图灵奖得主杨立昆觉得,当下 AI 界一直追捧的大语言模型并非完美无缺。它存在着四个难以突破的致命弱点,其一为理解物理世界;其二为拥有持久记忆;其三为具备推理能力;其四为复杂规划能力。
而能够克服第一个“致命弱点”的技术,叫作世界模型。

这或许听起来较为抽象。然而,你必定知晓谷歌所开发的 3D 游戏,以及特斯拉所具备的自动驾驶功能。
世界模型意味着机器能够辨别物理空间,如同人一样;能够理解物理规律,就像人那样;还能够根据经验做出推理决策,和人一样。
世界模型与大语言模型不一样,它不再依照从海量文本语料生成概率的那种逻辑,而是在对大规模现实世界视频进行深度分析之后去推测因果。
就像人类世界的婴儿一样,在交互学习中构建对这个世界的认知。
从零到一,世界模型源于人类心智
想象一个刚出生的婴儿,她的眼睛还未完全聚焦。然而,她却能够通过触摸、感受温度以及聆听声音的碎片,来拼凑出世界的轮廓。人类大脑历经数百万年的进化,才拥有了这种将感官信息转化为对物理规律理解的能力。
这正是今天的人工智能所欠缺的,世界模型正在努力去做的事情——从数据里重构对重力以及时间等知识的理解。
世界模型的概念最早可追溯至 1980 年代到 1990 年代的认知科学与控制理论领域。在那个时期,研究者受到心理学的影响,提出 AI 系统需要构建对环境的内部模拟,以此来进行预测和决策,也就是 AI 的环境建模能力。
这里有一个重要的要素:环境。
从生物学角度而言,微生物、动物以及人,其行为都遵循着一个最为基本的规则。这个规则就是刺激-反应模式,也就是说生物的反应是对环境刺激的直接回应。

生物经历了千亿年漫长的进化过程。在这个过程中,动物发展出了感觉和心理。它们通过视觉、听觉、嗅觉等感官来感知外界。并且,在感知外界的过程中,会产生出兴奋、恐惧等简单情绪。人类进一步发展出了自我意识。人类意识和动物感觉最大的区别在于,人类能够自主规划,并且有目的地进行决策和行动,而动物则不能。
将生物进化过程与 AI 的发展历程进行比较,我们可以轻易地察觉到,AI 的终极形态 AGI 实际上是要具备自主感知现实的能力、自我规划的能力以及有目的决策的能力。
心理学家对人类和动物认知理解世界并做出决策进行了观察,世界模型的雏形由此萌芽。1990 年,David Rumelhart 提出了一个叫作心智模型的理论,该理论强调智能体需对环境形成抽象表征。
以自身为例,人类大脑拥有一种习得的内在认知框架,会依据经验来做决策,像看到乌云就会联想到下雨。另外,我们不会去记住每片树叶的形状,却能够立刻判断树枝能否承受体重。同样的道理,世界模型就是让机器构建起对周围环境以及世界的理解和预测能力,例如看到火就会联想到烫伤。这种抽象能力,正是这一时期学者希望机器具有的禀赋。
这阶段的世界模型研究处于理论构想阶段。它虽然有了较为清晰的定义和目标,然而却没有具体的技术路径。

世界模型研究在 2000 年代到 2010 年代进入计算建模阶段并开始落地。随着强化学习和深度学习不断深入发展,学者们开始尝试利用神经网络来构建可训练的世界模型。
强化学习在与环境交互期间,借助奖惩机制不断习得策略,这种方式类似“训狗”;深度学习通过分层特征提取,能够从海量数据里自动学习规律,此过程类似“炼金”。
2018 年,DeepMind 的《World Models》(作者为 Ha 和 Schmidhuber)论文。该论文首次运用“VAE + RNN + 控制器”的三段式架构,构建出能够预测环境的神经网络模型。此模型成为现代世界模型的一个重要里程碑。
这一过程类似“造梦”。首先,通过自动编码器 VAE 把现实场景压缩成数据。接着,利用 RNN 循环神经网络来推演未来可能的情节。最后,用精简的控制器指导行动。这表明世界模型首次拥有了颅内推演的能力,能够像人类那样在行动前预判后果,从而大大降低了试错成本。
2022 年之后,世界模型迈入了大模型时代。凭借着 Transformer 的序列建模能力以及多模态学习技术,其应用范围从单一模态拓展到了跨模态仿真。同时,世界模型的推演也从 2D 发展到了 3D,例如 OpenAI 的 GATO 和 DeepMind 的 Genie 等。

近期的一些研究,像 meta 的 VC-1 以及 Google 的 PaLM-E,进一步把世界模型的概念带到了公众的视野之中。并且,将世界模型和大语言模型相结合,以此来实现更具通用性的环境推理,已经成为了一种技术发展的路径。
Google 的 PaLM-E 模型(参数达 5620 亿)成功把语言模型和视觉、传感器数据等物理世界信息相融合。机器人能够明白复杂的指令,像“捡起掉落的锤子”这样的指令,并且能够适应新环境去执行任务。meta Llama 系列有开源的多模态框架,比如 MultiPLY,它进一步推动了对物理环境的 3D 感知方面的研究。
由此可见,从概念开始逐步推演出落地实践的过程中,世界模型在不断地摸索前行,逐渐地在发展中走出了一条从最初的混沌状态到后来变得清明的道路。
由虚拟入现实,世界模型大有可为
Transformer 架构在不断进化,多模态数据也在大量爆发。这使得世界模型从训练场中走出,进入到游戏场里,接着又迈向了真实世界。谷歌凭借其技术生成了极为逼真的游戏场景;腾讯通过自身的力量生成逼真的游戏场景;特斯拉利用神经网络来预测车辆的轨迹;DeepMind通过建模来预测全球的天气。
就这样,世界模型在实验室中开始了它的探索之路,它就像蹒跚学步的孩子一样。它开始对现实物理规律进行探索。
人类幼年通过游戏来感受规则并完成社会化,就如同世界模型的第一关也是游戏一样。
初期的模型应用依靠规则明确的虚拟环境以及边界清晰的离散空间,像 Atari 游戏(DQN)、星际争霸(AlphaStar)等。在这个阶段,采用的是表格型模型(如 Dyna)。到了后期,就结合了 CNN/RNN 来处理图像输入。

进化到 3D 版后,谷歌 DeepMind 的 Genie 2 具备这样的能力:能够通过一张图片生成可交互的无限 3D 世界,这个 3D 世界的时长达到 1 分钟,用户可以在其中自由地探索动态环境,比如地形的变化以及物体的互动。腾讯、港科大和中国科大联合推出了 GameGen-O 模型,这个模型能够一键生成西部牛仔、魔法师、驯兽师等游戏角色,同时也能够以更高保真度以及更复杂的物理效果来生成海啸、龙卷风、激光等各种场景。
经过大量训练后,世界模型由游戏过渡到工业场景。
游戏引擎的核心能力是构建高保真且可交互的 3D 虚拟环境。这种能力被迁移到了工业场景中,用于模拟工业场景中可能出现的各种复杂故障场景。

机器人公司波士顿动力会在虚拟环境里预演机器人的动作,像摔倒恢复这类动作,然后将其迁移到实体机器上;特斯拉在 2023 年提出的世界模型把游戏引擎的仿真技术直接整合了进来,通过合成数据来训练自动驾驶系统,从而减少对真实路测数据的依赖;蔚来的智能世界模型可以在极短的时间内推演出数百种可能出现的情境,并且能够做好预案和决策。
最近,世界模型还走进了基础研究领域。
DeepMind 的 GraphCast 凭借世界模型来处理百万级的网格气象变量。它预测天气的能力比传统数值模拟快很多,快了 1000 倍。并且能耗也降低了很多,降低了 1000 倍。它通过图神经网络架构,能够从历史再分析数据中直接学习天气系统的复杂动力学,从而精准且高效地预测全球天气。
世界模型的本质在于通过大量多模态资料来理解物理世界的规律,涵盖从游戏般的虚拟场景到自动驾驶等现实场景。未来,“世界模型+大语言模型”或许会成为 AGI 的核心架构,使得 AI 不但能够聊天,还能够真正理解并做出决策以改变现实世界。
我们为何需要世界模型呢?在大语言模型在全球范围内火爆的当下,是什么使得它显得不可替代呢?
从概率到因果, 我们为何需要世界模型?
让 AI 从模仿表征迈向感知本质的关键在于:让它切实理解这个世界,知晓现实空间与物理规律,从而明白它为何要做这件事,而非仅仅依据海量数据的关联概率去推测下一个 token 是什么。
基于大规模文本语料的大语言模型做不到,不断试错优化寻找最优路径的强化学习也做不到,只有世界模型能做到。
传统 AI 是以数据为驱动的被动反应系统。世界模型构建了内部虚拟环境,从而理解了物理、碰撞等现实规律。它能够像人类那样通过想象来预演行动的后果,并且在游戏、机器人等领域能够共享底层的推理算力。
首先构建出跟人类一样的心智模型是通过底层建模和多模态整合来实现的。在外部,世界模型不但模拟物理规律,还努力去理解社会规则和生物行为,以此在复杂场景中能够趋利避害。在内部,世界模型依据感知、预测、规划和学习的协同作用,形成了与人类心智类似的时空认知能力。

其次是因果预测以及反事实推理的能力。世界模型凭借当前的状态和行动,能够对未来的演变结果进行预测。它拥有类似人类的常识库,能够填补缺失的信息,并且进行反事实推理(what if),即便没有直接观察到某一事件,也能够推断出“如果采取不同的行动将会怎样”。这种能力具备在数据稀缺的情况下依然能够有效进行决策的特点,能够减少对海量标注数据的依赖,并且在自动驾驶领域得到了较多的应用。
首先,世界模型通过自监督学习来构建对世界的通用表征。其次,它由此获得了跨任务、跨场景的泛化能力。而传统模型通常的做法是针对特定领域的具体任务进行微调。
但是,这些能力,为什么火极一时的大语言模型做不到呢?
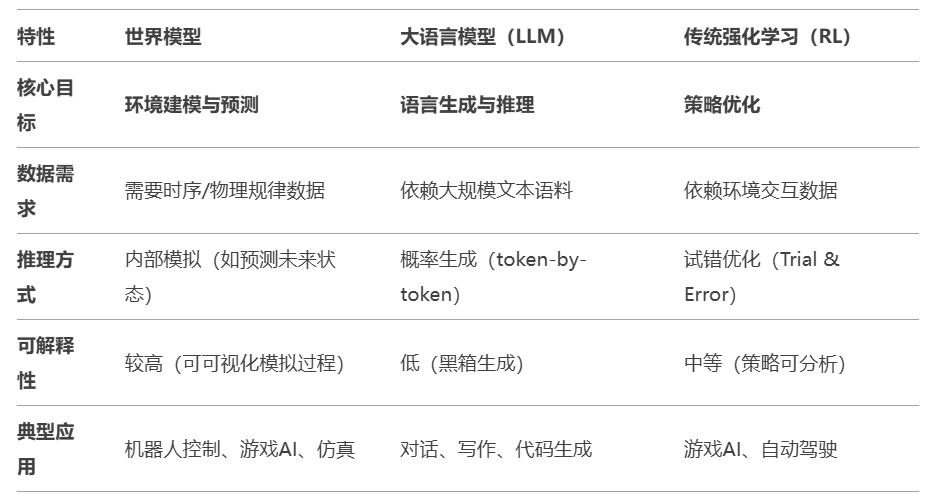
要弄清楚世界模型的预测能力与大语言模型的推测 token 能力为何不同,我们得弄清楚一个概念,那就是相关性和因果性是不一样的。相关性指的是概率关联,而因果性指的是因果推理。
大语言模型,像 GPT 系列这类,重点在于大数据驱动的自回归学习。它通过大量的文本数据来训练模型,从而生成文本。其本质是对概率进行预测。而世界模型学派则认为,自回归的 Transformer 无法通向通用人工智能(AGI)。AI 必须具备真正的常识性理解能力,而这些能力只有通过深入分析大量的照片、音视频等多模态数据,对世界的内在表征进行获取才能获得。
大语言模型在模型结构层面主要依赖 Transformer 架构,利用自注意力机制来处理文本序列。世界模型包含诸多模块,像配置器、感知、世界模型以及角色等,它能够对世界状态进行估计,对变化进行预测,还能寻找最优方案。
通俗来讲,大语言模型训练出的文本具有一定才能,但如同纸上谈兵的文将,可能对常识一无所知。而世界模型则更像是在建模环境中历经诸多战斗的武将,能够凭借直觉和经验来预判对手的出招方式。

世界模型虽前景可期,目前依然面临着一些瓶颈。
在算力方面,训练世界模型所需的计算资源比大语言模型要大得多,并且存在“幻觉”(错误预测)的问题;在泛化能力方面,怎样平衡模型的复杂度与跨场景的适应性仍然需要取得突破;在训练集方面,多模态的数据规模相对较少,而且需要进行深度标注,对质量的把控是最为重要的。
大语言模型类似 GPT 已到能言善辩的青春期,而世界模型实则处于牙牙学语的幼年期。
总的来讲,世界模型是不同于深度学习的另一条探索途径。若未来深度学习遭遇发展瓶颈,那么世界模型或许可作为一种备选办法。然而在现阶段,世界模型还处于探索阶段,我们仍需把重点放在大语言模型与深度学习这条技术线上。
多点发力,协同并进,才能让AI的成长有更多道路可走。
本文来自微信公众号 ,作者:珊瑚,36氪经授权发布。
