编译:Bing
语音合成,也称为TTS(文本转语音),目前广泛应用于智能家居设备和智能助理等应用中。 论治还报道了许多相关研究项目。
近日,百度研究院推出了TTS成果——ClariNet,成为百度TTS研究的又一里程碑。 之前基于神经网络的TTS模型将优化的文本到频谱图和波形合成模型分开,这可能导致性能不理想。 ClariNet首次使用完整的端到端TTS模型直接将文本转换为波形图形,并且只需要一个神经网络。 其全卷积架构可实现从头开始的快速训练。 ClariNet 在语音自然度方面成功超越了其他方法。 以下为论治对该论文的整理。
论文摘要
WaveNet是DeepMind去年推出的基于深度学习的语音生成模型。 它可以生成并行语音波形,即整个句子中的所有单词都可以同时生成相应的波形。 现在,我们提出了 WaveNet 的替代方案。 我们从自回归WaveNet中提取高斯逆自回归流,并以封闭形式计算KL散度,简化了训练算法并提供了非常高效的蒸馏过程。 除此之外,我们还提出了第一个用于语音合成的文本到波神经架构,它是完全卷积的,可以从头开始快速进行端到端训练。 除此之外,我们还在模型的隐藏表示中成功创建了并行波形生成器。
并行波形生成
在模型中,我们使用高斯自回归WaveNet作为“教师网络”,使用高斯逆自回归流作为“学生网络”。 2018 年,Oord 等人。 提出概率密度蒸馏方法来降低逆自回归流(IAF)最大可能学习的难度。 在蒸馏过程中,学生网络 IAF 尝试将其自身的样本分布与自回归 WaveNet 中训练的样本进行匹配。 然而,学生网络IAF的输出逻辑分布与教师网络WaveNet的输出之间的KL散度是不兼容的,必须使用蒙特卡罗方法进行粗略计算。 最终的并行WaveNet在蒸馏过程中需要进行双采样:首先将白噪声输入到学生网络中,然后从学生网络的输出分布中选择多个不同的样本来估计KL散度。
但在我们的模型中,通过添加高斯设置,密度蒸馏方法只需要单个白噪声样本,然后将其输入到闭合 KL 散度计算中。 我们的学生 IAF 网络在蒸馏过程中使用与教师 WaveNet 相同的条件网络(2D 卷积层)。
文本到 Wave 架构
我们的卷积文本到波形架构如下所示:
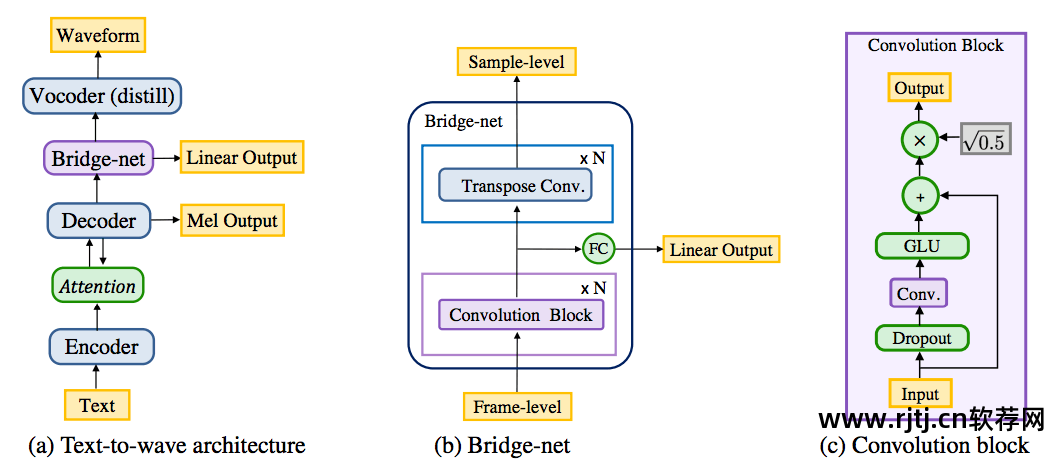
它是基于 Deep Voice 3 创建的,Deep Voice 3 是另一种基于注意力的卷积 TTS 模型。 Deep Voice 3可以将文本特征(如字符、音素、强调等)转换为谱特征(如log-mel声谱和log-线性声谱)。 这些流行特征可以输入到经过波形合成训练的模型中,例如 WaveNet。 相反百度语音合成软件,我们直接将从注意力机制中学到的隐藏表示输入到神经语音编码器中,以端到端的方式从头开始训练整个模型。
我们提出的架构由四个部分组成:
实验流程
我们进行了几组实验来评估所提出的并行波形生成方法和文本到波形结构。 我们使用 20 小时的英语语音作为训练数据,并将音频下采样至 24kHz。
首先我们测试生成语音的自然度,用 MOS 分数表示:

结果表明,高斯自回归WaveNet的输出水平与MoGul和softmax相当,优于MoL。
然后,我们从 20 层高斯自回归 WaveNet 中提取出 60 层并行学生网络百度语音合成软件,该网络由 6 个堆叠高斯逆自回归流组成,每个流由 10 层 WaveNet 参数化。 我们测试了前向和后向KL散度,结果如下:
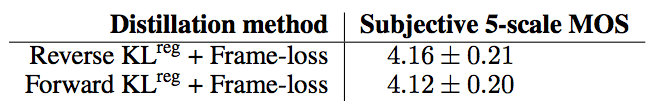
两种蒸馏方法都取得了不错的分数,我们希望添加感知和对比损失能够在未来进一步改善。
最后,我们从头开始训练文本转波形模型,并与 Deep Voice 3 中的类似模型进行比较。结果如下:

该分数表明文本到波形模型的性能明显优于其他模型,并且具有精炼语音编码器和自回归神经编码器的模型的性能处于可比水平。
具体的语音合成可以看下面的例子:
结论
百度在语音合成方面确实下了很大的功夫。 今年3月,他们还推出了神经语音克隆系统,只需输入少量样本即可合成逼真的语音。 今天的 ClariNet 是语音合成领域的另一个里程碑。 它是该领域第一个真正的端到端模型,并在 GPU 上实现了更高质量的结果。 具体技术细节请参见原论文:arxiv.org/pdf/1807.07281.pdf
