在信息检索系统里,搜索引擎的能力只是对结果产生影响的一个部分。真正的瓶颈通常是:用户的原始 query 自身不够优良。
在专业搜索场景,比如文献搜索、数据库查询等场景中,用户通常不能够用精确且完整的表达来把他们的需求描述出来。
那么问题是:能否教大模型去优化原始 query 的表达方式呢?这样做能否让已有检索系统的能力被最大化地激发?
UIUC 的 Jiawei Han 团队和 Jimeng Sun 团队有一项最新工作,即 DeepRetrieval,这项工作针对这个问题提出了系统性解法,并且只需 3B 的 LLM 就能够实现 50 个点以上的提升。

DeepRetrieval 这一研究通过强化学习,对真实搜索引擎和检索器进行了“攻击”,且是借助大型语言模型来实现的。
论文地址:
开源代码:
开源模型:
DeepRetrieval 是一个 query 优化系统,它基于强化学习(RL)。这个系统训练 LLM,让其在不同检索任务中优化原始查询,目的是最大化真实系统的检索效果。
它不是去训练一个新的 retriever,同时也不是让模型直接去回答问题,而是有着其他的方式,具体如下:
在不改变现有搜索系统的情况下,先优化原始 query,接着让“提问方式”变得更聪明,最后就能获取更好的结果。
请阅读原文正文以及附录的 Discussion 部分,那里有更多有意义的讨论。
方法细节

方法要点
输入 :原始查询 q
请提供需要改写的句子呀,你没有给出具体的横线下的句子呢。
环境反馈:首先用 q′ 在系统中进行检索查询,接着返回结果,然后将返回结果与 groundtruth 进行对比,以此来计算 reward。reward 是针对 task-specific 检索表现的(像 Recall@K、NDCG@K、SQL accuracy 等)。使用 PPO 进行训练,同时加入格式奖励(format correctness)以及 KL-regularization 以保证训练的稳定,优化目标如下:
其中,π_ref 为参考策略,一般指强化学习开始前的初始模型。β 是一个恰当的 KL 惩罚系数,其作用是控制正则化的强度。KL 散度项能够惩罚当前策略与参考策略之间的过度偏离,以此在强化学习训练过程中确保策略更新的稳定性。
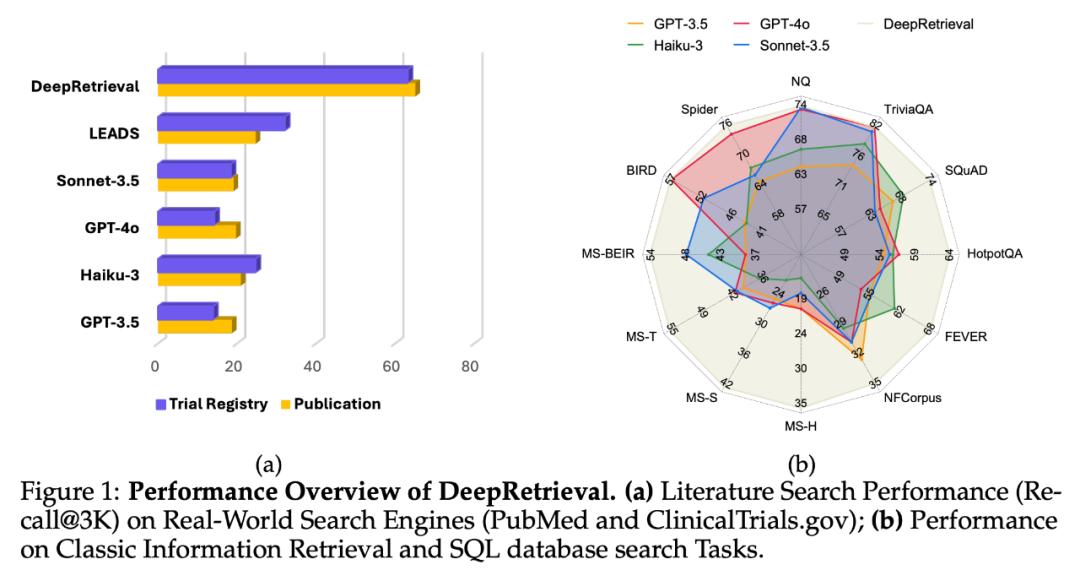
实验结果 真实搜索引擎的文献搜索
在真实的搜索引擎上进行实验,文中使用了专业搜索引擎 PubMed 以及 ClinicalTrials.gov 。无需对搜索引擎或其它检索器进行改动,仅通过端到端地优化 query 表达这一方式,DeepRetrieval 能够使结果获得 10 倍提升,并且这个提升远超各个商业大模型以及之前的 SOTA 方法 LEADS(蒸馏 + SFT 方法)。
通用搜索引擎具有革新潜力,这种潜力体现在 Evidence-Seeking 检索方面。
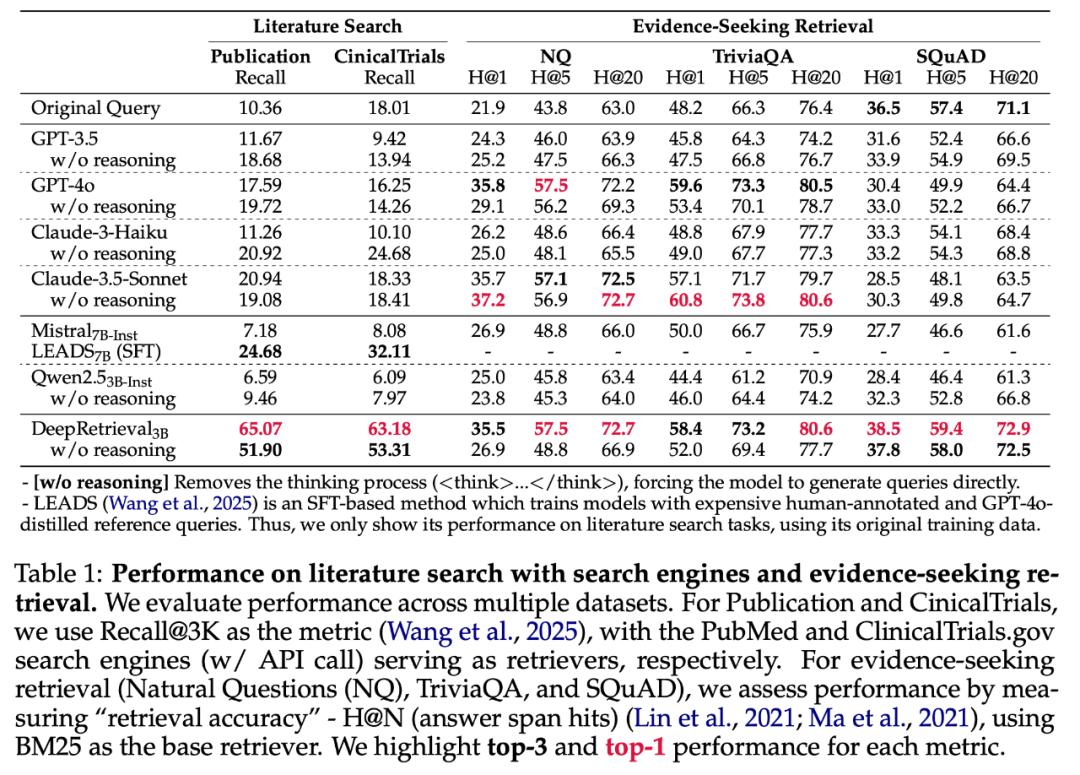
DeepRetrieval 在 Evidence-Seeking 检索任务上的表现很优异,这令人瞩目。从表 1 可以看出,它结合了简单 BM25 后,这个只有 3B 参数的模型在 SQuAD、TriviaQA 和 NQ 数据集上超越了 GPT-4o 和 Claude-3.5 等大型商业模型。
Evidence-Seeking 任务的核心在于找到能够支持特定事实性问题答案的准确文档证据。在通用搜索引擎的环境里,这一能力具有极为关键的作用。作者团队明确指出,把 DeepRetrieval 运用到 Google、Bing 等通用搜索引擎的 Evidence-Seeking 场景中,将会带来明显的优势。
作者团队称会把这部分的延伸当作 DeepRetrieval 未来主要的探索方向之一。
Classic IR(Sparse / Dense)

DeepRetrieval 在 BM25 和 dense retriever 的作用下,提供了平均 5 到 10 点的 NDCG 提升。同时,BM25 加上 DeepRetrieval 与多数 dense baseline 的水平较为相近。
结合极快的检索速度,BM25 检索需 352s,而 dense 检索需 12,232s,展示了一个现实可部署且性能不俗的高效方案。
SQL 检索任务
在 SQL 检索任务里,DeepRetrieval 不再依赖 groundtruth SQL 了。它直接运用生成 SQL 的执行成功率来优化模型,通过生成更精确的 SQL 语句,从而让模型在 Spider 数据集和 BIRD 数据集等上的执行正确率都超过了对比模型,这些对比模型包括 GPT-4o 和基于 SFT 的大模型。
探索胜于模仿:RL 为何超越 SFT
DeepRetrieval 的实验表明了强化学习(RL)在搜索优化方面相较于监督微调(SFT)具有独特的优势。实验数据具有很强的说服力。在文献搜索方面,RL 方法的 DeepRetrieval 达到了 65.07%,比 SFT 方法 LEADS 的 24.68%高出近三倍;在 SQL 任务中,通过从零开始进行 RL 训练(这种训练不需要任何 gold SQL 语句的监督)的效果要优于使用 GPT-4o 蒸馏数据的 SFT 模型。
这种显著差异的缘由在于两种方法存在本质区别:SFT 属于“模仿学习”,其目的是复制参考查询;而 RL 属于“直接优化”,通过环境反馈来学习最优查询策略。SFT 方法存在局限,即参考查询本身或许并非最优,即便对于人类专家或大模型来说,也难以直接设计出最适合特定搜索引擎的查询表达。
论文中的案例分析进一步证实了这一点。在 PubMed 搜索时,DeepRetrieval 生成的查询像“((DDAVP)且(围手术期程序或输血或去氨加压素或抗凝剂))且(随机对照试验)”,它融合了医学领域的专业词汇以及 PubMed 搜索引擎所偏好的布尔结构,这种组合是很难通过简单地模仿预定义的查询模板而获得的。
RL 能够让模型借助尝试与错误去探索查询空间,进而发现人类未曾考虑到的有效模式,并且可以直接针对诸如 Recall 或执行准确率这样的最终目标进行优化。这样一来,DeepRetrieval 就能够生成非常适合特定搜索引擎特性的查询,还能适应不同检索环境的独特需求。
这一发现带来重要启示:在追求最佳检索性能的过程中,让模型通过反馈来学习如何与检索系统进行“对话”,这种方式比简单地模仿既定模式更有效。这也就解释了为什么参数量较小的 DeepRetrieval 能够在多项任务上超越那些拥有更多参数的商业模型。
模型 Think&Query 长度分析
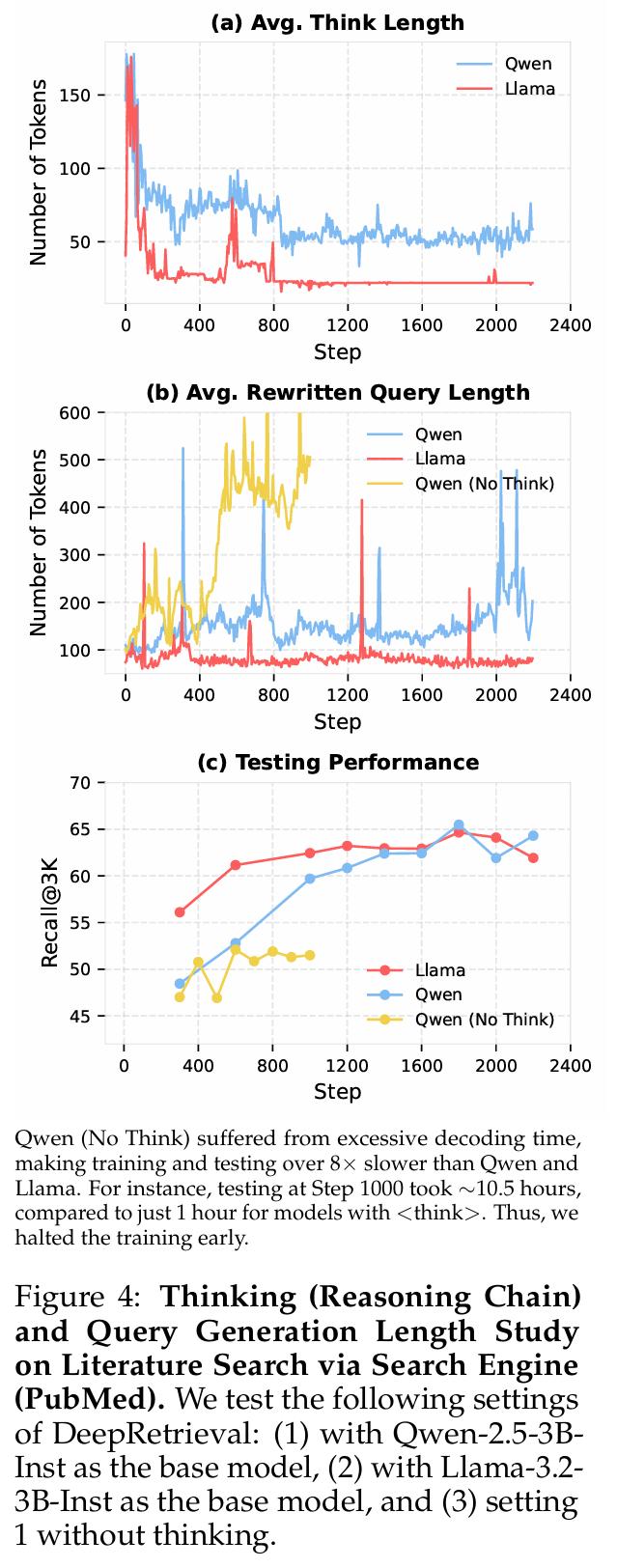
分析 DeepRetrieval 在训练过程中模型思考链的变化,能够发现一些关键情况;分析 DeepRetrieval 在训练过程中查询长度的变化,也能发现一些关键情况;综合来看,可以得出以下关键洞见。
思考链长度演变
DeepRetrieval 的思考链长度在训练过程中是呈下降趋势的,而不是增长趋势,这与“aha moment”的情况相反。DeepSeek-R1 报告了“aha moment”现象,其思考链会随着训练的进展而变得更长,这与 DeepRetrieval 形成了鲜明的对比。图 4(a)展示了 Qwen 模型的思考链有一个变化过程,从最初大约 150 tokens 逐渐下降,最后稳定在 50 tokens 左右。同时,Llama 模型的思考链较短,甚至能降至接近 25 tokens 。
查询长度特征
实验表明思考过程对查询长度有着显著的影响。没有思考过程的模型容易停留在次优解上。从图 4(b)可以看出,Qwen 的无思考版本会生成极长的查询,长度在 500 - 600 个 tokens 之间,并且表现出过度扩展的趋势。相比之下,模型在有思考过程时会保持较为适中的查询长度。其中,Qwen 的查询长度约为 150 tokens,Llama 的查询长度约为 100 tokens。有趣的是,不同的模型采用了不同的长度策略,然而却能够达到相似的性能,这表明在查询生成方面存在着多种有效的路径。
性能与思考过程关系
思考过程对检索性能起着决定性的作用。从图 4(c)可以看出,拥有思考能力的模型其性能有了显著的提升。具备思考能力的模型在 Recall@3K 方面能够达到 65%,然而没有思考能力的模型大约只有 50%。另外,训练效率也有了明显的提升,具备思考能力的模型能够更快地达到高性能并且保持稳定。论文附录 D.1 的分析显示,思考过程起到了这样的作用:它帮助模型避免仅仅通过增加查询长度以及重复使用术语的方式来提升性能,同时引导模型去学习更为有效的语义组织策略。
关键结论
DeepRetrieval 表明思考过程在信息检索里起着“探索促进器”的重要作用。数学或编程问题与检索任务不同,检索任务不需要像“aha moment”那样突然顿悟。检索优化遵循“先详细思考,后逐渐精简”的模式,模型内化有效策略后,就不再需要冗长的思考了。这表明在检索任务中,思考链的主要功能在于进行探索。当策略变得稳定之后,便可以对其进行简化。
这种分析表明,思考过程设计适当是很重要的。它对于构建高效的检索优化系统至关重要。通过这种设计,在不增加模型参数的情况下,能够显著提升性能。这为未来的 LLM 应用于搜索任务提供了重要的设计思路。
结论
DeepRetrieval 的贡献在于揭示了一个重要事实,这个事实常被忽视但却很关键:检索效果的上限不仅仅取决于检索器自身,还取决于如何进行“提问”。
强化学习用于教 LLM 改写原始查询。DeepRetrieval 摆脱了对人工标注数据和大模型蒸馏的依赖。DeepRetrieval 在多个任务上证明了改写 query 的巨大潜力。这项工作为搜索与信息检索领域带来新思考:未来检索优化,不仅要提升引擎算法,还要让用户“问得更好”,以激发出检索系统的全部潜力。
本文来自微信公众号“机器之心”,36氪经授权发布。
