美国政府经过多轮市场传言猜测与情绪反转后,最终对英伟达的 H20 芯片进行了出口管制。英伟达 CEO 黄仁勋时隔 3 个月再次到访中国,他表示希望继续与中国合作。由此可见,这一举措在业内引发了震动。随着 H20 芯片在中国市场受限,国内 AI 芯片替代的真正大考正式开启。
英伟达H20等受限,国内厂商迎替代大考机会
关于 H20 芯片的出口管制事宜,近日,英伟达发布了 8 - K 文件。文件称,美国政府在 4 月 9 日进行了告知,即 H20 芯片出口到中国需要许可证。之后,在 4 月 14 日又再次告知,这些规定将无限期地实施。美国把 H20 纳入了“非民用超算风险清单”,这表明 AI 芯片管制从高端产品(例如 A100、H100)延伸到了定制化的中端产品。需要说明的是,英伟达在中国合法销售的主要芯片是 H20,它是在 2023 年 10 月美国最新一轮出口限制生效后推出的。

几乎在同一时间,美国商务部进行了宣布。AMD MI308 以及同类型的 AI 芯片,被增加了新的中国出口许可要求。并且英特尔似乎也未获得任何豁免。据报道,该公司向中国销售其 Gaudi 芯片时,同样需要获得出口许可证。
万联证券认为,此次美国政府对 H20 实施许可证管理,这表明贸易管制的力度在加大。并且认为 H20 在中国市场的销售可能会面临较大的限制,进而可能导致英伟达在中国市场的份额有所流失,而国内的 AI 芯片厂商有望承接更多的市场份额。该机构指出,关税博弈的情况尚未确定。全球贸易摩擦有可能会加剧,这会促使半导体产业的国产化进程进一步加快。国产算力也将迎来发展的机遇。
我们认为,英伟达 H20、AMD MI308 等同类型的 AI 芯片以及英特尔 Gaudi 芯片在中国市场的销售受到限制。国产 AI 芯片迎来了直面替代大考的机会,也就是说,国内厂商拥有了前所未有的市场空间,能够在此空间中验证自身产品的性能、可靠性、生态兼容性以及供应链的稳定性等。
本土力量崛起,华为昇腾领跑光环下的隐忧
提及替代英伟达 GPU 的大考机遇,华为的昇腾系列芯片是目前最受关注、声量最高,并且在实际部署方面走得最远的本土替代选择。以昇腾 910C 为代表的最新一代产品,正在成为中国构建本土 AI 基础设施的关键所在。
更重要的是,华为已将芯片的能力拓展到系统层面。它借助像 CloudMatrix 这样的计算系统,比如近日被媒体广泛报道的由 384 块昇腾 910C 组成且采用全对全互联拓扑的 CM384 系统,来汇聚算力。其超节点在规模以及推理性能方面,已经能够与英伟达 NVL72 超节点相媲美。而这和构成该计算系统最核心的华为昇腾910C芯片密不可分。
多个可靠来源和平台,如 Huawei Central、TrendForce News 和 Reddit 等进行研究分析后表明,昇腾 910C 是由两个昇腾 910B 芯片组合而成的,并且采用了共封装或芯片组技术。两个 910B 芯片进行组合后,910C 的计算能力有了显著提升。它达到了 800 TFLOP/s(FP16)的计算能力,同时内存带宽为 3.2 TB/s,其性能几乎是英伟达 H100 的 80%。

这种设计方式有其有利的一面,同时也有其弊端。在短期内,它提升了性能,但从长远来看,也带来了显著的弊端。
首先从技术层面看,这种设计会导致诸如功耗增加、互连瓶颈等。
以功耗增加作为例子,更高的功耗就意味着会有更多的散热需求,这会增加散热系统的成本以及复杂性,像需要更强大的风扇、散热片或者液冷系统等。并且,在数据中心这类对能效要求很高的场景当中,高功耗会大幅度地增加运营成本。
知名半导体和人工智能研究公司 SemiAnalysis 称,CM384 系统的功耗要比英伟达的 GB200 NVL72 系统高很多。它需要的功耗是 GB200 NVL72 的 3.9 倍,每完成一个浮点运算(FLOP)的功耗比 GB200 NVL72 差 2.3 倍,每达到每秒 1TB 的内存带宽的功耗比 GB200 NVL72 差 1.8 倍,以及每拥有 1TB 的 HBM 内存容量的功耗比 GB200 NVL72 差 1.1 倍。(“功耗差 X 倍”意思是相对于基准 GB200 NVL72,每单位性能/容量所需的功耗是其 X 倍,也就是能效差了 X 倍)。上述部分原因可能源于昇腾 910C 芯片本身的组合设计。
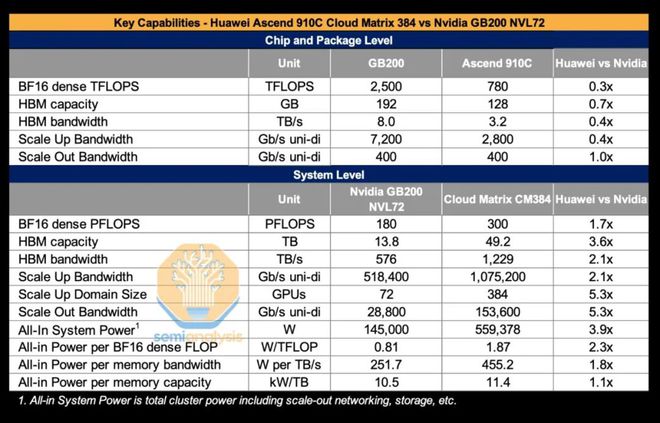
不要小瞧功耗的上升。在实际进行部署时,每一台 AI GPU 服务器的基础投资大概是 40 万美元。并且,在这其中,电源以及冷却等基础设施所占建设成本超过 1/3。IDC 调研显示,80%的数据中心决策者把能耗与散热当作关键制约因素。具体而言,华为 CM384 系统的功耗是 GB200 NVL72 的 3.9 倍。这样一来,其长期运行成本必然会升高。而怎样在规模扩张与能效之间找到平衡,是一个巨大的挑战。
关于互连瓶颈,910C 的目的是解决 910B 在跨卡互连方面的严重问题。然而,组合这两个芯片的设计可能会存在互连带宽的限制。Huawei Central 的研究表明,910C 的 die-to-die 带宽只是 Nvidia H100 的 1/10 到 1/20 。这种瓶颈会对大规模 AI 训练任务的效率产生影响。具体而言,性能无法随裸片数量呈线性扩展。两个裸片通常达不到单个同等技术裸片性能的两倍,尤其在需要高带宽的场景,像训练大型语言模型(LLM)时。并且,数据在不同裸片之间传输会带来额外的延迟和功耗。
在生态系统与市场层面,众所周知,华为 MindSpore 的 AI 框架属于昇腾计算,与昇腾芯片同属一类。它在不断发展,然而,在这一层面,它仍然无法与英伟达的 CUDA 平台相提并论。
Unite.AI 的分析表明,MindSpore 的成熟度与广泛采用度不高,这或许会对开发者的采用造成限制,特别是在长期 AI 训练任务方面。这有可能致使 910C 在软件支持以及开发者生态系统上落后于英伟达,进而在实际应用中降低效率。
最后,更为关键的是,SemiAnalysis、TechInsights、WCCFTech 等进行了拆解、分析和报道。确认尽管昇腾 910C 部分是由中芯国际(SMIC)制造的,但由于良率受限(有报道称华为昇腾芯片良率仅为 32%,也有报道称昇腾 910C 的良率已提高至近 40%,但仍低于 60%的行业标准)以及产能的原因,其绝大部分还是采用台积电的 7nm 工艺制造。
国内晶圆代工厂,像中芯国际,究其原因,在技术上已经掌握了 7nm 工艺。然而,与台积电相比,它在先进制程的良率方面存在差距,在稳定性方面也有不足,在大规模量产能力上相对较弱,并且在配套的设备和材料生态等方面也仍有欠缺。特别是对于像昇腾 910C 这样尺寸较大且技术复杂的 AI 芯片,对制造工艺的要求更为严格,中芯国际在满足其大规模、高良率生产的需求方面依然面临着挑战。
华为即便有国内制造的选项,但其为保障供应稳定性和产品性能,仍倾向于依赖技术更成熟、产能更稳定的台积电,这体现了中国在先进制程制造环节面临“卡脖子”困境时,通过第三方渠道获取晶圆的这种模式。
此外,昇腾 910C 的关键组件,例如 HBM,主要是由韩国供应商三星提供的。据 SemiAnalysis 所说,主要是由三星在大中华区的 HBM 独家经销商 CoAsia Electronics 向 ASIC 设计服务公司 Faraday 发货 HBM。然后,Faraday 再委托 SPIL 使用便于后续提取的低熔点焊料,将 HBM 与廉价的 16nm 逻辑芯片一起进行“封装”。最后,将封装好的产品运到中国,以拆焊的方式回收 HBM 并使用。这种以规避为核心目的的供应链模式是众所周知的。它除了合法性存在疑问之外,稳定性极差,风险性极高,这是最大的隐忧。
国内厂商多点开花, 方能降风险、保稳定、促自主
我们可以看到,华为昇腾 910C 在国内应用和替代方面处于领先地位。然而,从芯片性能、生态环境以及供应链模式等环节来看,由于客观或自身的原因,存在着较大的隐忧。这就需要国内其他相关厂商参与到替代的大考中。
事实是,在 AI 芯片领域,科技大厂阿里、百度、腾讯除华为外均已布局自研 AI 芯片。在纯芯片厂商中,既有寒武纪、景嘉微、海光信息等上市公司,同时也涌现出芯动科技、瀚博半导体、沐曦集成电路、天数智芯、地平线等一批兼具技术沉淀与创新活力的企业。
其中阿里巴巴(含平头哥的含光芯片)属于科技大厂,百度(昆仑芯)属于科技大厂,腾讯属于科技大厂,商汤科技属于科技大厂。它们基于自身庞大的业务需求,开发用于内部场景的 AI 芯片。这些芯片主要服务于它们自有的云平台或业务,虽不直接面向广泛的外部市场销售,但代表了国内顶尖的应用场景驱动型芯片设计能力,是国产 AI 算力体系的重要组成部分。
海光信息属于上市公司。其海光 DCU 系列产品以 GPGPU 架构为基础。该产品建立的自研软件栈全面兼容 CUDA 生态以及国际主流商业计算软件、人工智能软件。它可广泛应用于大数据处理、人工智能、商业计算等领域。现已应用于国产超算和 AI 训练场景。并且能够承接部分 H20 受限后的市场需求。百度、阿里以及腾讯等互联网企业已对海光的 DCU 产品进行了认证,并且推出了联合方案,致力于打造全国产软硬件一体的全栈 AI 基础设施。同时,科大讯飞、商汤和云从等国内的头部 AI 企业,已经有大量的模型被移植到海光 DCU 平台上并在该平台上运行。
寒武纪作为国产 AI 芯片的头部企业。寒武纪的思元系列芯片在云端和边缘计算领域能够部分替代英伟达的产品。尤其通过第五代智能处理器微架构,寒武纪的产品可以满足云端训练等场景的需求。
自 2019 年起,除了那些老牌企业之外,有一批国产 GPU 初创公司先后成立了。在这些公司中,涌现出了像壁仞科技、摩尔线程、燧原科技这样的 AI 芯片设计独角兽。
摩尔线程与华为昇腾存在差异,它的目标是打造一个更为广泛的通用 GPU 生态系统。基于此,摩尔线程构建了 MUSA(Moore Threads Unified System Architecture)这一统一的软件平台。近日,摩尔线程正式推出了 MUSA SDK4.0.1。它最大的一个突破在于完成了从芯片设计到软件栈的“全链路贯通”。同时,它还实现了对英伟达 CUDA 的全盘迁移,用户的使用习惯不会发生改变,并且速度比原来快了 15%以上。
壁仞科技同属 AI 芯片设计独角兽。它在 2022 年就推出了一款 GPGPU 芯片 BR100,此芯片采用 7nm 制程。该芯片的峰值算力超过了国际厂商在彼时正在销售的旗舰产品的 3 倍。并且它还创下了国内互连带宽的纪录。
从上述情况可以明显看出,国内除了华为昇腾之外,还有很多在 AI 芯片领域实力很强的企业,并且其中不乏有能够替代英伟达 GPU 的。鉴于我们之前提到的华为昇腾存在的担忧,只有这些企业积极参与进来,实现多点发展,才能够在替代的过程中,降低风险、保持稳定、促进自主。
英伟达 H20 等近期在中国市场受到限制,这突显了国内替代方案的重要性。我们认为,通过上述情况,中国 AI 芯片的替代以及未来的自主之路,不能仅仅依靠个别企业,也不能长期依赖充满不确定性的规避手段的供应链模式。而在于实现多点开花,支持华为、海光信息、摩尔线程等多元化的国内 AI 芯片企业协同发展,以此构建真正强大、完整且有韧性的全产业链自主生态,这才是加速实现中国 AI 芯片自主可控的正确途径。
