顶会论文进行评审时,AI发挥了重大作用!ICLR 2025 首次将 AI 大规模引入到审稿工作中,最终有 12222 条建议被审稿人采纳,在 89%的情况下提升了评审的质量。一份详细的 30 页报告,揭示了 AI 在顶会审稿方面的惊人潜力。
你的审稿意见,可能是AI帮忙写的!
去年 10 月,ICLR 2025 开始了正式的审稿周期。它甚至指定了大模型来参与评审。
那么,AI参与的审稿如何了?
今天,ICLR 公布了相关结果。AI 智能体参与了这届审稿。12222 条建议被审稿人采纳了。这极大地提高了评审的质量。

他们公开了一份 30 页的详细报告,这份报告介绍了在整个实验过程中,AI 在学术评审方面所具有的巨大潜力。

论文地址:
研究中,得出了几个关键结果:
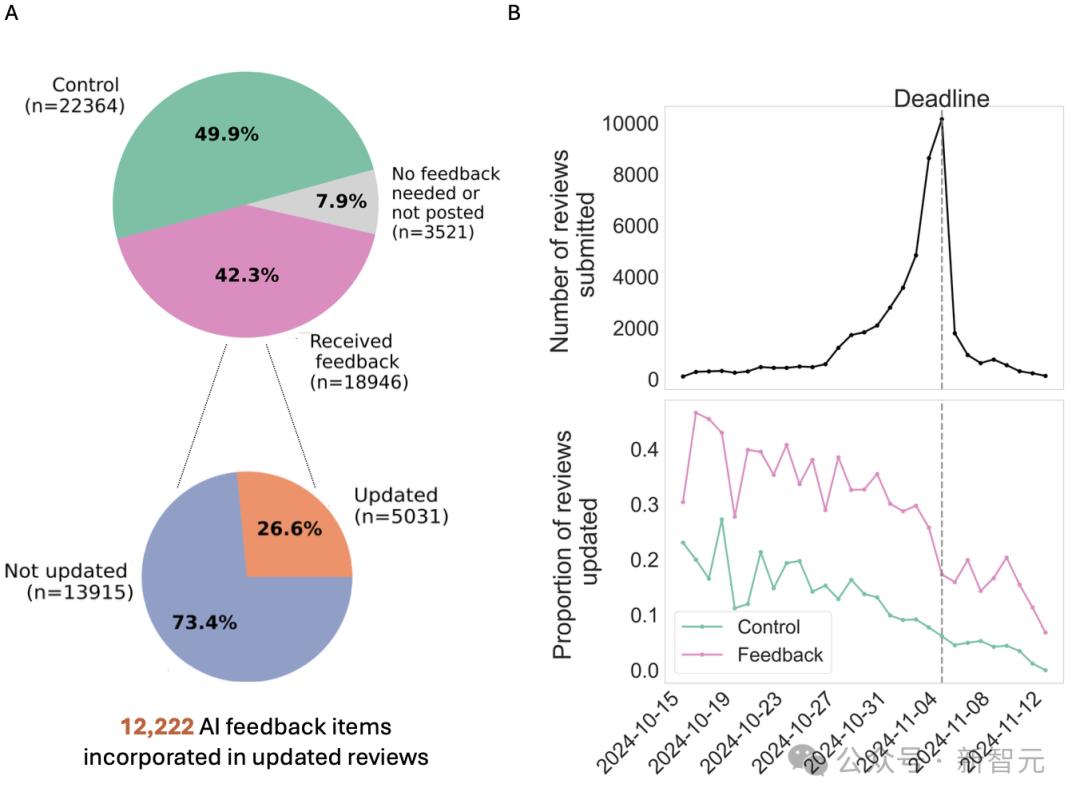
有 12222 条具体建议被采纳了,并且 26.6%的审稿人依据 AI 的建议对评审进行了更新。
LLM反馈在89%的情况下提高了审稿质量。
接受 LLM 反馈并予以接收的审稿人,若其审稿意见平均增加 80 个字,就能够提供更丰富的反馈。
在 Rebuttal 期间,讨论的活跃度得到了显著提升,变得更加深入且有效,作者的 Rebuttal 篇幅增加了,审稿人的回应篇幅也增加了。
最终论文的录用结果方面,反馈组和对照组不存在显著差异。AI 智能体对作者与审稿人之间的讨论进行了优化,此结果符合其设计目标。
AI参与审稿,首次被顶会认可
ICLR 是当前众多 AI 顶会里的一个会议,它是唯一一个允许 AI 参与审稿的会议。在此之前,CVPR 2025 发布了一项政策,明确规定禁止使用 LLM 参与审稿。
那么,ICLR组委会为何会采纳AI建议呢?
要知道,同行评审是研究和创新的关键要素。
然而,论文投稿量在迅速增长,尤其是在 AI 顶会上。同行评审面临着压力,且这种压力日益严峻。
低质量的反馈使得作者们的不满与日俱增,同时也影响了学术交流的效率。在 2023 年 ACL 上,作者们指出有 12.9%的评审质量不好,而导致这种情况的主要原因就是这些模糊且流于表面的批评。
此外,存在审稿人被分配到其专业领域之外的论文这一情况,还有高拒稿率使得同一篇论文被反复评审等问题,这些都给同行评审系统带来了更大的压力。
如何去提升评审质量,也就成为了学术界关注的热点。
部分审稿人会借助 LLM 来分担自身的压力。据估算,在 ICLR 2024 这一活动中,大约有 10.6%的审稿人借助 LLM 来辅助完成评审工作。
统计显示,ICLR 每年提交的论文数量呈逐年上升的态势。2025 年一共收到了 11,603 篇投稿,相较于上一年度增长了 61%。ICLR 在 2024 年同比增长了 47%。

去年,ICLR 2025 为了提升审稿质量,给每位审稿人分配的论文数量最多为 3 篇。

他们引入了“评审反馈智能体”(Review Feedback Agent),此举使得 AI 能够识别审查过程中出现的问题,并且可以向审稿人反馈改进的相关内容。

AI智能体就审稿中可能存在的三类问题,提供建议:
鼓励审稿人改写含糊的评论,让其对作者更具可操作性;
突出文章中可能已经回答了审稿人一些问题的部分;
在评审中,发现并处理不专业、不恰当的言论。

在该实验里,反馈智能体借助多个 LLM,给审稿人提供能针对其评审内容进行优化的建议。
这些建议是精心设计的,它主要聚焦在提升评审的信息量方面,同时也聚焦在提升评审的清晰度方面,还聚焦在提升评审的可操作性方面。
团队为确保反馈的可靠性,引入了基于 LLM 的可靠性测试(Reliability Tests),通过该测试对 AI 反馈的特定属性进行评估,以确保其质量。
42.3%评审,AI都有参与
这项试点研究是由 ICLR 与 OpenReview 联手开展的。今年的顶会审稿工作中,这项研究全面铺开了。
他们构建了一个系统,这个系统由 5 个大语言模型协作而成,并且以 Claude Sonnet 3.5 为核心模型,用于生成高质量反馈。
ICLR 今年收到了 11,603 份投稿,这些投稿被平均分配给了 4 位审稿人,每位投稿都有 4 位审稿人负责。
审稿人要按照 1 到 10 分的等级来进行评分,并且依据以下这些维度对论文展开评价:其一是合理性,其二是表述,其三是贡献,其四是评分,其五是置信度。
2024 年 10 月 15 日到 11 月 12 日这四周时间里,AI 智能体为 18946 份被随机选取的 ICLR 评审提供了反馈,这些评审占 ICLR 2025 总评审量的 42.3%。
ICLR 2025 收到了 11,553 篇独立论文,这些论文有 44,831 份有效评审。最终,大概有一半的评审被随机选中,用于接收反馈。
有不到 8%的被选中评审没有收到反馈。原因有两个:一是 2,692 份评审自身质量很高,所以不需要反馈;二是 829 份评审生成的反馈未能通过可靠性测试。

平均每份评审通过整个处理流程所耗费的时间大约是 1 分钟,其成本大概为 50 美分。平均来看,每份收到反馈的评审包含的反馈意见数量在 3 到 4 条之间,最少有 1 条,最多能达到 17 条。
生成的反馈主要聚焦于降低模糊性和缺乏依据的评论,并且也会处理对内容的误解以及不专业的表述。
评审期间,审稿人有两种选择,一是可以选择忽略 LLM 的反馈(这种反馈被标记为「未更新」),二是可以据此修改评审(这种修改被标记为「已更新」)。并且该系统不会进行任何直接更改。
实验结果 17%审稿人更新,评审平均增加80词
如下图展示的那样,收到反馈的评审,其更新的可能性比未收到反馈的评审要高 17%。
提交评审早的审稿人,比提交晚的更可能进行更新,这显示出更有条理且更投入的审稿人更倾向于依据反馈给出修改意见。
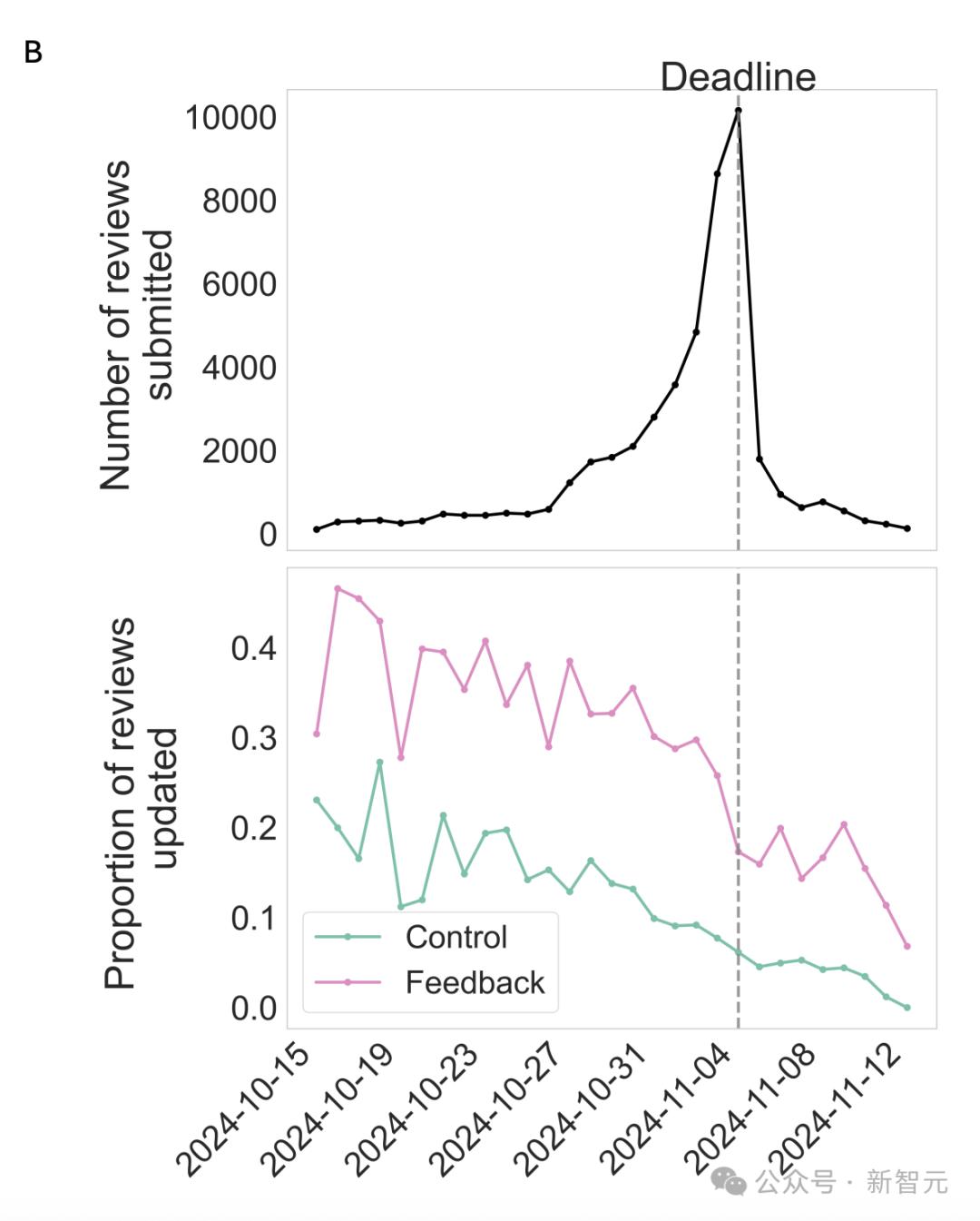
评审长度分析显示,所有组的最终评审长度均增加。
反馈组比对照组平均多增加的词数约为 14 个。不过,由于部分反馈组没有进行更新或者实际上没有收到反馈,所以效应量偏低。
收到反馈后进行了评审的更新,其长度有显著增加,平均达到 80 词,远远超过了未更新的那一组,未更新组平均仅增加 2 词。
这表明,更新者更倾向于实质性编辑,加入更多细节。

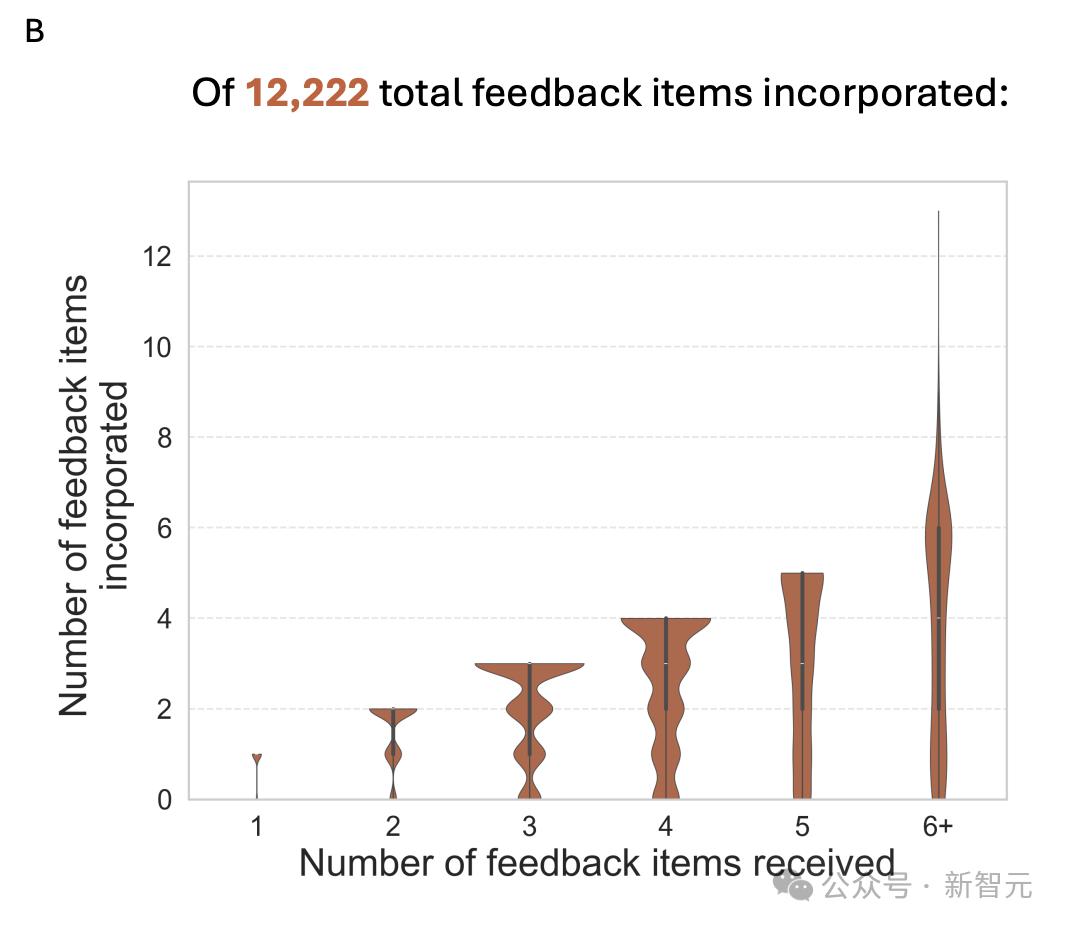
12222条AI建议被采纳
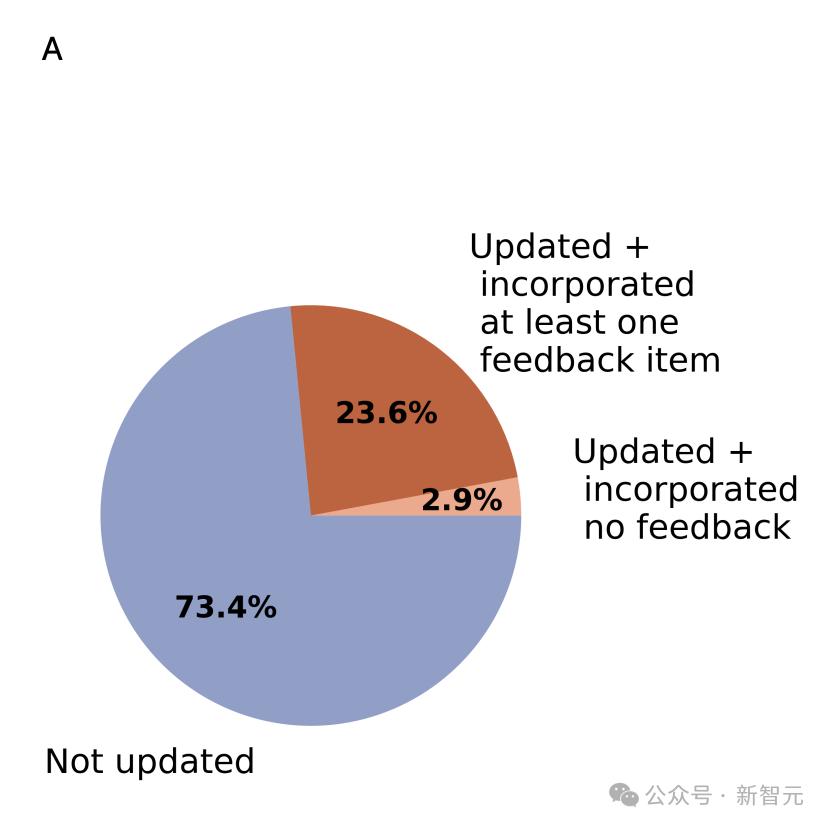
在对 5,031 份评审(总计 18,322 条反馈)进行 Claude Sonnet 3.5 分析后发现,89%的评审者至少采纳了一条反馈,并且这些采纳反馈的评审者占收到反馈评审者的 23.6%。
估计共有 12,222 条反馈项被采纳了,这些反馈项被融入了修订后的评审意见中。
分析表明,审稿人反馈数量少的话,更有可能采纳全部反馈。其平均采纳率是 69.3%,也就是说,收到 3 条反馈的审稿人,平均会采纳 2 条。
团队邀请两名 AI 研究人员对 100 个样本对(初始与修改后评审)进行盲偏好评估,目的是评估采纳反馈评审是否清晰、具体、可操作。
结果显示,89%的情况是修改后评审更受偏好,这表明采纳反馈能够显著提升评审质量。
作者审稿人参与度更高了
接下来,研究人员分析了“被选中接收反馈”这一情况。这种情况对反驳过程产生了影响,同时也对论文录用率产生了影响。
反驳期的时间是从 2024 年 11 月 12 日开始一直到 12 月 4 日结束。在这段时间里,作者能够对评审的评论进行回应,并且还可以修改论文。

结果显示,反馈组(审稿人接收反馈)的论文,其作者的反驳篇幅比对照组长。长了约 6%,大概 48 词,这表明作者的参与度更高。
一方面,反馈组审稿人回应反驳的回复比对照组长 5.5%左右,约 6 个词;另一方面,反馈组修改评分的比例比对照组长更高,为 31.7%对 30.6%,这使得审稿人参与度得到了提升。
