可以说,2017年的PC硬件市场迎来了久违的喧嚣。 不仅整体形势趋于稳定甚至开始复苏,几乎各类配件也呈现出井喷式发展,新技术、新产品不断涌现,有点第二春的意思。 的一种感觉。
核心板方面,CPU处理器无疑是最引人注目的。 AMD忍耐了十年,凭借新Ryzen上演了完美反击。 英特尔也纷纷发起反击。 终于,它慢慢地停止了“挤牙膏”。 两家公司来了又去,大家都看得如痴如醉。 他们也直接带动了主板、存储、机电散热等配件以及整机的长足进步。
GPU显卡最受大家欢迎的当然就是疯狂的“挖矿”了。 在技术和产品方面,NVIDIA Pascal(帕斯卡家族)完善了布局,下一代Volta(伏特)架构也开始出现,而AMD也终于推出了新一代高端架构“Vega”,使得人们翘首以待!

此刻距离AMD上一代基于斐济核心的旗舰显卡Radeon R9 Fury X诞生已经过去了两年零一个多月的时间,这在过去是非常不可思议的。
尤其是近一年多来,NVIDIA Pascal家族一步步前进,从高到低无所不包。 虽然AMD也有新的Polaris核心,但毕竟是小核心。 它在中低端市场表现稳定,但没有大哥领先,始终缺乏信心。
最早的说法是 Vega 核心将于 2016 年 10 月推出,但由于很多玩家尤其是粉丝的焦急等待,又过了十个月,Vega 才终于准备好。 此时,它与主要竞争对手GTX已经相差甚远。 1080/1070的诞生已经一年零三个月了。
至于Vega为何迟到了这么久,AMD高级副总裁兼Radeon技术事业部首席架构师Raja Koduri向我们解释道:
一是14nm工艺,这是AMD第一次在CPU和GPU上使用相同的工艺。
其次,Vega架构是一个全新的设计,是自下而上开始的。 现在我们正在设计一种新的高性能计算架构,它不仅需要擅长高端游戏,还可以满足图形工作站、高性能计算、机器学习等方面的需要。
当然,AMD作为唯一一家同时拥有高性能CPU和GPU计算平台的公司,并不是很富有。 它还面临着两个强大的敌人,英特尔和英伟达,它们可以分别专注于一个领域。 可以说是很不容易的。 所采取的每一步都值得尊重。

我们再谈谈维加。 作为全新设计的高性能核心,它肩上的担子非常重。 玩游戏只是一方面。 它有很多事情要做。
事实上,在此之前,维加家族就已经逐渐开始扎根,甚至可以说逐渐兴盛起来。
在服务器和高性能计算领域,我们看到了直接面向NVIDIA Tesla系列、完美匹配自家EPYC服务器处理器的Radeon Instinct MI25;
在图形工作站领域,我们有Radeon Pro WX 9100和Radeon Pro SSG,它们不仅与NVIDIA Quadro系列竞争,而且后者也是第一个集成显卡和容量高达2TB的SSD 。 据说Radeon Pro 64/56也会紧随其后;
在游戏开发领域,大家都熟悉Radeon Vega Frontier Edition风冷和水冷版本。 这也是AMD对NVIDIA Titan X/Xp的回应;
在游戏领域,AMD也在努力,推出了三款产品(或者四款),未来还会有更多惊喜!

【Vega架构解析:AMD GPU五年来最具革命性的进步】
不知不觉间,显卡品牌Radeon已经存在了17年,陪伴了很多DIY玩家度过了青春岁月。 时代在变,Radeon 面临的需求也变得更加多样化。
AMD在技术白皮书中特别指出,除了传统游戏不断冲击视觉技术的极限之外,GPU也面临着来自更广泛需求的挑战。 从机器学习到专业可视化,从虚拟化到虚拟现实,GPU的计算能力也在快速进步。 满足极大规模数据集的需求,但GPU存储能力并未得到显着提升。
为此,AMD全新设计了Vega架构,这是GCN图形架构诞生五年来AMD GPU最具革命性的变化。

不过新核心的变化实在是太多了,几乎涵盖了方方面面,而且很多都太专业了,所以这里我们挑选了几个重点跟大家分享一下。
1.Vega 10:高集成大核
Vega架构的首款产品是“Vega 10”,是一款规模较大的芯片,定位于高分辨率游戏、VR虚拟现实、高性能计算和机器学习、高负载工作站等领域。
它采用14nm LPP FinFET工艺制造,集成125亿个晶体管,核心面积486平方毫米。
相比之下,上一代28nm工艺的大核斐济集成了89亿个晶体管,但面积却只有596平方毫米。 这意味着Vega 10核心晶体管尺寸足足大了40%,但面积却减少了18%!
此外,同样采用14nm工艺的Polaris 10核心集成了57亿个晶体管,核心面积为232平方毫米。 与Vega 10相比,它的晶体管数量增加了1.2倍vega软件教程,面积增加了1.1倍,集成度也得到了提高。
Vega 10核心经过优化后,可以充分利用FinFET工艺的低漏电率,而且频率比之前任何Radeon显卡都要高。 官方标称最大加速频率为1.67GHz,但实际运行中可以超过1.7GHz。 在实际测量中我什至看到了1.75GHz。
相比之下,上一代Fiji核心只能加速到1GHz左右,而Polaris 10可以加速到1.3GHz以上。
Raja表示,14nm工艺对于CPU和GPU来说是平衡的。 可以实现CPU上的高主频和GPU上的高集成度。 例如,Vega比Fiji核心小得多,但性能却高得多。
Vega 10核心仍拥有64个计算单元和4096个流处理器。 它与斐济大小相同,但架构先进,频率更高,单精度浮点计算性能达到惊人的13.7TFlops(每秒钟13.7万亿次计算),还支持16位数学计算,比斐济的计算速度减半。 - 27.4TFlops 的精密浮点性能。
Vega 10也是AMD第一个使用Infinity Fabric互连设计的GPU核心,Zen处理器中也是如此。 这种低延迟的SoC型互连总线可以在芯片的不同模块之间提供一致的通信。 这也使得芯片设计更加灵活、灵活,并且可以模块化,可以根据需要随时添加不同的配置和模块。
在Vega 10芯片中,Infinity Fabric将图形核心与其他主要逻辑模块连接起来,包括显存控制器、PCI-E控制器、显示引擎、视频加速器等,也为未来的APU奠定了基础。

2.全新显存架构和高带宽缓存控制器(HBCC)
GPU通常需要将所有需要的数据集或资源保存在本地显存中,因为使用PCI-E等外部通道将无法保证足够的带宽或延迟。
随着软件内存管理变得越来越复杂,这给开发者带来了越来越大的挑战,而显存的成本决定了不可能把容量做得特别大。
为此,Vega架构可以使用本地显存作为最后一级缓存。 如果GPU想要访问的部分数据不在显存中,则可以通过PCI-E总线获取所需的内存页面并将其保存在高带宽缓存中,而不是让GPU停下来等待要完成的所有必需资源的副本。
页面通常比整个纹理等资源小得多,因此可以快速完成复制,后续访问直接从缓存中拉取,因此延迟自然很低。
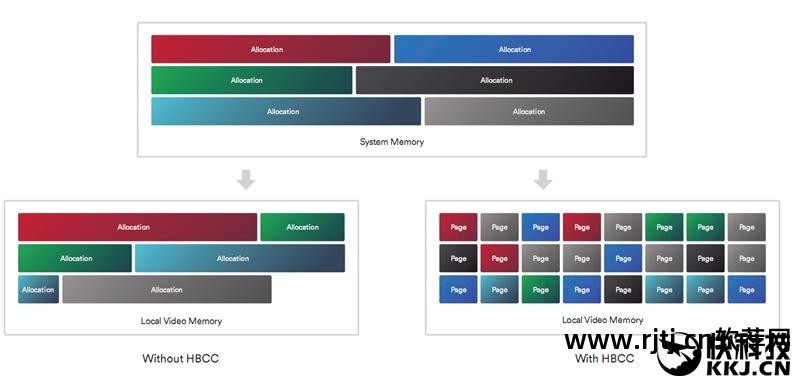
这主要得益于Vega架构的全新高带宽缓存控制器(HBCC),它可以使用远程内存作为本地缓存,使用本地显存作为末级缓存。
HBCC 支持 49 位寻址,最多可访问 512TB 的虚拟寻址空间。 现代CPU的寻址空间只有48位,比最大10+GB显存大几个数量级。
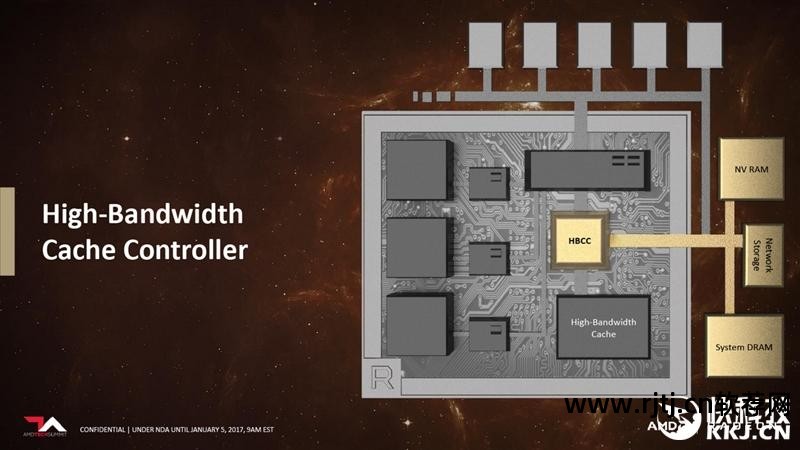
HBCC被认为是Vega架构中最大的创新。 简单来说就是整个系统内存都可以作为显存,相当于显卡可以拥有TB级的高速显存。 无论性能还是容量,都不是问题。
换句话说,它实现了某种程度的集成内存池,AMD 将其称为“HBCC 内存区域”(HMS)。
Radeon Pro SSG之所以能够搭载2TB SSD,就是得益于这种设计,消除了GPU到SSD的间隙,可以直接访问其中的数据,从而大大减少延迟和过载。
为了最大限度地发挥这一设计,Vega架构的其他部分也做出了针对性的调整。 例如,二级缓存发挥了核心作用,容量翻倍至4MB,所有图形块都直接与其相连。 过去,像素引擎是有自己的缓存的。
当然,HBCC设计也需要开发者学习和适应,才能挖掘和释放其最大潜力,并不是一定要使用。 开发者如果对显存容量和性能没有特别高的要求,仍然可以走传统路线。
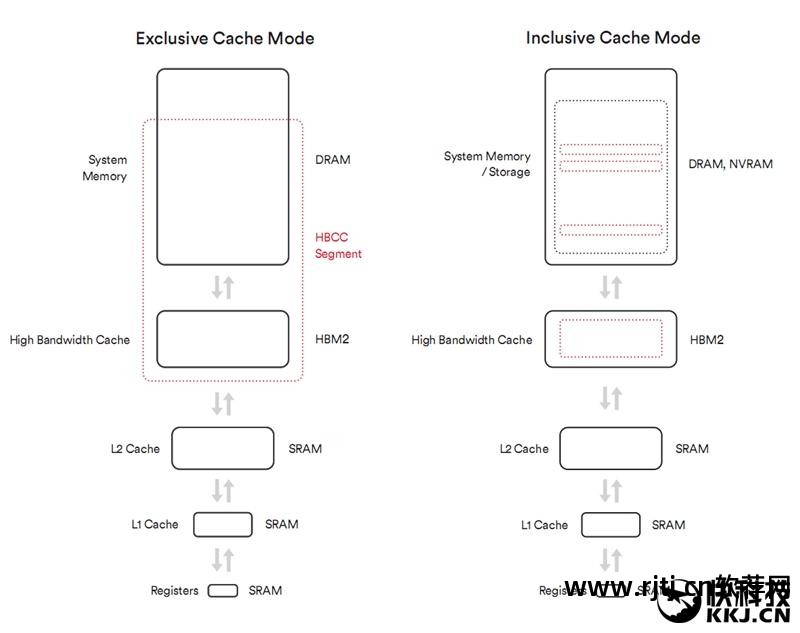
显存方面,Vega搭载了第二代高带宽显存HBM2,与Fiji一样与GPU核心集成封装,并采用硅中介层与GPU进行物理互连。
得益于新技术和工艺,HBM2最多可以堆叠8个,每个HBM2最大容量为8GB。 Vega专业卡使用两个16GB,RX Vega家族配备两个8GB。
同时,HBM2的每个堆栈的位宽为1024位,因此只需要很低的频率即可提供极高的带宽。
在显卡驱动控制面板中,用户可以根据自己的需要手动调整HMS容量范围。
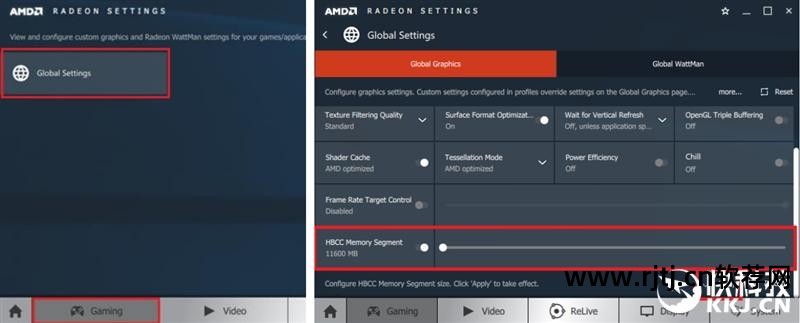
3. 下一代计算单元(NCU)
AMD GCN架构的核心模块是计算单元(CU),Vega也是如此,但也进行了全面翻新,正式称为下一代计算单元(NCU)。
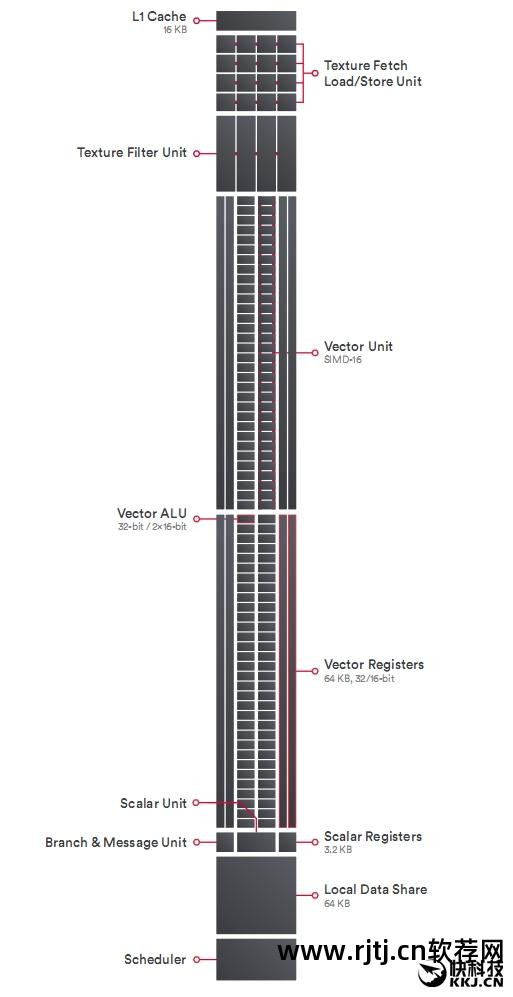
NCU的一大亮点变化是增加了Rapid Packed Math/RPM,允许同时执行两个FP16半精度运算,并支持丰富的16位浮点和整数指令集,包括FMA、MUL、ADD、MIN /MAX/MED、位移位等
一般来说,日常游戏和3D渲染对单精度FP32和双精度FP64的要求比较高。 在大规模深度计算中,FP16半精度非常关键。
Vega首次支持半精度计算。 每个NCU有64个ALU,可以灵活地执行严格的数学运算指令。 例如,每个周期可以执行512次8位数学计算,或256次16位计算,或128次32位计算。 。 这不仅充分利用了硬件资源,还大大提高了Vega在深度学习方面的性能。

RPM专门用于加速FP16半精度运算速度。 例如,新的着色器可以使用 RPM 将 AMD 一直引以自豪的 TressFX 头发渲染中每秒可渲染的头发数量增加一倍。 因此,RPM可以帮助GPU核心执行更快、更强大的物理计算。
NCU还可以同时进行计算和图形处理,并且可以根据不同的负载改变SIMD单元的宽度。 结果是,过去需要多个计算单元的任务现在只需一个计算单元即可完成,不会造成浪费。
结合各种改进,Vega 10 核心每秒可以执行 27 万亿次浮点计算,或 55 万亿次整数运算。

4.下一代几何引擎
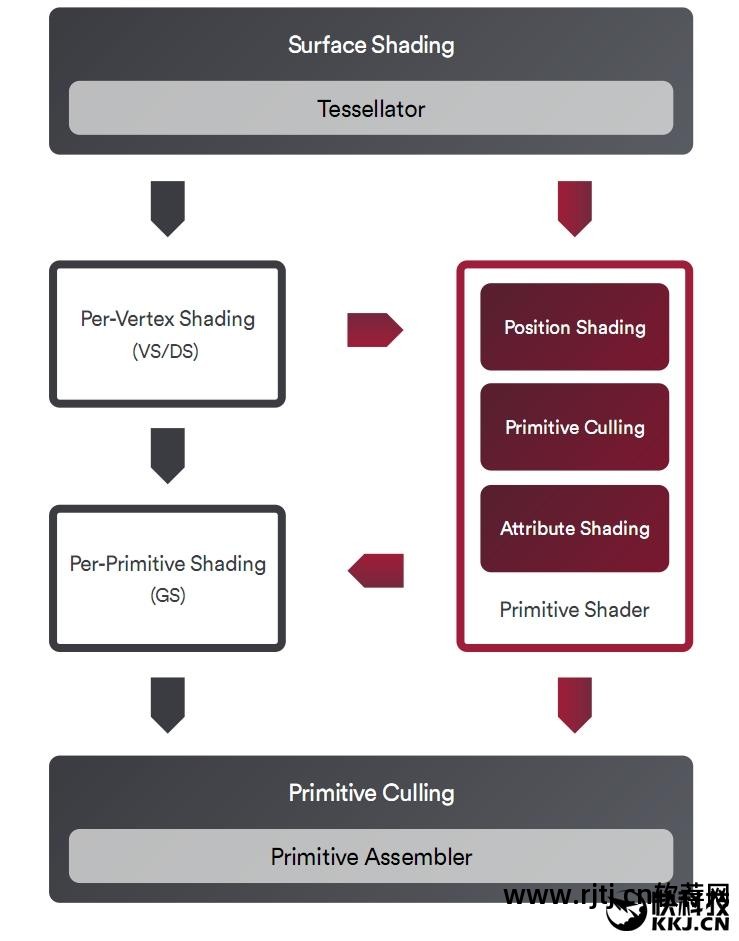
Vega 的整个几何引擎针对更高的三角形吞吐量进行了优化,添加了新的快速硬件路径,使其比以往更加灵活和可编程。
Vega几何引擎有很多创新,其中最有代表性的就是新的Primitive Shader,它可以合并部分几何处理管线,抛弃隐藏的和不必要的图元,代之以新的高效着色类型,而且启动速度非常快,每个时钟周期的峰值原始剔除率是以前的四倍。
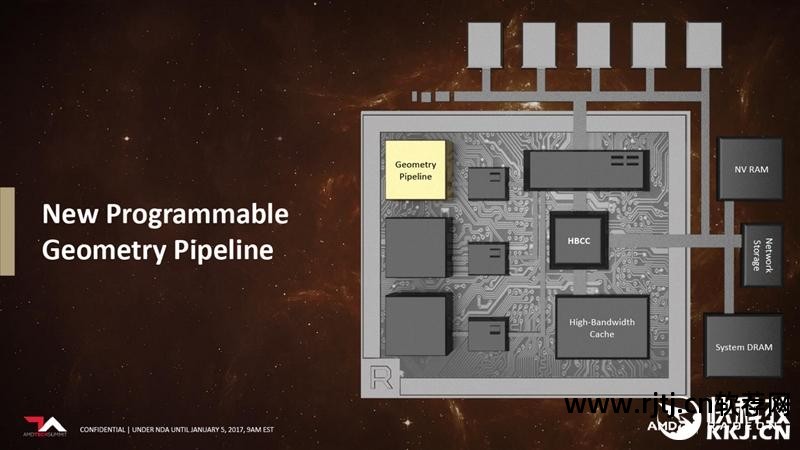
Vega 10 有四个几何引擎。 通过添加新的图元着色器,每个时钟周期的最大图元吞吐量可以超过 17,而之前仅为 4。
同时,Vega架构还增加了新的智能负载分配器(IWD),可以根据实际情况不断调整管道设置,以更好地平衡各个几何引擎之间的负载,提高利用率。
5. 下一代像素引擎
随着4K/5K/8K超高分辨率和240Hz高刷新率显示器的出现和普及,以及VR虚拟现实的进一步发展,显卡的像素吞吐量也面临着越来越大的压力。 Vega重新设计了Pixel引擎,添加了很多新功能。
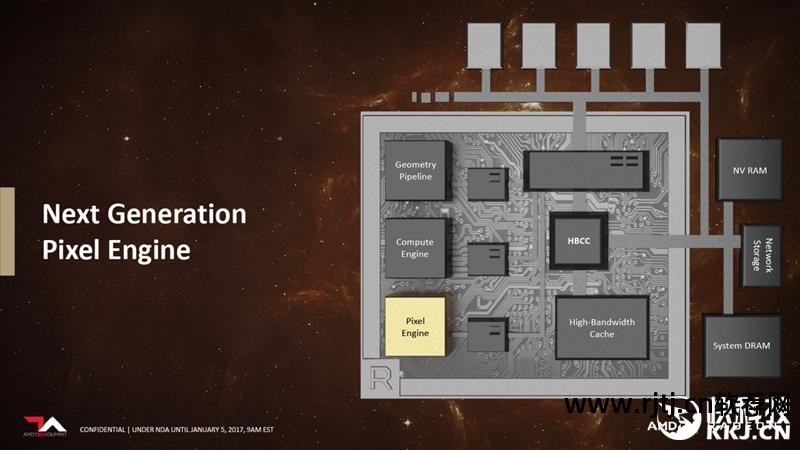
例如,Draw Stream Binning Rasterizer (DSBR) 可以消除 GPU 上不必要的处理和数据传输,提高性能并降低功耗。
Vega支持基于瓦片的光栅化和像素集成读取(binning),可以进一步提高流处理器的利用效率,减轻CPU调度3D图像渲染指令的压力。这两种渲染技术早已在移动GPU上流行,并且NVIDIA GTX 750系列也开始支持它们。
Vega可以及时剔除无效渲染单元,并在片内缓存中进行光栅化。 同时打破了以往架构中像素和纹理访问不一致的问题,实现了硬件存储一致性,即各级缓存的数据都是最新的。 缓存被统一为渲染后端服务。
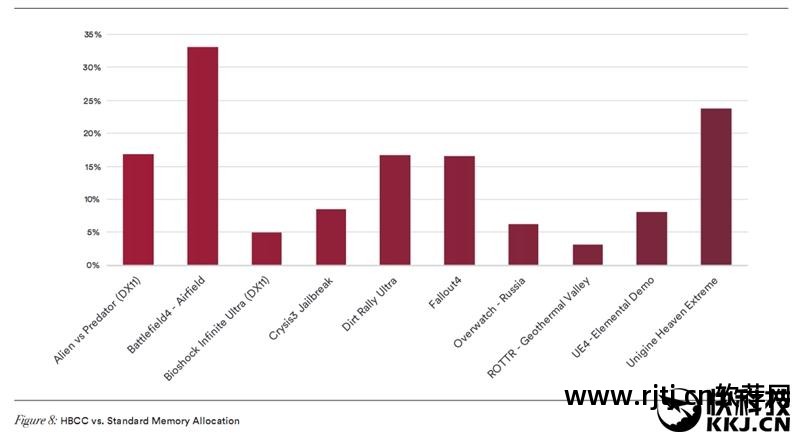
AMD表示,开启DSBR技术后,可以实现游戏帧率提升10%,同时在不增加功耗的情况下节省高达33%的显存带宽。
在SPECviewperf 12 energy01专业性能测试中,DSBR的性能提升了一倍以上。
此外,Vega新一代像素引擎还集成了最广泛、最完整的DX12 Feature Level 12_1功能,并全面支持Vulkan 1.0。
因此,Vega 10非常适合先进的图形技术开发,以及体验新技术。

6.丰富的显示输出
A卡在显示输出方面一直拥有强大的功能和优势,Vega也不例外。
它支持DisplayPort 1.4标准和HDR3、MST、HDR以及各种高精度色彩格式。 它还支持 HDMI 2.0。 它可以输出高达 4K/60Hz、12 位颜色通道和 4:2:0 编码。 DisplayPort 和 HDMI 也支持 HDCP。 内容保护。
当然,FreeSync技术是必不可少的,支持大量可变刷新率游戏,而且还有FreeSync 2,可以将HDR内容以低延迟映射到附加显示器。
Vega 可以像 Polaris 一样支持多达 6 个屏幕输出,但具有更高的位深度、分辨率和刷新率。 例如,在32位HDR模式下,最多支持2个4K 120Hz、3个5K 60Hz(单数据线),3个8K 30Hz、3个4K 60Hz,64位HDR模式下最多支持1个4K 120Hz和1个5K 60Hz。

视频解码方面,Vega支持HEVC/H.265 Main10,分辨率高达4K/60Hz,支持10-bit HDR。 H.264也可以做到4K/60Hz,VP9也可以支持4K。
编码方面,HEVC/H.265格式支持1080p240、1440p120和2160p60,而H.264则支持1080p120、1440p60和2160p60,相比Polaris来说是一个显着的改进。
即使在SR-IOV虚拟化中,Vega也可以直接共享GPU的视频编解码加速,并支持最多16个并发用户会话。
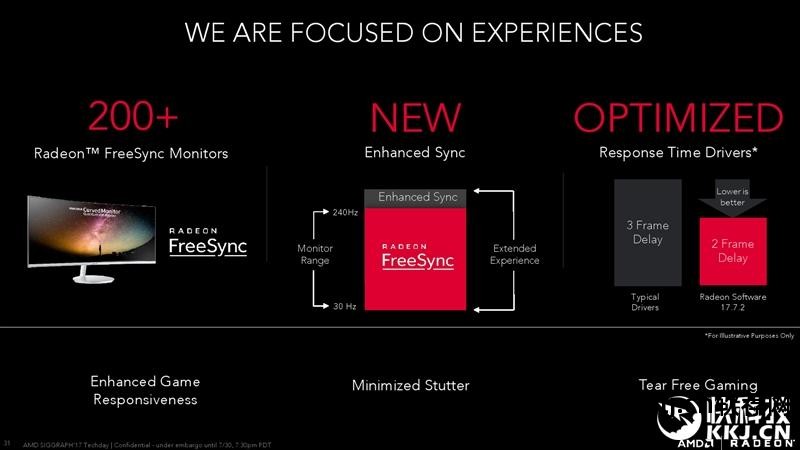
当然,还有监视器。 AMD的FreeSync技术已经广泛普及。 支持200多种型号,规格齐全,分辨率从2K到4K,刷新率从60Hz到144Hz。
在FreeSync的基础上,AMD还推出了Enhanced Sync技术,支持240Hz以上的更高刷新率显示器,可以最大限度地减少延迟。
此外,AMD还在新驱动中优化了游戏响应时间,减少帧延迟,尽可能消除游戏画面撕裂。

【RX Vega显卡阵容解析:不同级别的四款车型】
与以往首次发布仅一两款型号的做法不同,AMD RX Vega游戏卡此次共有四款不同型号,外观风格各异,两种风格。
有趣的是,这是AMD显卡历史上首次将开发代号直接用于产品型号中。
为何如此? Raja Koduri向我们解释,这主要有两个原因:一是Vega架构是全新设计的,不仅如此,整个SoC芯片也是全新的;二是Vega架构是全新设计的,不仅如此,整个SoC芯片也是全新的。 其次,Vega代号发布后,社区和玩家都非常喜欢这个名字。

旗舰型号Radeon RX Vega 64共有三个不同版本。 水冷银版和风冷银版基本沿袭了之前Vega Frontier Editon开发卡的风格。 它拥有非常先进的拉丝金属外壳,后部有一个30mm单风扇,但颜色从专业卡的蓝色和金色切换为银色。
显卡正反面均有红色Vega LOGO,右上角饰有三边刻有字母R的立体信仰灯,风格十足。

Radeon RX Vega 64风冷黑色版和Radeon RX Vega 56风冷黑色版采用黑色类肤材质外壳vega软件教程,没有Vega LOGO和R字母灯,但风扇依然是单30mm。

具体规格方面,Radeon RX Vega 64水冷银版最高,拥有64个计算单元、3584个流处理器、256个纹理单元、64个ROP单元。
核心基础频率和加速频率分别为1406MHz和1677MHz,浮点性能为单精度13.7TFlops和半精度27.5TFlops——这些都是之前架构分析部分所推崇的指标。
配备2048位宽8GB HMB2高带宽内存(两条),等效频率1890MHz(真实频率945MHz),带宽483.8GB/s。
输出接口为3个DisplayPort和1个HDMI,整卡功耗为345W。
除了采用风冷外,RadeonRX Vega 64风冷银版(国外也称限量版)将核心频率降低至1247-1546MHz。 浮点性能也达到了单精度12.66TFlops和23.5TFlops,功耗为295W。

RadeonRX Vega 64风冷黑色版本与风冷银色版本的规格完全相同,只是更换了散热器。 与之前的RX 400/500系列公版类似,同样拥有类肤质材质外壳。

Radeon RX Vega 56风冷黑色版本的外观与上面相同。 规格精简为56个计算单元和3584个流处理器。 然而,它仍然有 256 个纹理单元和 64 个 ROP 单元。 核心频率也进一步降低至1156-1471MHz。 ,浮点性能单精度10.5TFlops,半精度21.0TFlops。
显存仍为2048位8GB HBM2,但等效频率降低至1600MHz,带宽为410GB/s。
同时整卡功耗降低至210W。
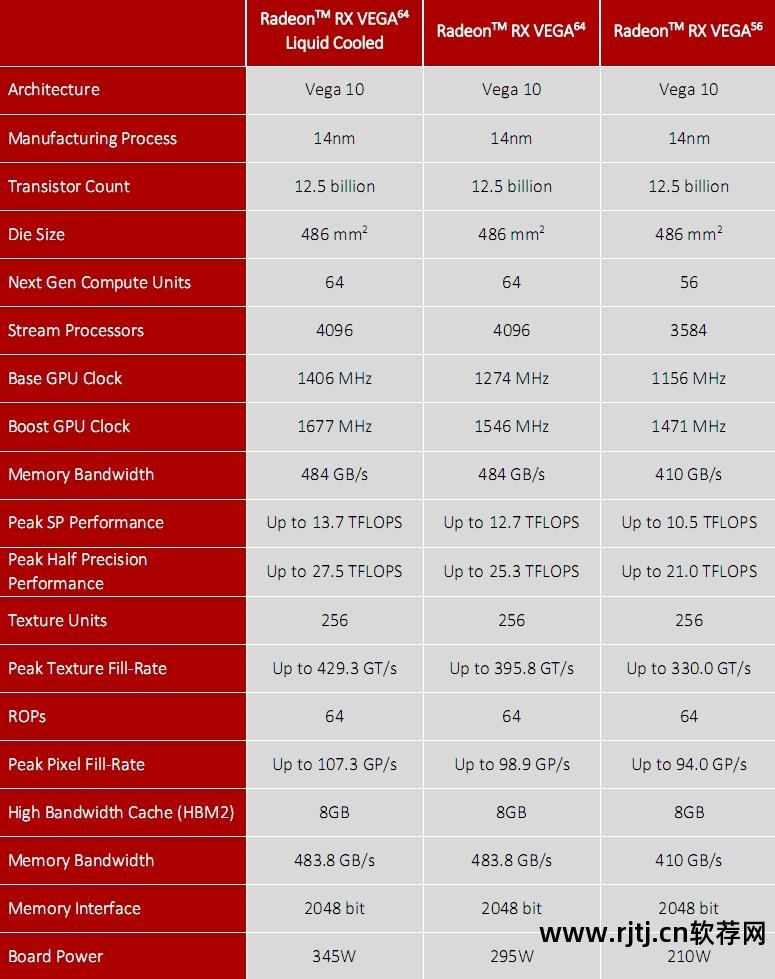
Radeon RX Vega 64/56首发阵容的完整规格表,主要是核心和显存大小和频率的差异。
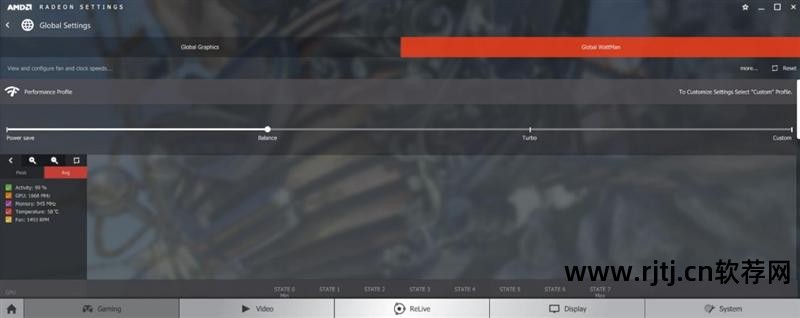
GPU技术发展到今天,其实已经非常灵活了。 刚才提到的各种频率并不是静态的。 例如AMD显卡现在普遍支持Radeon WattMan动态调整技术。 所谓的加速频率并不是一个极限值,而是一个游戏中的典型平均频率,瞬时频率会完全更高。
基频代表底线。 只有那些负载最高、要求最苛刻的应用程序才会允许显卡始终运行在这个频率水平。
在驱动中,玩家还可以根据自己的情况选择节能、平衡、加速等不同的配置,让显卡运行在最合适的频率上。 当然,他们也可以定制自己需要的频率。
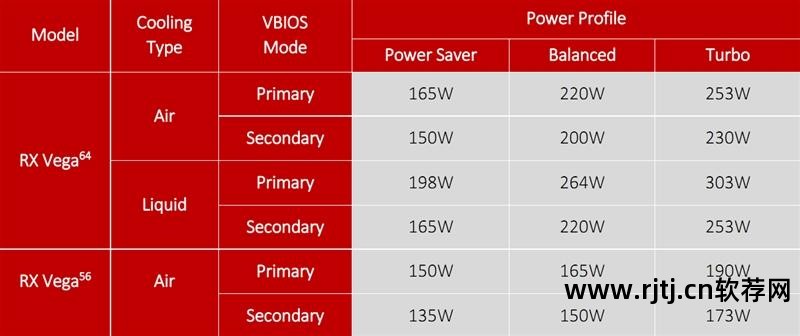
不同的配置级别对应不同的功耗,并且每张卡都有两种不同的BIOS方案,可以直接通过切换显卡上的开关进行切换。
【RX Vega 64水冷版图片欣赏:信仰与X风格在一起】
本次评测我们拿到了顶级的Radeon RX Vega 64水冷银色版本和Radeon RX Vega 56风冷黑色版本。 我们来看看最华丽的水冷版本。

显卡和水冷散热器静静地躺在盒子里

