最近,图灵奖获得者 Richard Sutton,也就是强化学习之父,与 DeepMind 强化学习副总裁 David Silver 一同发布了一篇文章。

有人称,这篇文章如同《The Bitter Lesson》的后续篇章,给我们带来了强烈的冲击——AI 范式正在经历重大的转折!
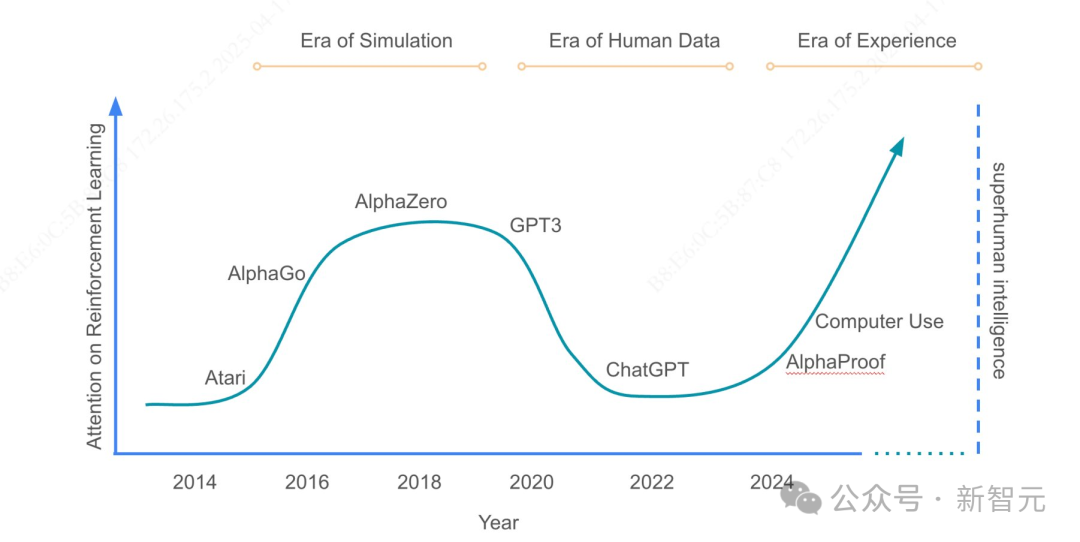
文中表明,我们曾经历过模拟时代。我们享受过人类数据时代。如今,我们正踏入经验时代。
以后想要再发展AI,不靠模仿,不靠学习,而是靠「活过」!
太长不看版
一位中国网友的总结,得到了RL之父本人的转发和赞许。
以下是就是这位网友「xingxb」的总结。
我们正从“人类数据时代”迈入“经验时代”。这并非模型的升级,也不是 RL 算法的迭代,而是一种更为根本性的范式转变:
· 从模仿人类到超越人类
· 从静态数据到动态经验
· 从监督学习到主动试错
他们喊话整个AI界:经验,才是通往真正智能的钥匙!
人类数据已经达到了顶峰。如今的 AI(像 LLMs 这类)是依靠大量的人类数据来进行训练的。它具备写诗、解题、诊断等诸多能力,几乎可以做到无所不能。然而,我们必须要留意的是:
· 高质量数据正在枯竭
· AI的模仿能力已经逼近人类上限
· 数学、编程、科研等领域再难靠「喂数据」进步
因此,模仿能让AI胜任,但不能让AI突破。
经验是下一个超级数据源。能够推动 AI 跃升的数据,必须随着模型的变强而自动增长。唯一的解决办法就是经验自身。
· 经验是无限的
· 经验能突破人类知识边界
· 经验流才是智能体的本地语言
因此,RL 的创始人主张:未来的 AI 并非仅仅是“提示词+知识库”,而是由“行动+反馈”所构成的循环体。
它们有几个关键特征。
· 它们生活在持续经验流中(非任务片段)
· 它们的行为扎根真实环境,不靠聊天框
· 奖励来自环境,而非人类打分
· 推理依赖行动轨迹,而非仅模仿文本逻辑
这些,都是对LLM范式的一次根本性挑战。
强化学习并非能解决所有事情。如今,我们的经验智能仍处于早期阶段,然而技术条件和算力已经具备。那么,AI 社区是否已经准备好去拥抱主动智能范式呢?
这,将是一次思想上、技术上和伦理上的深刻转折。
通往ASI:经验时代新阶段
最近,DeepMind 的强化学习副总裁 David Silver 做出了掀桌并大声宣言的举动。
大语言模型(LLM)并非AI的全部!
人类需要的是能自主推理、发现未知事物的AI。
如果剥离人类反馈的要素,那么最终得到的模型能否保持现实根基呢?
David Silver提出了与主流相反的观点。

他在近期的博客里探讨了“经验时代”这个概念,同时也探讨了当前的“人类数据时代”这个概念。
以 AlphaZero 为例,他强调了强化学习可以超越人类能力,并且不需要先前的知识。
这种做法与依赖人类数据和反馈的大语言模型形成鲜明对比。

Silver着重指出探索强化学习对于推动 AI 取得进步以及实现 ASI 是有必要的。
当前多模态模型备受热议,引发兴奋,也取得诸多成就。在此之后,David 制定了一个通往 ASI 的计划,他将其称作“经验时代”的新阶段。
「经验时代」将与过去几年,完全不同。
过去一直处于“人类数据时代”这一阶段,意思是所有 AI 方法都有着一个相同的想法:
提取人类拥有的所有条知识,然后输入到机器中。
这固然非常强大。
但存在另一种方式,这种方式会引领人类步入“经验时代”。在这个时代里,机器会与实际的世界本身进行互动,并且会产生属于自己的经验。
交互数据若被视为驱动机器的燃料,这会引领下一代 AI 进入“经验时代”。
David 在某种程度上表现出了激烈的反应,他大声呼喊:“大语言模型不是唯一的 AI。”
AI 存在其他的选择,能够以不同的方式达成 AGI。
构建大语言模型,AI的确获益良多——
利用海量的人类自然语言数据,把所有人类书写过的知识都整合到机器里面。
但某种程度上,人类必须跨越这个阶段:突破认知的边界。
要实现这一点,就必须采用全新的方法——
这种方法要求AI能够自主推理,发现人类未知的领域。
这会开启一个崭新的 AI 时代,这个时代必定会给社会带来之前从未有过的深刻变革以及无尽的可能。
AlphaGo:与LLM完全不同
一些著名的 AI 与 LLM 不同,它们采用了不同的方法,其中最值得一提的是 AlphaGo 和 AlphaZero。
大约十年前,它们击败了世界上最顶尖的围棋选手。

AlphaGo击败当时围棋国际排名第一的柯洁
如何从头开始学习围棋?
AlphaZero 特别之处在于,它与最近那些基于人类数据的方法有着很大的不同。其原因是它完全不借助人类数据。

“零”这个词体现了这一情况。因此,系统预先编程的是在字面意义上的零人类知识。
那么,LLM 的替代方案究竟是什么呢?倘若不复制人类,并且在事先并不知晓正确的下棋方式的情况下,要怎样去学习围棋知识呢?
可以采用的方法是一种试错学习的形式。
AlphaZero 进行了自我对弈,对弈的盘数达到了数百万盘,这些棋局包括围棋、国际象棋以及它想玩的其他棋类游戏。
它一点一点地发现:如果是在这种情况下下这种棋,那么最终自己会赢得更多的比赛。
然后,这成为它用来变得更强大的经验。
它会下一些类似的棋,下得稍微多一些。接着下一次,它能发现新的东西,然后它会说:“哦,当采用这种特定的模式时,我要么最终会赢得更多的比赛,要么最终会输掉更多的比赛。”
这会反过来促进下一代的学习,以此类推。
这种学习是从经验中进行的,并且是从智能体自身所产生的经验中进行的,这样就已经足够了。
最初版本的 AlphaGo 确实是以一些人类数据作为起点的。
给它输入了一个由人类职业棋手的棋谱组成的数据库,它对这些人类的招法进行了学习和吸收,而这给它提供了一个起始点。
然后,从那时起,它通过自己的经验进行学习。
然而,一年之后被发现,人类数据并非是不可或缺的,是能够完全将人类的招法舍弃掉的。
这证明了:程序能够达到更高的性能水平。
苦涩的教训:人类数据可有可无
AlphaZero 很是奇怪。它抛弃了人类数据,而后发现人类数据不但没什么用处,还在某种程度上对性能进行了限制。
这涉及到AI领域深刻的「苦涩的教训」。
大家都认为:人类积累的知识非常重要。
这使得设计出的 AI 算法更倾向于适应人类数据,同时在自主学习方面表现得不太出色。
结果是,若抛弃了人类数据,那么实际上会耗费更多的精力让系统进行自主学习。
而正是自主学习才能不断地学习和学习,永无止境。
这几乎就是承认 AI 有比人类更擅长下围棋的可能性,并且在一定程度上突破了人类所具有的上限。
人类数据对 AI 的起步有着很大的作用。然而,人类所进行的所有行为都存在一个上限。
AI 在 AlphaZero 中通过自我对弈来进行学习。它不断变得越来越好。最终突破了人类的上限,并且远远地超越了人类。
在「经验时代」,人类能找到足以在所有领域都突破上限的方法。
AI神来之笔:第37手
AlphaGo 在对阵李世石的第二盘棋里所下的第 37 手棋,让所有人都感到意外。
AlphaGo 下在了第五线,通过某种特定方式下出了这步棋,从而使棋盘上的一切都变得合理了。
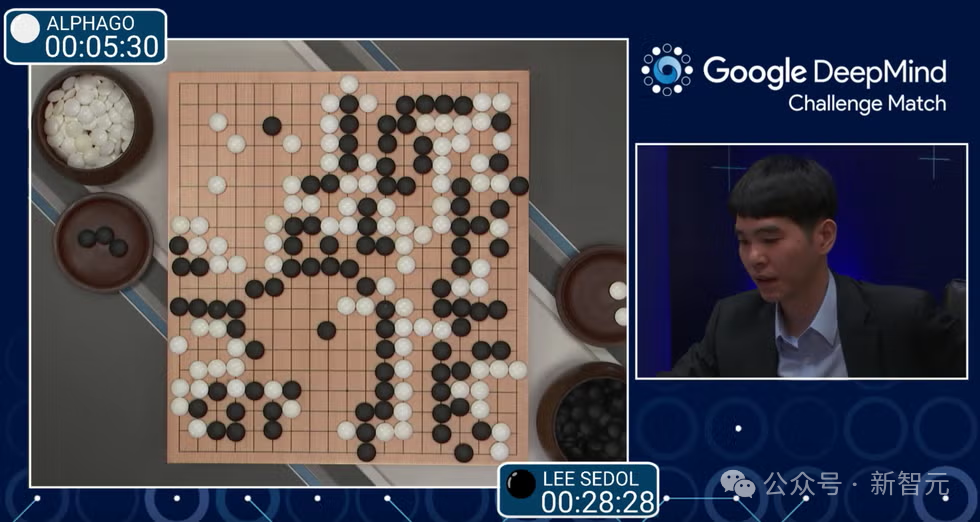
人类对这是如此陌生,人类估计想到迈出这步棋的概率只有万分之一。
人类对这步棋感到十分震惊。而这步棋最终帮助 AlphaGo 赢得了那盘棋。
在那一刻,人类意识到,看,这里发生了一件事,这件事是开天辟地的。同时,机器想出了一些下棋方式,这些方式与人类传统的思维方式不同。
这是历史性巨大的进步,远在人类知识的界限之外。
一直处于人类数据时代,人们投入了大量精力去复制人类能力,却很少将关注放在超越人类能力上。
如果没有真正强调系统自主学习并且超越人类数据,那么就不会在现实世界中看到像第 37 手棋那样的巨大突破。
第 37 手棋不只是一个单独的发现,它证明了能够从经验里持续地学习,进而涌现出无尽的发现。
刚刚完成了国际象棋方面的 AlphaZero,接着就把它直接应用到了将棋(日本象棋)的游戏中,结果连世界冠军都觉得它远超人类的上限。
实际上,这是第一次在将棋上运行AlphaZero。
开发者只是按下了「开始」键,一个超人的将棋选手就诞生了。
就像魔术一样。
