AI 圈的状况。
Scaling 已经完成;模型依旧无法进行可靠推理;金融泡沫正在开始破裂;依然没有出现 GPT - 5;对不可靠语言模型的过度依赖致使世界陷入了困境。我在 2025 年的 25 个预测,每一个目前看来都是正确的。
大语言模型不是解决之道。我们确实需要一些更可靠的方法。
OpenAI 以及 Anthropic 这类公司,需要获取资金以资助新模型后续的大规模训练运行。然而,它们的银行账户中并不具备 400 亿或 1000 亿美元,无法支撑庞大的数据中心以及其他相关费用。
问题在于,倘若投资者预见到了经济衰退,那么就会出现两种情况,要么不会进行投资,要么投资的金额会比较少。
更少的资金,就意味着更少的计算,也就是更慢的AI进展。
美国的科研产出或许会降低 8%-12%
在之前的一次采访中,Anthropic 的 CEO Dario 被问到:到了现在这个阶段,有什么能够阻止 AI 的进步呢?他提及了一种可能性,那就是战争。
没想到,在这个可能性之外,我们竟然提前看到了系统呈现出的另一种混沌状态。
Dario 提前预见到了这种情况,即如果存在“技术不会向前发展”这样的信念,并且资本化不足,那么 AI 的进步就会停止。
AI CEO五大问,逐级扒皮Llama 4
最近闹出大丑闻的Llama 4,已经证明了这一点。

我们难以确切地说,Llama 4 系列的三款模型当中的其中两款展现出了多大的进展。很明显,在这个系列的发布过程中,夸大宣传的部分比诚实分析的部分要多很多。
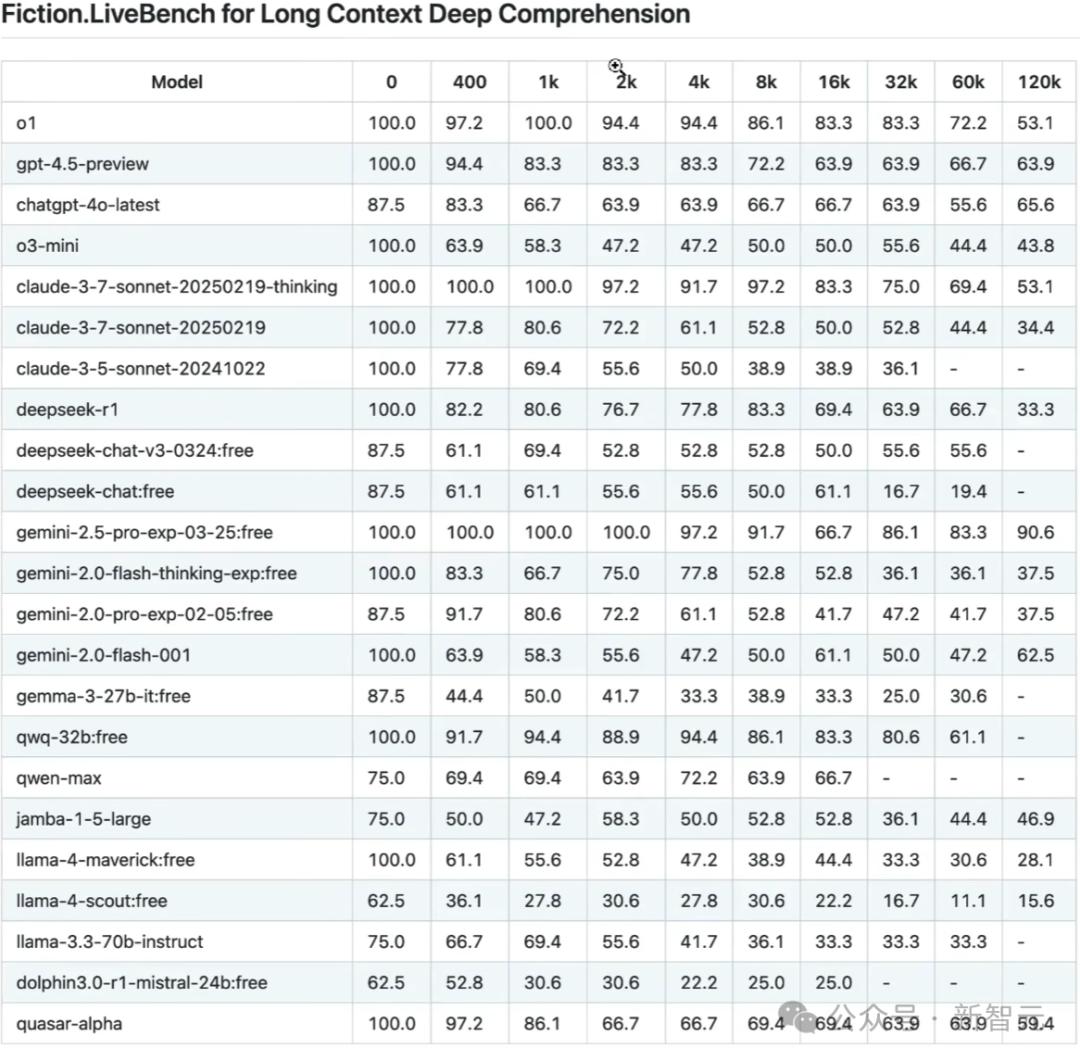
疑点1:长上下文大海捞针,其实是骗人?
Llama 具有一千万个 token 的上下文窗口,这在业界是领先的,听起来显得很酷炫。
可是,在 24 年 2 月,Gemini 1.5 Pro 的模型就已经达到了 1000 万 token 的上下文。
在极端的情形下,它能够在视频、音频以及共同文本之上,去执行极为艰巨的任务,就好像在大海中捞针一样。或许,是谷歌突然察觉到,这样的大海捞针任务具有极其重大的意义。
这篇 Llama 4 博客指出,倘若将所有哈利波特的书都放置进去,那么模型能够检索到被放入其中的一个密码。
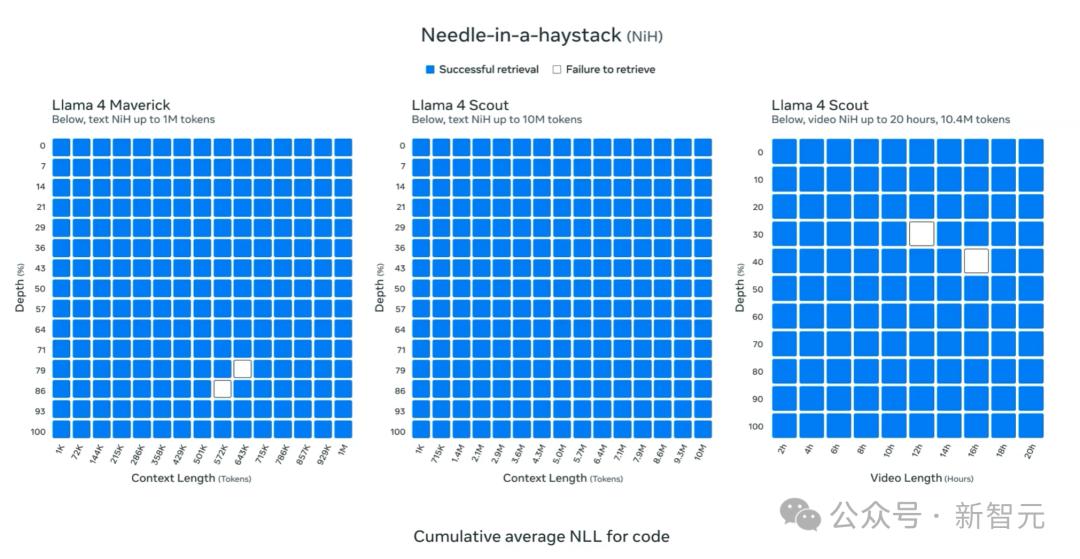
这位 CEO 表示,这些结果是 48 小时前发布的。这些结果不如 24 小时前更新的那个 fiction livebench 基准测试重要。
这个基准测试是用于长上下文的深度理解的。LLM 要将数万或者数十万个 token 或者单词拼凑在一起。
在这个基准测试中,Gemini 2.5 Pro 的表现较为出色。而与之相比,Llama 4 的中等模型以及小模型,其性能是非常糟糕的。
而且随着token长度的增加,它们的表现越来越差。
疑点2:为何周六发布?
这位 CEO 察觉到的第二个疑点是,Llama 4 为何选择在周六发布。
在整个美国AI技术圈里,这个发布日期都是史无前例的。
如果从阴谋论的角度去思考,选择在周六发布的原因是 meta 自身感到心虚了,它希望能够尽量降低人们对其的关注度。
此外,Llama 4 的训练数据截止到 2024 年 8 月。这一点显得很奇怪。
需要知晓的是,Gemini 2.5 的训练知识截止的时间为 2025 年 1 月。
过去的 9 个月里,meta 一直在拼命使这个模型达到标准,用尽了浑身解数。
他们或许原本打算早点发布Llama 4。然而在 9 月,OpenAI 推出了 o 系列模型。接着在今年 1 月,DeepSeek R1 又出现了。正因如此,meta 的所有计划都被打乱了。

疑点3:大模型竞技场,究竟有没有作弊?
这位 CEO 承认,全网有对 Llama 4 群嘲的声音。同时,他也表示 Llama 4 的确展示出了一些坚实的进展。

Llama 4 Maverick 的活动参数量大概仅为 DeepSeek V3 的一半,然而它却获得了相当的性能。
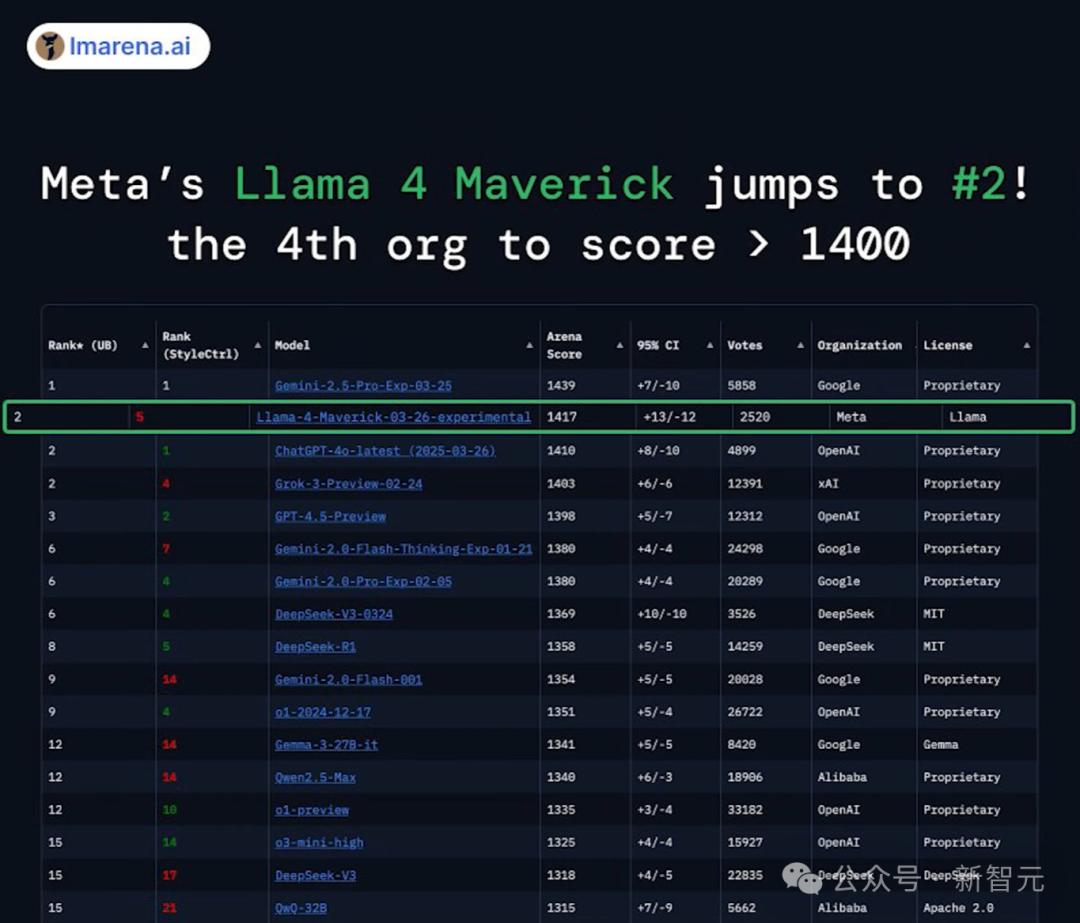
现在的核心问题是,meta 是否在 LM Arena 上进行了作弊,以及是否在测试集上进行了训练?
目前,LM Arena 已经迅速采取行动。它公开了 2000 多组对战数据,供公众进行检阅。同时,它还表示会重新评估排行榜。
目前暂且不算,这意味着我们拥有一个极为强大的基础模型。
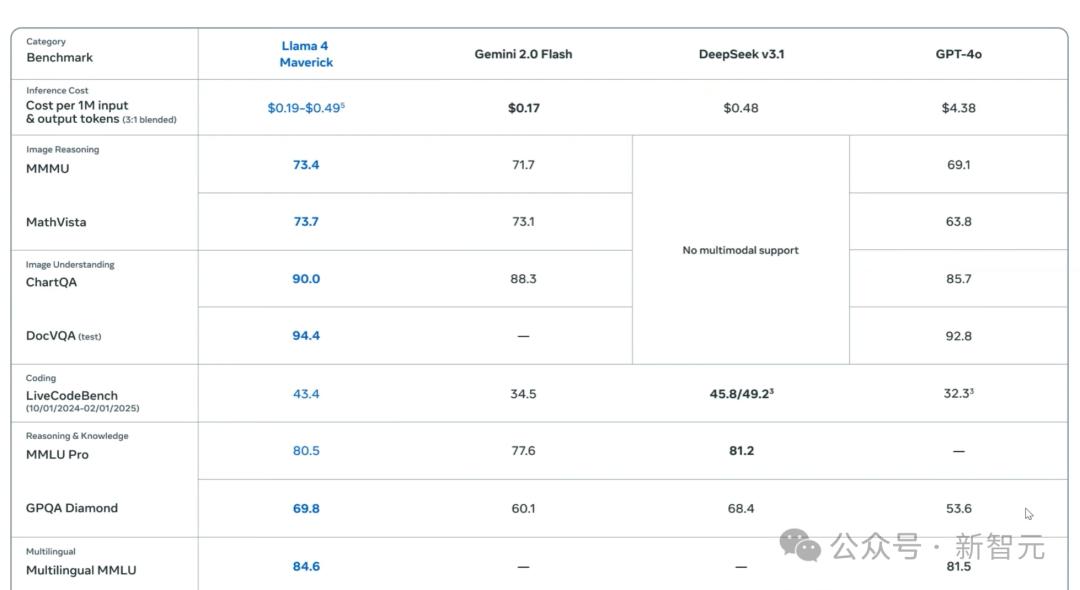
看看这些真实数字,假设没有任何答案进入 Llama 4 的训练数据。在这种情况下,这个模型在 GPQA Diamond 上的性能,也就是谷歌验证的极其严格的 STEM 基准测试上的性能,实际上是比 DeepSeek V3 更好的。
meta 在这个基础之上,是完全有能力创建一个处于 SOTA 级别水平的思维模型的。
Gemini 2.5 Pro 已经存在,这是唯一的一个问题。同时,DeepSeek R2 也随时会问世。
疑点4:代码很差
还有一点,当Llama 4走出舒适区时,性能就会开始狂降。
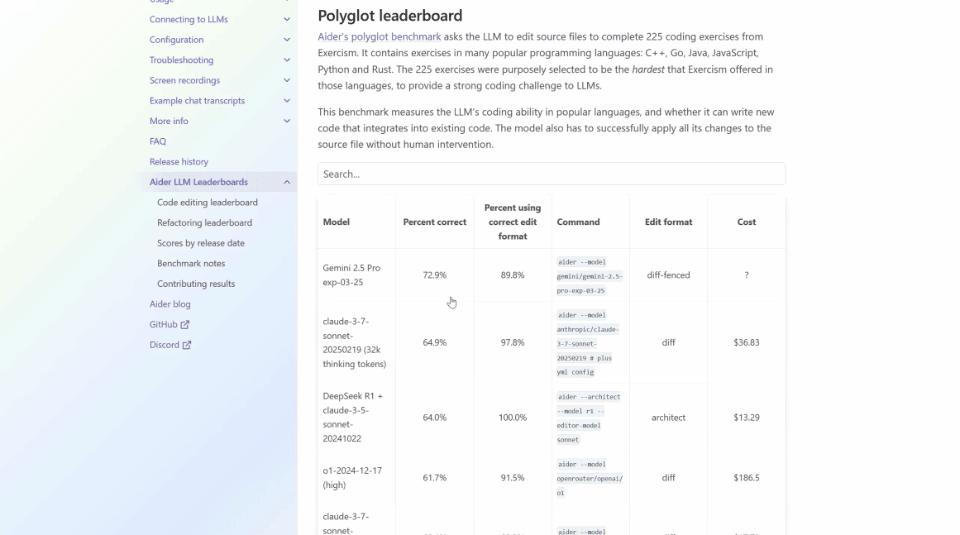
以 ADA 的 Polyglot 作为编码基准测试来看,它对一些系列编程语言的性能进行了测验。
它与许多基准不一样,它不只关注 Python 这一种语言,而是涵盖了一系列编程语言。并且,在现在的情况下,它依然在 Gemini 2.5 Pro 中处于领先地位。
但是要找到 Llama 4 Maverick 是很困难的,需要把鼠标滚动很长时间。
它的得分当然惨不忍睹——只有15.6%。
这就跟小扎的言论出入很大了,显得相当讽刺。
不久前,他曾坚定地宣称,meta 的 AI 模型很快就会取代中级程序员。
疑点5:「结果仅代表目前最好的内部运行」
这一点,同样已经在AI社区引发了群嘲。
meta 在下面这个表格里,把 Llama 4 与 Gemini2.0 Pro、GPT-4.5 等模型作了比较,这些数字相当漂亮。
仔细看脚注,它表明的是 Llama 模型的结果代表了当前最佳的内部运行状况。由此可以推断,meta 很有可能将 Llama 4 运行了 5 遍或者 10 遍,然后选取了其中最好的结果。
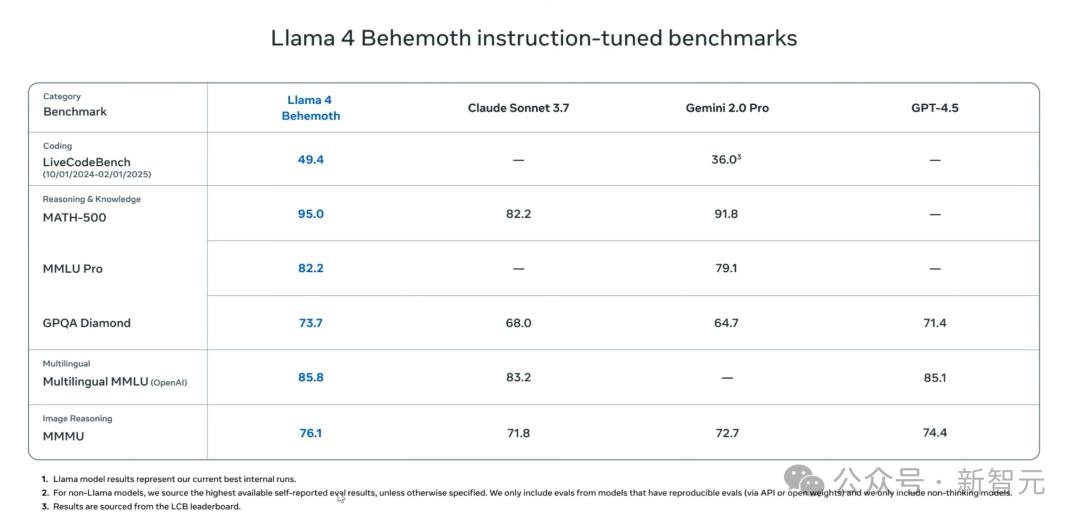
他们故意不把 Llama 4 Behemoth 与 DeepSeek V3 进行比较。DeepSeek V3 在整体参数上比 Llama 4 Behemoth 小三倍,在互动参数上比它小八倍,然而二者性能相似。
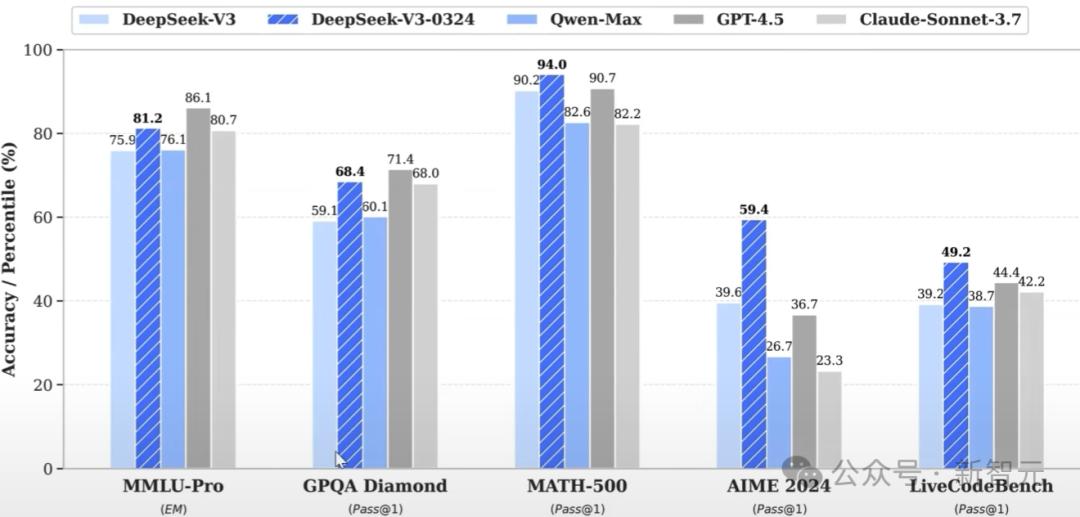
从消极角度来判断的话,可以说 Llama 4 的模型参数是 DeepSeek V3 基础模型的许多倍,然而其性能却基本上处在同一水平。
在 Simple Bench 中,Llama 4 Maverick 的得分约为 27.7%。它与 DeepSeek V3 的水平相当,并且低于 Claude 3.5 Sonnet 这类非思维模型。
这位 CEO 还发现了在 Llama 4 的使用条款中有这么一条。
在欧洲,你依然可以成为它的最终用户,然而却没有权利在它的基础上构建模型。

马库斯称,Llama 4 带来了惨痛的教训,这表明 Scaling 已经走到了尽头。
Llama 4 的表现较为惨淡,这使得 NYU 教授马库斯撰写了一篇长文,他在文中断言 Scaling 已经结束,并且 LLM 仍然无法进行推理。

他的主要观点如下。
大模型的 Scaling 已经完成了。这表明了我三年前在《深度学习正在撞墙》里所做的预测是正确的。
一位 AI 博士写道:Llama 4 已经发布了。这证实了,即便有 30 万亿 token 和 2 万亿参数,也无法让非推理模型比小型推理模型更好。

规模化无法取得成效,真正的智能所需要的是意图,并且意图需要有远见,这些都是人工智能所不能做到的。

LLM 偶尔能给出正确答案,不过往往是借助模式识别或者启发式的捷径来做到的,而非依靠真正的数学推理。
最近 ETU 团队针对 LLM 在美国奥数方面表现不佳所做的研究,彻底打破了“LLM 会做数学题”这一神话。
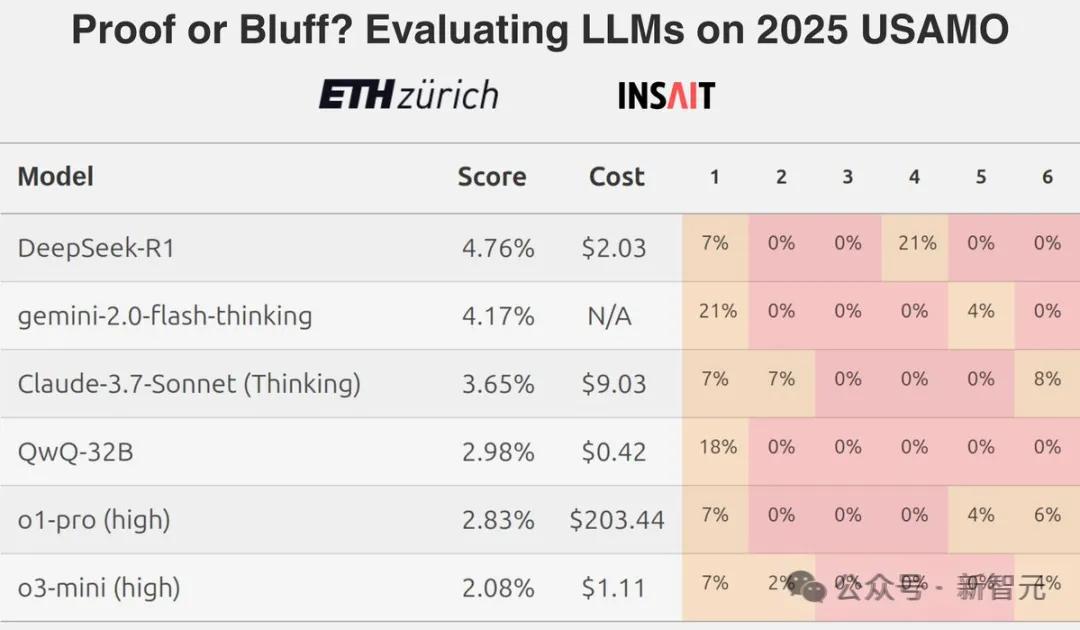
最终,生成式AI很可能会变成一个在经济回报上失败的产品。
泡沫或许真的即将破灭。英伟达在 2025 年的跌幅达到了三分之一还多。
meta 的 Llama 4 存在的残酷事实,再次印证了马库斯在 2024 年 3 月所做出的预测。
要达到 GPT-5 级别的模型,这将会是一件极为困难的事情。许多公司都拥有类似的模型,然而却都没有形成自身的护城河。随着价格战不断地进一步升级,很多公司所能获得的利润将会非常微薄。

最终,马库斯以这样的方式总结了自己的发言——
大语言模型并非解决之道,我们需要一些更为可靠的方法。Gary Marcus正在寻觅对开发更可靠的替代方法怀有兴趣的投资者。
参考资料:
本文源自微信公众号“新智元”,作者是新智元,36 氪获得了发布的授权。
