但很快,聂凯旋就感受到了市场的残酷。
“失去”的两年半
成立3年,松应科技共完成两轮融资。
2022 年 8 月,松应科技宣布获得了数百万美元的种子轮投资,并且是由红杉资本作为领投方。2025 年 3 月,松应科技又宣布获得了数千万元的天使轮融资,领投方是中科创星。
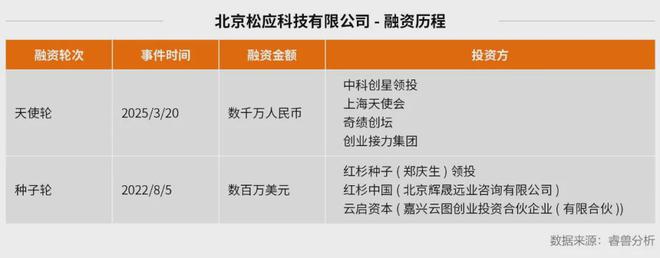
从种子轮到天使轮,松应科技用了两年半。
2021 年,松应科技成立。当时,实时三维物理仿真的概念十分“科幻”,这让投资人很难理解。聂凯旋能告诉投资人的,只有“这件事美国芯片巨头英伟达也在做,我们要做出中国自己的成果”。
当时,GPT 尚未发布,英伟达也尚未登上万亿美元的宝座,对标英伟达的那个故事还不足以真正打动投资人。“全球只有英伟达在做,其他大厂都没有跟进,会不会是这个方向错了呢?”类似的疑问,聂凯旋至少被问了几十次。
聂凯旋只能用CUDA的发展历程作类比。
2006 年英伟达发布了 CUDA。当时,几乎所有人都无法理解它。这个 CUDA 是用于进行并行计算的平台。大家都在疑惑,它与 GPU 主攻的图形渲染(像游戏、3D 建模等)有怎样的关系。并且,也不认可芯片公司去做基础软件平台。
2012 年时,深度学习浪潮使得大量算力需求得以催生。英伟达的 GPU 与 CUDA 成为众多 AI 从业者的最佳开发平台。自此之后,市场对 CUDA 的质疑便自然而然地消散了。如今,CUDA 已然成为英伟达在拓展领域时的最为强大的宝剑,同时也是其最为深厚的护城河。

聂凯旋相信,因此 Omniverse 所代表的这种实时物理 AI 仿真技术将会迎来属于它自己的时代。
在 2021 年这个时间点,市场上较为活跃的两个技术概念为 CV(计算机视觉)和元宇宙。在泡沫的影响下,其他的技术路径和声音大多被掩盖了,许多人甚至直接把 AI 和 CV 视为等同的。然而,当 CV 四小龙遭遇商业化瓶颈,元宇宙因落地场景不明确而逐渐从资本舞台淡出时,松应科技的成立就显得有些不太合适了。
当时我们向投资人阐述“AI 驱动数字与物理世界”这一理念,许多人要么觉得我们是在做不切实际的幻想,要么认为我们没有跟上时代的步伐。聂凯旋还记得,公司在 2022 年 6 月完成了种子轮的交割事宜,然而在 8 月公布融资消息之后,仍有投资人表示不解,他们问道:“都已经到 2022 年了,你们为何还在讲述关于 AI 的故事呢?”
2022 年 11 月之前,国内市场对 AI 的热情未被点燃。到了 2022 年 11 月,GPT 让国内市场对 AI 的热情再次被点燃。
只是,2023 年几乎都被“百模大战”的狂热情绪所笼罩。在“FOMO”心态的影响下,有一些投资者存在“为了投 AI 而投 AI”的行为。GPU 厂商、算力中心、AI Infra 厂商作为“卖铲子”的角色,也顺着模型的热潮而被投资者捧在手心。相比之下,做软件的企业几乎被置于耻辱柱之上,人们认为它们处于大模型食物链的最底端,技术含量较低,很难构建起壁垒。
进入 2024 年之后,市场对于大模型的讨论开始逐渐回归到实际层面。越来越多的人渐渐意识到,大模型不应该仅仅停留在互联网时代所遗留下来的商业故事当中,而是应该更多地迈向物理世界。
2024 年 10 月 17 日,特斯拉发布了一个视频。这个视频展示了擎天柱在工厂里具备自主充电的能力,同时也展示了它在工厂里工作的能力。这标志着“用 AI 驱动机器人”的想象变成了现实。2025 年 3 月 18 日在英伟达 GTC 大会上,黄仁勋把 AI 技术的发展划分成三个阶段,分别是生成式 AI、代理式 AI 和物理 AI,同时他指出物理 AI 将会成为未来的核心发展方向。
两位科技狂人的定调,在全球范围内加快了 AI 进入物理世界的步伐。聂凯旋表示,几乎所有人都意识到,AI 应当更广泛地应用于物理世界,而不是仅仅停留在互联网上,也不能只停留在机械臂、机器人关节、传感器等单一的硬件设备上。他还指出,数据和软件将是物理 AI 竞争的核心。

松应ORCA - 国内首个物理AI仿真系统
模型能力的升级就如同军备竞赛一般。厂商必须持续投入资金,才能够对模型进行持续训练和迭代,不然的话,模型的价值就会变为零。然而,基础软件则有所不同,像多物理综合仿真引擎这类软件开发完成之后,只要它能够解决实际问题,就能够体现出自身的价值。聂凯旋做出了这样的表示。
只是,在国内的资本市场方面,做软件一直不是一个被视为“好故事”的事情。早期的信息化系统如此,后来的 SaaS 服务也是如此。软件公司在赚钱方面,多少都带有一些“费力不讨好”的意味。
在国内商业环境中,松应科技借助英伟达的故事而被市场所关注。然而,要真正让客户通过实际行动来选择,它面临的挑战比英伟达早年还要大。
聂凯旋表示,他十分感激那些愿意相信松应科技愿景的投资人们。同时,他也清楚,只有做出能够被市场认可的产品,公司四周弥漫的质疑声才能够真正消散。
先模仿,再超越
公司成立之后,聂凯旋分别在北京组建了一支研发团队,在上海组建了一支研发团队,在深圳也组建了一支研发团队。
聂凯旋透露,将团队分布在三地主要有两层考虑。
一方面存在人才需求。要打造物理 AI 仿真系统,就需要 AI 算法人才、半导体人才以及基础软件平台人才这三类。这三类人才分别在北上深这三个地方有分布。北京更侧重于算法人才;上海更侧重于基础软件和工具人才;深圳则更偏重于处于更底层的半导体驱动软件、操作系统等软硬件结合方面的人才。
另一方面考虑到未来的潜在客户市场。聂凯旋称,无论是 AI 大脑还是智能机器人,北京、上海、深圳这三个地方无疑最先发展起来,会有大量公司和创业团队诞生。这些企业都有成为松应科技潜在客户的可能。
不过,这支团队的首要任务,还是攻克技术难关。
松应科技选择了“先模仿,再创新”的途径,将英伟达的技术指标作为对标对象,以月为周期来进行技术的迭代。在潜心研发的这三年时间里,松应科技并没有“独自进行研发而不与外界交流”。
2023 年起,松应科技开始在市场寻觅合作伙伴。它检验了各个系统模块的能力,像 3D 渲染引擎、实时数据管线、物理仿真与传感器模拟、AI 生成等已有的产品模块。然后,根据反馈进一步对技术和产品细节进行调整。
2023 年下半年,松应科技的产品模块完成了 70%-80%左右。之后,它尝试去寻找各种机器人公司,这些公司涵盖了仓储物流、送餐、酒店等多种不同的场景,并且有 AGV、AMR 等多种不同的形态。接着,松应科技开始了真正的“实战演练”。
在“开发 - 验证 - 迭代 - 再验证”的这个循环当中,松应科技有过那样的时刻,就是把所有的东西都推倒重新来过。聂凯旋说:“要是存在架构性的错误,无法达到我们预先设想的效果,那就只能够推倒重来。”
2024 年 6 月,松应科技终于开启了为期六个月的公测期。聂凯旋给团队设定了目标,要在这六个月当中找到真正具备实力的种子用户,与用户一同打磨产品,为后续的大规模商业交付进行准备。
8 月的时候,松应科技宣布推出了他们自主研发的“物理 AI”仿真训练平台 Orca。Orca 平台整合了 CAD/CAE 工业软件等多种技术,构建了多种类高精度仿真环境。它能够实时模拟多种物理效应,如刚体动力学、流体力学、重力、摩擦力、真实感光照、触觉等。同时,还能生成高精度多模态数据。

ORCA 具有物理仿真模块,此模块能够支持多物理场的实时仿真,图片的来源是松应科技。
松应科技在打造 Orca 的过程中,积累了诸多高质量数据。这些数据大致可分为两类:一类是通过场景建模或扫描而得到的真实物理三维数据;另一类是依据场景需求,结合松应科技的 3D 模型库,由 AI 合成的各类场景数据。
这些数据都运用 OpenUSD(通用场景描述)这种格式。聂凯旋觉得,未来人类若要模拟物理世界,就必须得有一套被标准化的数据语言,“要是语言不统一的话,这件事就很难得以做成”。
他目前认为最优的 3D 描述语言是 USD。USD 即通用场景描述,是一种标准化的开源 3D 描述语言,能够用于描述和模拟物理世界,是由英伟达、苹果、Autodesk 等公司联合发布的,和二维世界的 HTML 类似。
简单来看,在 FBX、OBJ、STL 等传统数据格式中,不同的软件以及不同的应用场景或许会使用不同的文件格式,这就使得数据难以实现通用。比如,STL 格式主要是用来描述三维物体的几何信息的,并且它不支持颜色、材质等相关信息。

到 2024 年时,OpenUSD 软件具备支持的生态体系,其来源为松应科技。
USD 格式具备分层叠加的特点,能够依据物体的形状、材质、颜色等特性进行分层,还可以单独对某一参数进行调整。其灵活性使得它在应对复杂的 3D 场景以及物理模拟时更具优势,并且有潜力成为模拟物理世界的通用数据语言。
2021 年松应科技刚成立的时候。它以 USD 格式为基础搭建了整个产品体系。它是国内最先引入该数据体系的研发团队。
聂凯旋认为,在理想状况下,在仿真系统和模型训练之间,需有数据闭环。这个闭环由专家(真机/仿真)示教数据、仿真系统合成数据以及真机微调数据按 1:8:1 的比例构成。即:有专家(真机/仿真)示教数据,有仿真系统合成数据,还有真机微调数据,且它们的比例为 1:8:1。
而松应科技的目标,则是打造一个数据驱动的物理AI仿真系统。
伴随需求而生
2024 年底,经过了六个月的公测期。之后,松应将基于 ORCA 2.0 正式开始商业化。
聂凯旋为此特意发送了一封内部信,向所有员工进行宣布。公司接下来将会正式步入商业化阶段,从过去三年的“技术导向”转变为“市场导向”。这表明,公司未来的产品形态会将重点放在围绕市场需求进行迭代上,并且最终会为商业客户提供服务。
有趣的是,到去年年底时,松应科技团队没有一位销售人员。其中,包括聂凯旋在内的几位核心创始人自己承担起了销售的角色。
聂凯旋觉得,只有公司的一号位以及核心成员首先对产品有充分的理解,并且把产品成功卖掉,产品才算是真正达到了能够进入市场的阶段,此时扩张销售团队才具有意义。“倘若我直接去找一个非常厉害的销售,也能够将产品卖出去,然而这或许会营造出一种假象,会让团队误以为自己所做的产品是不错的,进而反而丧失了持续进行迭代的动力。”
结果证明,聂凯旋的策略是有效的。
去年年底正式开始商业化,到现在才过了三个月。松应科技已有近 20 家商业客户,这些客户包含科技型央国企、国家级/省级机器人创新中心、具身智能厂商、高校以及科研院所等。聂凯旋坦言,在这些客户当中,有很多是在公测期以及之前产品验证时期积攒下来的种子客户,并且还有很多客户是从英伟达的系统转过来的。
聂凯旋称,松应 ORCA 现今在物理精度方面优于英伟达 Omniverse(简称 OV)。聂凯旋称,松应 ORCA 现今在综合成本方面优于英伟达 Omniverse(简称 OV)。聂凯旋称,松应 ORCA 现今在客户服务方面优于英伟达 Omniverse(简称 OV)。
松应科技的团队在仿真精度方面,开发了一套分布式异构计算系统。对于高并发且低精度需求的物理模型,会用 GPU 进行计算;对于高精度计算需求,则结合 CPU 高精度模块来计算。这样做既能保证效率,又能实现高精度。
ORCA Sim 具备物理仿真高效率的特点,并且其仿真精度比英伟达的物理引擎 physX(isaac sim 物理仿真模块)要高。比如,在国产 GPU 沐曦 C 系列卡上,松应 ORCA Sim 能够实现并行 4096 个机器人训练,这与英伟达 Omniverse isaac 的性能是相同的。
松应科技的团队为此开发了一套分布式异构计算系统。对于高并发且低精度需求的模型,会使用 GPU 进行计算;对于高精度计算需求,则使用 CPU 上的高精度模块来计算。这样做既能保证效率,又能实现高精度。
成本方面,松应科技Orca的成本仅为英伟达OV的1/3。
国内工程师红利使得人员成本大幅降低,这是一方面的原因。另一方面,国内数据采集和生产的成本比较低,所以国内公司在整体成本方面更有优势。
松应科技分布在北上深三地,其团队架构除了具备精度和成本方面的优势外,还能够为客户提供本地化服务。
很多客户先前使用英伟达的系统,一旦遇到问题,可能会卡顿一周时间,并且找不到人来进行解决,他们只能自己去逐篇消化技术文档。然而,我们能够直接派遣人员前往客户现场,在不到一个小时的时间内就有可能解决问题。聂凯旋如是说道。
目前,松应科技向客户交付的产品有三类。一类是 ORCA 物理 AI 仿真系统,另一类是三维高精度训练场,还有一类是机器人训练合成数据。
具体来看,松应科技已经拥有十个不同的类别,并且有上百套高精度的、处于物理准备就绪状态的三维数字训练场。

ORCA物理AI仿真数字训练场实录,图片来源:松应科技
在收费模式方面,ORCA 系统对企业客户是以年为单位收取 license 费用的。对于场景数据,是按套来收费的,比如说制作一个商场或者厨房的场景,会依据场景的复杂度以及细节的丰富程度来确定价格。而训练合成数据则是根据机器人需要完成的任务,以条为单位进行计算,其成本还不到真机采集数据的十分之一。
不过,松应科技已经开启了全新的商业化阶段,并且市场也迅速升温了。聂凯旋坦言,这只是阶段性地松了一口气,还没有到柳暗花明的时刻。
他认为,今天具身智能领域的热度与六七年前的自动驾驶相似。互联网大厂、汽车主机厂以及手机厂商都纷纷加入其中,并且有大量的创始团队涌现出来。与此同时,整个具身智能产业链还没有明确的分工,各个环节的业务边界也比较模糊。
与此同时,有大量的资本在向具身智能赛道涌入。聂凯旋表明,特别是从今年起,泡沫正在逐渐增大,他有些担忧“极度的热情之后会降到很低的温度”。
不过,某种程度上,松应科技就是从“冰点”成长起来的。
聂凯旋创业到现在,见过大概两百多位投资人。他经历了无数的质疑和否定。然而,他多次和团队着重强调,用智能去推动物理世界,这是一项为期 10 到 20 年的长期事业,不能因为短期的阵痛而影响信心。
我们现在拥有了数据,拥有了产品。对产业周期有了更深入的理解。同时也有了正在服务的客户以及深度协同的伙伴。这使得整个团队的心态更加踏实。如今市场热度较高,能够顺势而为自然是很好的。但我们不会一味地去追逐风口。我们要打造一家以使命驱动,并伴随需求发展的公司。聂凯旋如是说道。
