1.基础知识总结 SQLAlchemy模块安装数据库 PostgreSQL下载安装 PostgreSQL基本介绍 使用Pandas+SQLAlchemy导出数据 PostgreSQL Python与各种数据库交互代码实现 2.开始动手动脑 1.SQLAlchemy模块安装
安装SQLAlchemy模块(以下操作均在虚拟环境中进行): 方法一:直接pip安装(最简单,安装速度慢,可能出错)
pip install SQLAlchemy技巧2:Wheel安装(比较简单,安装速度还可以,基本不会出错)点击这里下载SQLAlchemy的.whl文件,然后连接到你的开发环境目录。
pip install xxxxx.whl方法三:豆瓣源安装(比较简单,安装速度快,方便,推荐)
pip install -i https://pypi.douban.com/simple/ SQLAlchemy2.下载并安装数据库PostgreSQL
(1)下载地址:

(2)下载完成后,点击安装文件,基本Next。

首先,建议自己选择安装目录,不要安装在C盘。
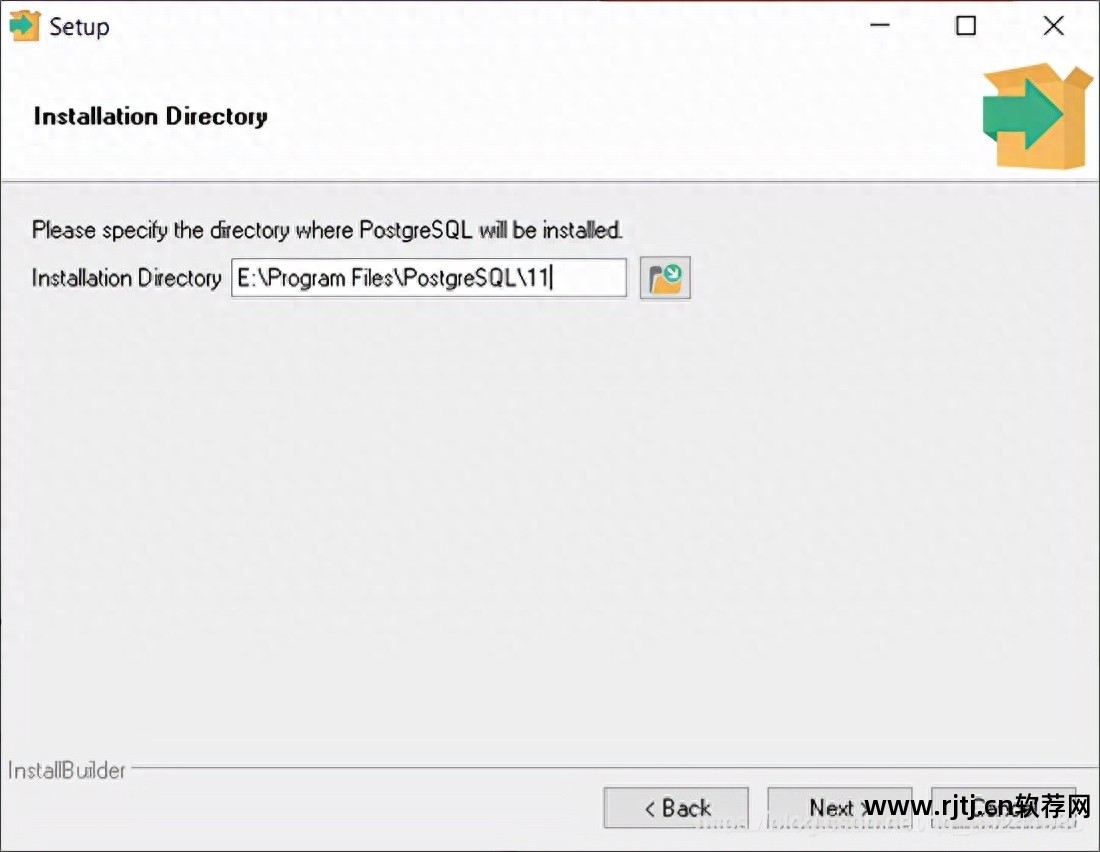
其次,密码设置简单,但实际上只是用于自学。
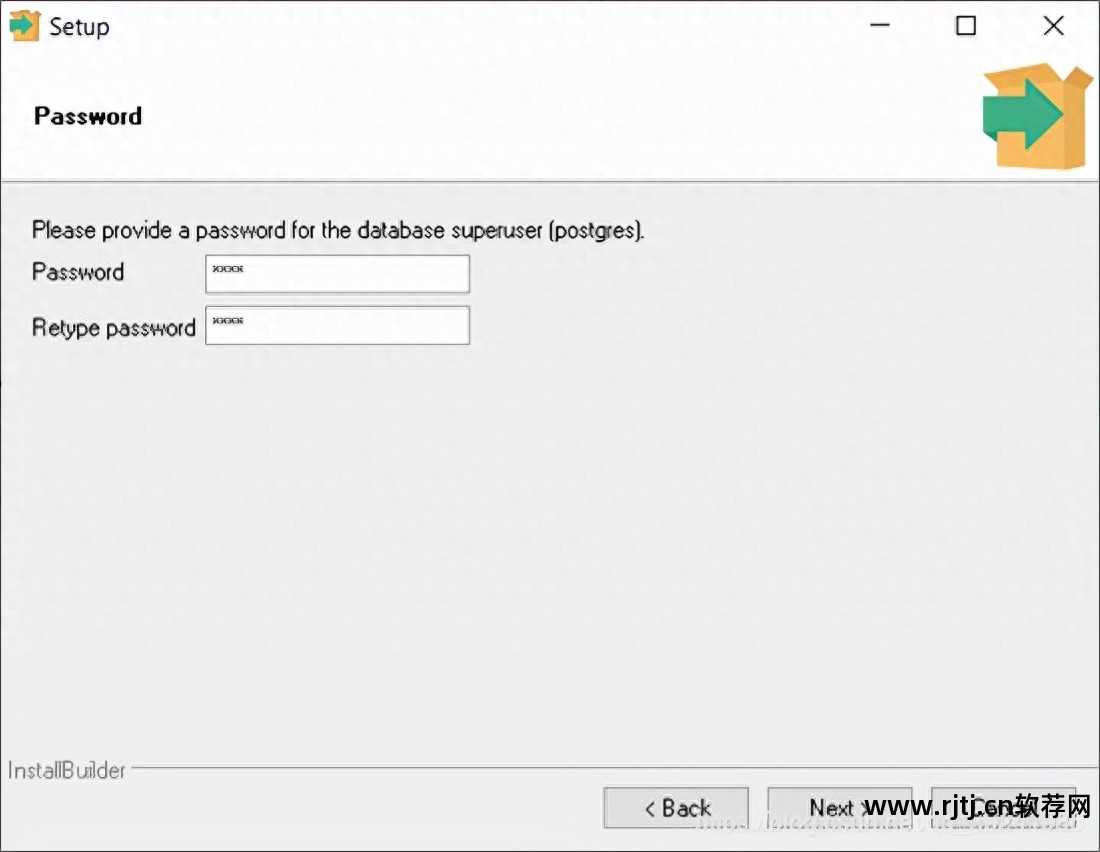
第三虚拟主机sql导入软件,端口号,建议不要改,用5432就可以了,改的话很容易和其他端口冲突。 以后就不知道怎么解决了,很麻烦。
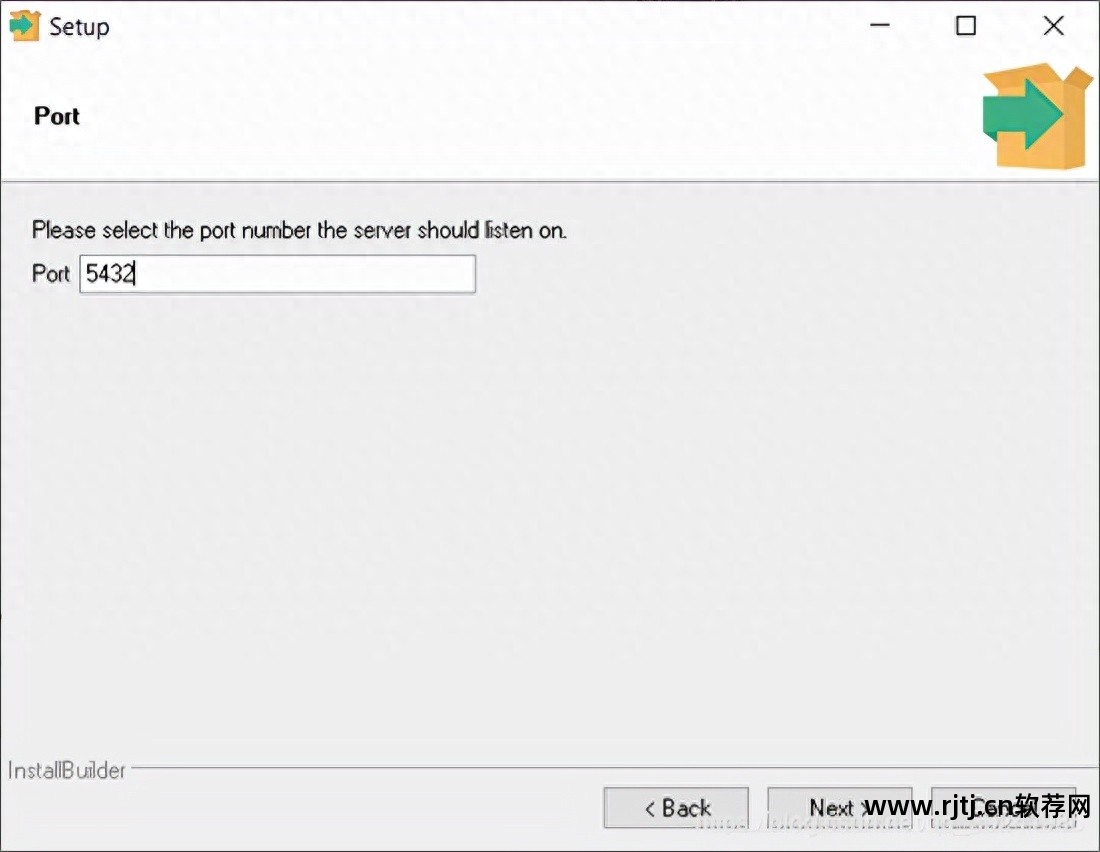
其他没有提到的都默认设置,下一步,下一步,下一步~安装过程通常需要10分钟左右,所以不要着急。 最后,安装完成后,取消图中的选项框。 图片的意思是在后台启动StackBuilder(堆栈构建器),这个不是必须的。
最后推荐几个Postgre社区的相关学习网站:Postgre官方文档:一佰Postgre学习教程:
3.PostgreSQL基本介绍及使用
(1)PostgreSQL特性


以上内容摘自易佰Postgre学习教程。 (2) 借助PostgreSQL创建数据库打开pgADmin4,发现这个图形操作界面是基于Web的。 首先,会要求您输入密码,这是安装时设置的密码。 单击服务器->PostgreSQL11->数据库->右键单击->创建->数据库。
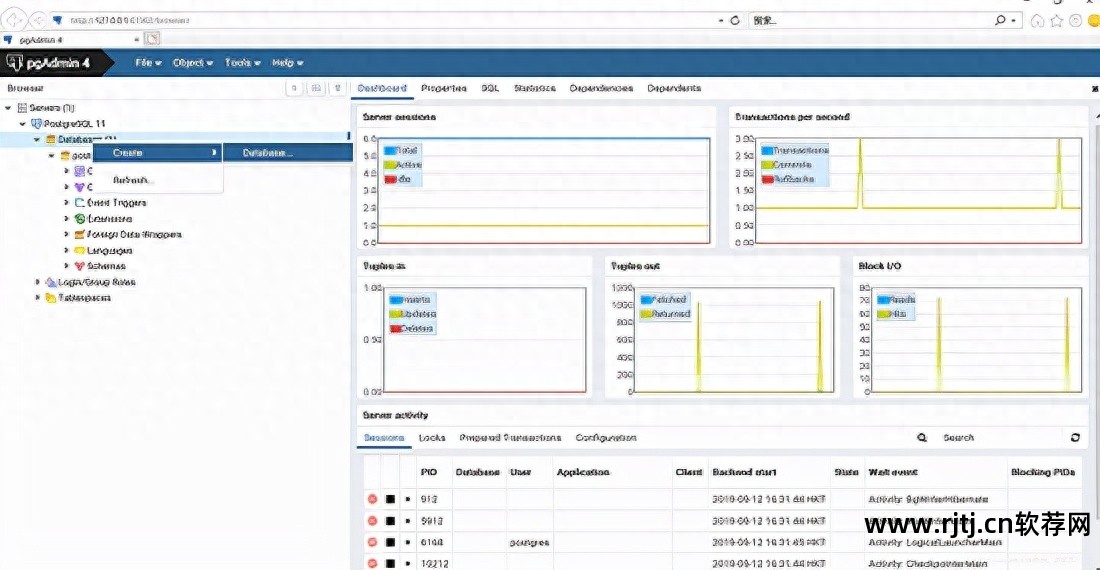
b. 输入数据库名称、其他默认值,然后根据需要编写注释。 我写的第一个数据库代表了我的第一个数据库。
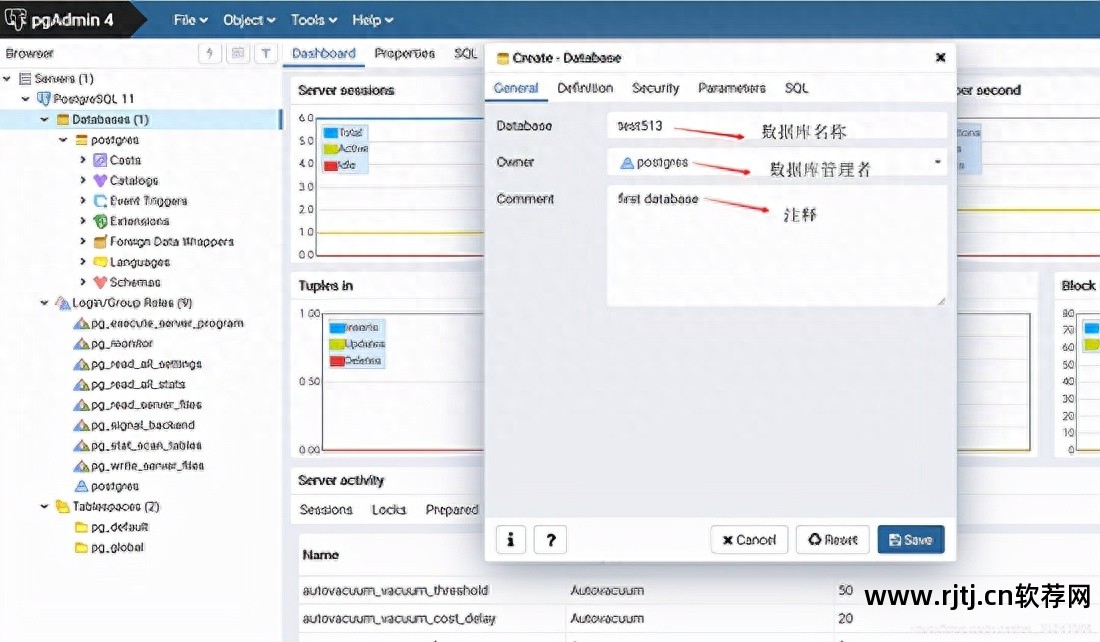
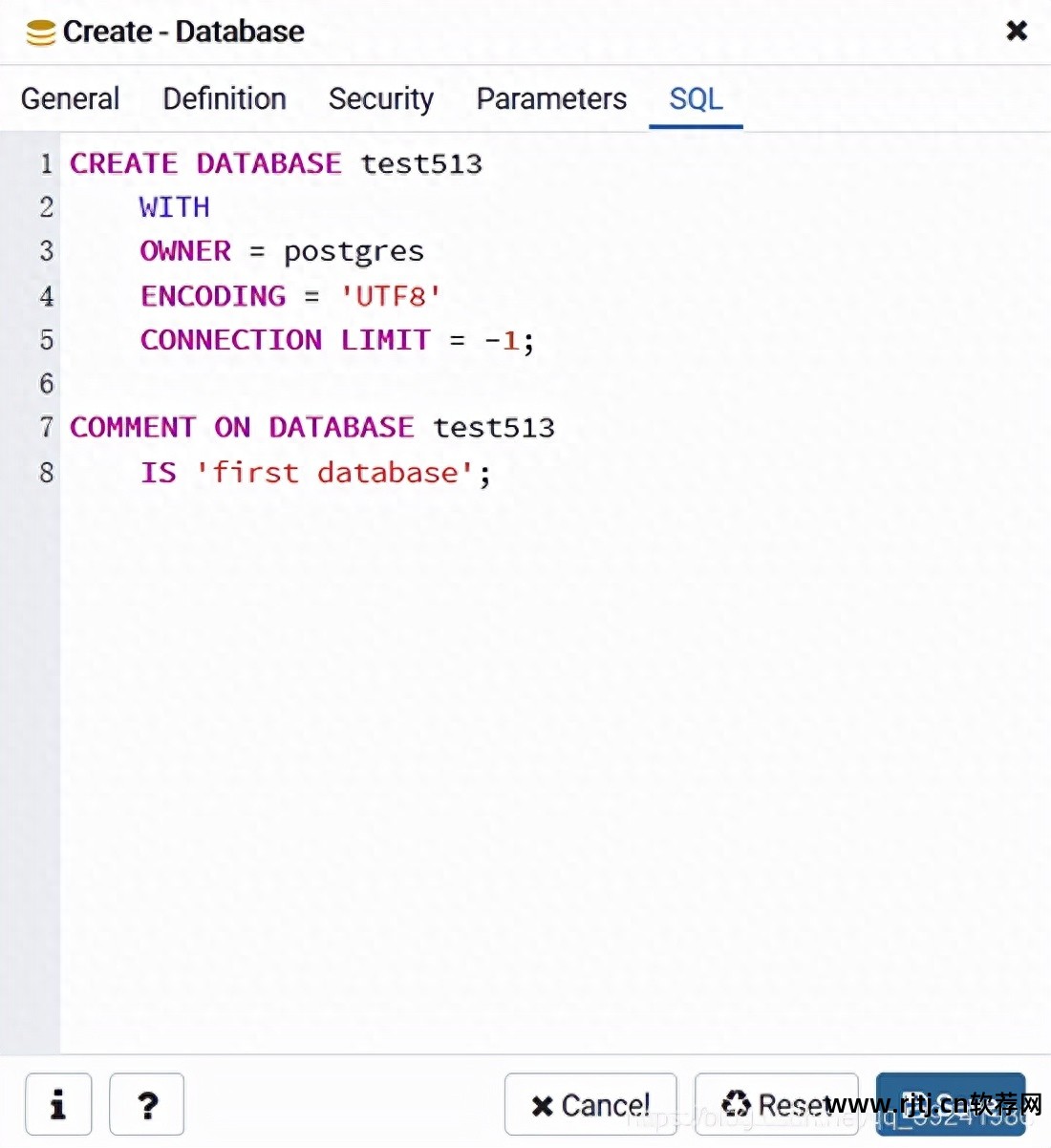
我们还可以查看数据库创建的句子,在弹出的框中点击SQL。
4.Pandas+SQLAlchemy导出数据到Postgre
(1)Python操作代码
import pandas as pd
import sqlalchemy as sa
# 读取的CSV文件路径
r_filepath = r"H:\PyCoding\Data_analysis\day01\data01\realEstate_trans.csv"
# 数据库鉴权
user = "postgres" # 数据库用户名
password = "root" # 数据库password
db_name = "test513" # 数据库名称
# 连接数据库
engine = sa.create_engine('postgresql://{0}:{1}@localhost:5432/{2}'.format(user, password, db_name))
print(engine)
# 读取数据
csv_read = pd.read_csv(r_filepath)
# 将 sale_date 转成 datetime 对象
csv_read['sale_date'] = pd.to_datetime(csv_read['sale_date'])
# 将数据存入数据库
csv_read.to_sql('real_estate', engine, if_exists='replace')
print("完成")
# 可能报错:ModuleNotFoundError: No module named 'psycopg2'
# 解决方法:pip install psycopg2(2)代码分析
engine = sa.create_engine('postgresql://{0}:{1}@localhost:5432/{2}'.format(user, password, db_name))SQLAlchemy 的 create_engine 函数创建数据库连接。 参数是一个字符串。 字符串的格式为:
://:
@:
/
数据库类型://数据库用户名:数据库密码@服务器IP(如:127.0.0.1)或服务器名称(如:localhost):端口号/数据库名称
可以是:postgresql、mysql 等。
csv_read.to_sql('real_estate', engine, if_exists='replace')pandas的to_sql函数直接将数据(csv_read中)存储到postgresql中。 第一个参数指定存储到数据库后的表名。 第二个参数指定数据库引擎。 第三个参数表示如果表real_estate已经存在虚拟主机sql导入软件,那么替换它。 (三)经营结果
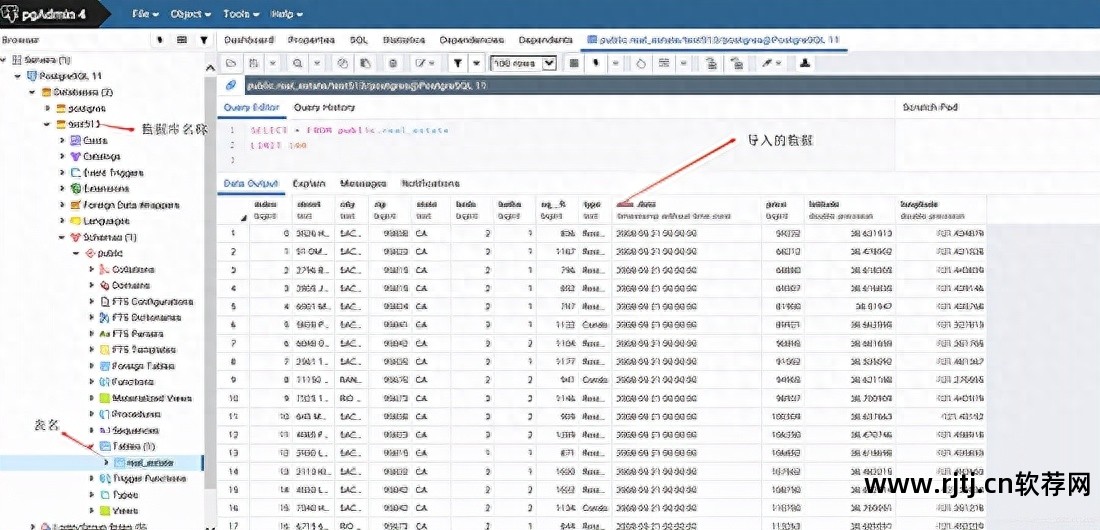
据悉,pandas库还提供了数据库查询操作函数read_sql_query。 只需要传入查询语句和数据库连接引擎即可。 源码注释为ReadSQLqueryintoaDataframe.,意思是:查询数据库的内容以Dataframe对象的形式返回。
query = 'SELECT * FROM real_estate LIMIT 10'
top10 = pd.read_sql_query(query, engine)
print(top10)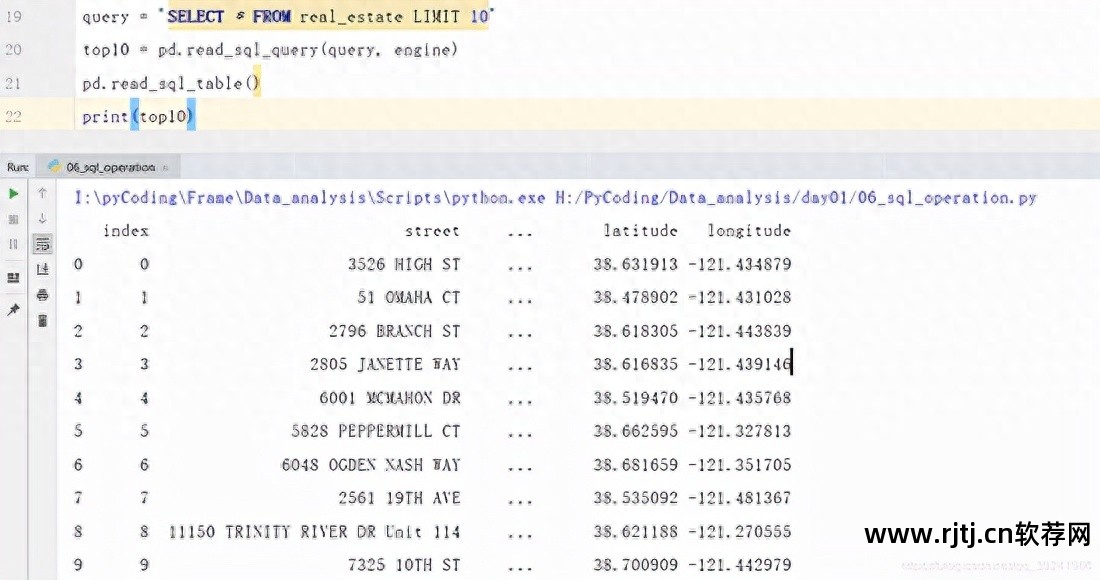
5.Python与各种数据库交互代码
a.Python和MySql
# 使用前先安装 pymysql 模块 :pip install pymysql
# 导入 pymysql 模块
import pymysql
#连接数据库,参数说明:服务器,用户名,数据库password,数据库名称
db = pymysql.connect("localhost","root","root","db_test")
#使用cursor()方法创建一个游标对象
cursor = db.cursor()
#使用execute()方法执行SQL语句
cursor.execute("SELECT * FROM test_table")
#使用fetall()获取全部数据
data = cursor.fetchall()
#关闭游标和数据库的连接
cursor.close()
db.close()b.Python和MongoDB
# 使用前先安装 pymongodb 模块 :pip install pymongodb
# 导入 pymogodb 模块
import pymongo
# 连接数据库,参数说明:服务器IP,端口号默认为27017
my_client = pymongo.MongoClient(host="127.0.0.1",port=27017)
# 直接通过数据库名称索引,有点像字典
my_db = my_client["db_name"]
# 连接 collection_name 集合,Mongodb里集合就相当于Mysql里的表
my_collection = my_client["collection_name"]
datas = my_collection.find() # 查询
for x in datas :
print(x)c.Python和Sqlite
# 使用前先安装 sqlite3 模块 :pip install sqlite3
'''
sqlite数据库和前面两种数据库不一样,它是一个本地数据库
也就是说数据直接存在本地,不依赖服务器
'''
# 导入 sqlite3 模块
import sqlite3
# 连接数据库,参数说明:这里的参数就是数据文件的地址
conn = sqlite3.connect('test.db')
#使用cursor()方法创建一个游标对象
c = conn.cursor()
#使用execute()方法执行SQL语句
cursor = c.execute("SELECT * from test_table")
for row in cursor:
print(row)
#关闭游标和数据库的连接
c.close()
conn.close()