
香港中文大学(深圳)数据科学学院三年级博士生徐俊杰龙是论文的第一作者,指导老师有香港中文大学(深圳)数据科学学院的贺品嘉教授以及微软主管研究员何世林博士。贺品嘉老师的团队研究重点包含软件工程、LLM for DevOps、大模型安全。
大型语言模型(LLM)近期在软件工程领域有了显着的进步,催生了诸多研究成果与实际应用,如metaGPT、SWE-agent、OpenDevin、Copilot 和Cursor 等,这些成果对软件开发的方法论和实践产生了深刻的影响。现有研究主要聚焦于软件开发生命周期(SDLC)的早期阶段的任务,像代码生成(LiveCodeBench)、程序修复(SWE-Bench)以及测试生成(SWT-Bench)等。然而,这些研究通常会忽视软件部署后的运维阶段。在实际的生产环境里,线上的软件如果出现故障,有可能让服务提供商蒙受数十亿美元的损失,这把在根因分析(RCA)领域开发更有效解决方案的迫切需求凸显了出来。
学术界和工业界的许多研究者为了探索LLM 在这一领域的可行性,已经开始进行相关研究。但是,由于运维数据的隐私性以及企业系统的差异性,目前基于LLM 的根因分析研究存在不足,缺乏统一且清晰的任务建模,同时也没有公开的评估数据和通用的评估指标。这使得对LLM 在根因分析方面的能力进行公平评估变得困难,这种困难进而阻碍了该领域的发展。
微软DKI 团队、香港中文大学(深圳)贺品嘉教授团队以及清华大学裴丹教授为了解决这一问题,共同提出了当前首个公开的基准评估集——OpenRCA,此评估集用于评估LLM 的根因分析能力。并且,本文已被ICLR 2025 接收。
OpenRCA 制定了清晰的任务建模以及对应的评估方法,这些是基于LLM 的RCA 任务的。同时,它还提供了一组公开的故障记录,这些记录经过了人工对齐,并且有大量的运维可观测数据。这为未来探索基于LLM 的RCA 方法奠定了基础。

研究者发现,当前主流的LLM 在直接应对OpenRCA 问题时遭遇明显挑战。比如,Claude 3.5 在获得了oracle KPI 的情形下,仅仅完成了5.37%的OpenRCA 任务。而当运用随机均匀抽样策略来提取可能相关的数据时,这个结果又进一步降低到了3.88%。研究者为了给解决OpenRCA 任务指明可能的方向,进一步开发了RCA-agent,将其作为一个更有效的基线方法。使用RCA-agent 之后,Claude 3.5 的准确率提升到了11.34%,然而,它与解决好OpenRCA 问题仍存在较大差距。
评估基准
任务建模
OpenRCA 把基于LLM 的根因分析任务规定为目标驱动的形式。模型或者智能体能够接收到由自然语言构成的查询指令,接着去执行不同目标的根因分析任务。模型或智能体需根据查询指令,通过检索和分析当前系统中保存的运维可观测数据,如指标、日志、调用链等。从中推理并识别出三种根因的组成元素,即故障时间、故障组件和故障原因中的一个或多个元素。最后以JSON 结构输出。若输出中的所有元素与标签一致,此样本被视为正例;若不一致,则视为反例。 OpenRCA 评估方法的能力是通过计算样本的平均预测正确率来实现的。

评估数据
为确保所使用软件故障记录和运维数据的质量,OpenRCA 选取了往年AIOps 挑战赛系列中提供的大量来自企业系统的匿名运维数据集合当作数据源。为使数据质量可靠有保障,研究者开展了包含四个步骤的人工数据处理以及标签对齐工作。具体而言,研究者把无法用于根因定位的系统观测数据给排除掉了。这些数据一般只能够用于粗粒度的异常检测,并且缺少详细的故障记录,像故障原因这类的信息。随后,研究者对这些系统的数据进行了整理,让不同系统间的样本数量达到了均衡,还标准化了不同系统数据的目录结构,这样做是为了便于模型的检索。最重要的是,为确保问题具有可解性,研究者对剩余数据中的故障进行了手动验证,以确定这些故障是否能够通过相数据人工定位到故障根因。研究者剔除了满足以下任何一个条件的数据记录:其一,无法在数据中识别出根因;其二,在故障期间数据存在缺失情况;其三,从数据推断出的根因与标签不相符。研究者首先根据不同的根因来定位目标,接着使用LLM 为每一个故障案例生成了相应的查询指令,然后把与每个查询指令对应的根因元素当作标签,就这样构建了335 个根因定位问题。

基线方法
研究者为了评估当前LLM 解决OpenRCA 问题的能力,构建了三种基线方法。其中有两种是基于采样的prompting 方法,另外一种是基于简单的ReAct 的Agentic 方法。
Sampling-based prompting
运维的可观测数据规模是很大的,然而LLM 的上下文窗口是有限的,所以直接输入所有数据是不现实的。在传统的根因分析里,常见的处理办法是进行采样。研究者把所有的数据(包含追踪、日志以及指标)按照每分钟一个值来进行下采样,并且对具体的指标类型进一步抽取样本,以此来减少KPI 序列的数量。研究者运用了两种策略来实施这种抽样:
RCA-agent
采样能够缓解长上下文的问题,然而运维数据中存在大量非自然语言,像GUID、错误码等。 LLM 处理这类信息的能力是有限的。基于此,研究者设计了RCA-agent,这是一个基于Python 的轻量Agent 框架,具备代码生成与执行反馈的功能,它允许模型利用数据检索和分析工具,从而提升模型对复杂数据的理解和操作能力。 RCA-agent 由两部分组成:

主要实验
研究者为了评测当前大模型解决OpenRCA 问题的能力,挑选了六个上下文长度至少为128k 的模型,像Claude 3.5 sonnet、GPT-4o、Gemini 1.5 pro 等。结果表明:
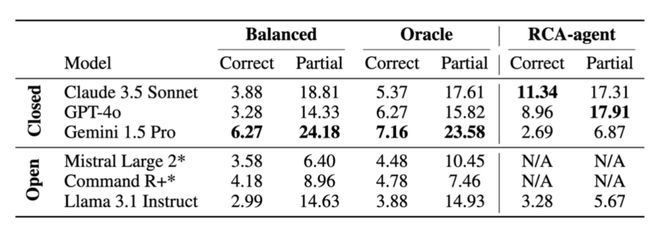
表1 基线方法的准确率对
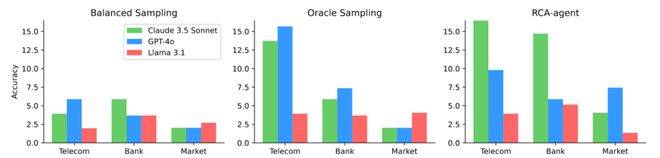
图2 模型在各个系统上的准确率分布
研究者进一步分析后观察到,当前模型在解决问题时倾向于采用较短的交互,这种交互的步数通常为6 至10 步。不过,当交互次数增多时,问题的正确率往往会更高。其次,研究者发现模型的代码生成能力以及代码纠错能力,会对其在RCA-agent 上的表现产生大幅影响。在只考虑那些执行轨迹中出现过代码运行失败情况的例子时,Claude 3.5 sonnet 的正确率下降了17.9%,从11.34 降到了9.31。而Gemini 1.5 pro 的正确率下降了68.4%,从2.69 降到了0.85。这些发现可能带来的启发是,在利用基于代码执行的智能体方法来解决OpenRCA 问题时,要尽量使用代码能力更为强大的模型,以便进行更长久链条的交互以及思考。

图3展示了交互链条长度的分布情况;图4呈现了正确率随交互链条长度的分布情况;表2则列出了模型代码执行有错时的正确率。
使用指南
OpenRCA 数据、文档、以及相关代码已开源在仓库中:
要使用OpenRCA 数据,需先将原始数据下载至本地。每个子数据集下都有若干以日期命名的运维数据目录,还有一份原始数据记录(record.csv)和问题清单(query.csv)。使用者需让其方法能够访问对应的运维数据目录,以解决问题清单上的问题。使用者可利用仓库中的那个评估脚本以评估其方法的结果正确性。
如果使用者想要在OpenRCA 的评测榜单上公开他们的评估结果,那么可以把他们方法的名称、原始结果文件、跑分、执行轨迹(若有)以及仓库连接(若开源)发送至openrcanon@gmail.com。我们会在确认结果的可信度之后,尽快将结果更新到排行榜上。
结语
大模型在软件工程领域的研究尚处于一片未被充分开发的状态。本文着重于给出一个任务定义明确且数据开放的代理任务数据集,以便各种不同的大模型RCA 方法能够进行公平对比。本文的评测也仅仅是针对大模型自身的RCA 能力进行的。在实际应用里,存在着诸多能够进一步进行工程优化的方面。例如,可以运用配置定制化的工具,以此来避免模型因完全自由推理和编码而产生幻觉问题。期望这篇论文能够起到抛砖引玉的作用,从而激发在更多软件工程任务上关于大模型研究的开展。
本文被ICLR 2025 接收了,海报会在4 月25 日下午3 点到5 点半期间,在Hall 3 以及Hall 2B 的#115 位置展出。感兴趣的同行们可以前来与作者进行交流讨论。
