AI 也要 007 工作制了!
近日,AI 初创公司 Letta 与 UC 伯克利的研究人员一同提出了一种扩展人工智能能力的新途径,即睡眠时间计算(Sleep-time Compute)。这种方式能让模型在空闲时段进行“思考”,其目的在于提升大型语言模型(LLM)的推理效率,降低推理成本,并且在这一过程中保持或提高准确性。

睡眠时间计算的核心理念是:智能体在“睡眠”(也就是用户未提出查询时的闲置状态)期间,即便处于闲置状态,也需要持续运行。这样它就能利用这些非交互期来重组信息,并且提前完成推理。当前有许多智能体是在存在持久化上下文的环境中运行的。比如,代码智能体能够在编程请求到来之前预先学习代码库;对话智能体则可以对用户过往的交流记录进行反思,在交互之前重新整理信息。
在睡眠时段进行推理的过程会把“原始上下文”转化为“学习到的上下文”。智能体如果仅拥有原始上下文,而具备预处理能力的智能体则不同。具备预处理能力的智能体在实际应答时能够减少即时推理计算的负担,因为它们提前进行了思考。

从测试时间扩展到睡眠时间扩展
在过去的一年中,我们看到了“推理模型”的兴起。这些模型在给出回答之前会进行“思考”。像 OpenAI 的 o1、DeepSeek 的 R1 以及 Anthropic 的 Claude 3.7 等最新的模型,它们不再立刻给出答复,而是在返回最终回答之前会输出一段详细的推理过程。这种延迟输出结构在数学等特定应用领域以及编程等特定应用领域中都展现出了明显的智能提升。实践已经证明,让模型在测试的时候(test time)去进行更长时间的推理计算,其推理时间从几秒到几分钟不等,这样能够让模型的推理质量得到显著的提高。
这种策略叫做“测试时扩展”。它已经被广泛证实是推动基于大型语言模型(LLM)的 AI 系统迈向更高级智能层级的一种高效路径。也就是说,在测试时投入的推理资源越多,系统的表现往往就会越好。
这是否只是冰山的一角呢?我们是否在严重低估当前 AI 系统所具有的潜力呢?如果只是在用户触发交互的时候才启用智能体的推理能力,那是否意味着这些模型在绝大部分时间里都没有被有效地利用呢?
研究人员相信,AI 系统存在一种范式转变且未被充分释放。这种转变不仅是在响应提示时被动推理,还在未被激活期间主动加深对世界和任务的理解。这正是他们提出的“睡眠时间”概念,意味着 AI 系统在漫长空闲且不与用户交互期间,能够深入处理和组织信息。
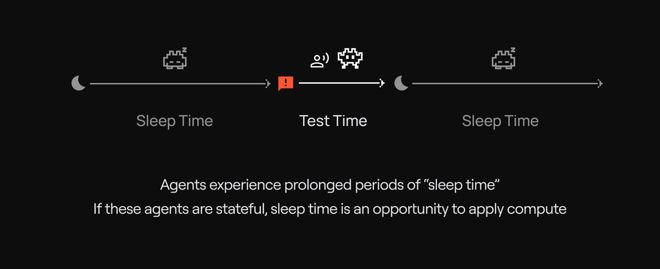
他们在最新的研究论文中提出了“睡眠时间计算”。这为具备状态性的 AI 系统提供了全新的扩展路径:在系统本应用于空闲的时段启用深层思维,这样就能拓展模型的理解能力与推理方式,突破仅靠交互时计算资源所能实现的能力上限。
睡眠时间计算
在标准的测试时间计算应用范式里,用户将提示 p 输入给 LLM ,接着 LLM 运用测试时间计算去协助回答用户的问题。
然而,提供给 LLM 的提示 p 一般能够被分解为两部分。一部分是已存在的上下文 c,比如一个代码库;另一部分是用户查询 q,例如关于代码库的问题。
当 LLM 未及时回应用户时,它一般仍能访问现有的上下文 c。在这期间,LLM 通常处于空闲状态,错失了离线思考 c 的时机:本文把这个过程称作睡眠时间计算。
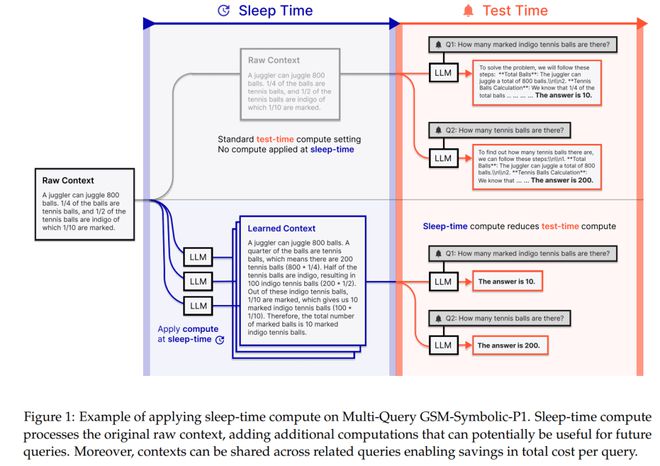
在测试时间计算设置里,用户给出 q 以及一些上下文 c,模型会输出推理跟踪,接着给出最终答案 a。
这个过程可以这样表示:T 是在预算 B 下进行测试时间计算的方法,其中包含扩展思维链或 best-of-N 等技术,并且该过程可表示为 T_B(q, c)→a。
在实践当中,用户或许对同一个上下文会有诸多查询,比如 q_1、q_2 等等一直到 q_N。在这样的设置之下,模型会针对每一个 q_i 展开独立的推理过程,即便这些查询都与相同的上下文存在关联。
此外,在很多情况下,上下文信息 c 或许会极为复杂。要生成问题 q 的答案,需要进行大量的推理。因为传统测试时的计算范式 T (q, c)→a 假定 c 与 q 是同时被获取的,所以在标准测试时,只有当用户提交查询后,才会启动所有这些推理。这就导致用户可能需要等待好几分钟才能得到响应。然而在实际应用里,我们通常可以预先获取 c,并且能够把大部分预处理工作提前完成。
在睡眠时间时,能够得到上下文 c 但未查询 q。仅凭借这个上下文 c,能够利用 LLM 去推理可能的问题以及推理上下文,最终形成一个经过更新的重新表示的上下文 c ′。研究者把这个过程表示为:S (c) → c ′,这里的 S 可以是任何用于在睡眠时间预处理上下文的标准测试时间扩展技术。
在这项工作里,S(c)是借助提示模型来进行推理,并且以在测试时可能有用的形式对 c 进行改写从而得以实现的。在对上下文进行预先处理之后,在测试时能够用新的上下文 c′来替代 c,进而生成对于用户查询的最终答案:T_b(q, c′)→a。因为在这种情形之下,关于 c 的多数推理早已提前完成,所以能够运用小很多的测试时间预算 b 。
