最强大的 OCR 文本识别解决方案
——OCR处理方案二
斋吴心 制片人
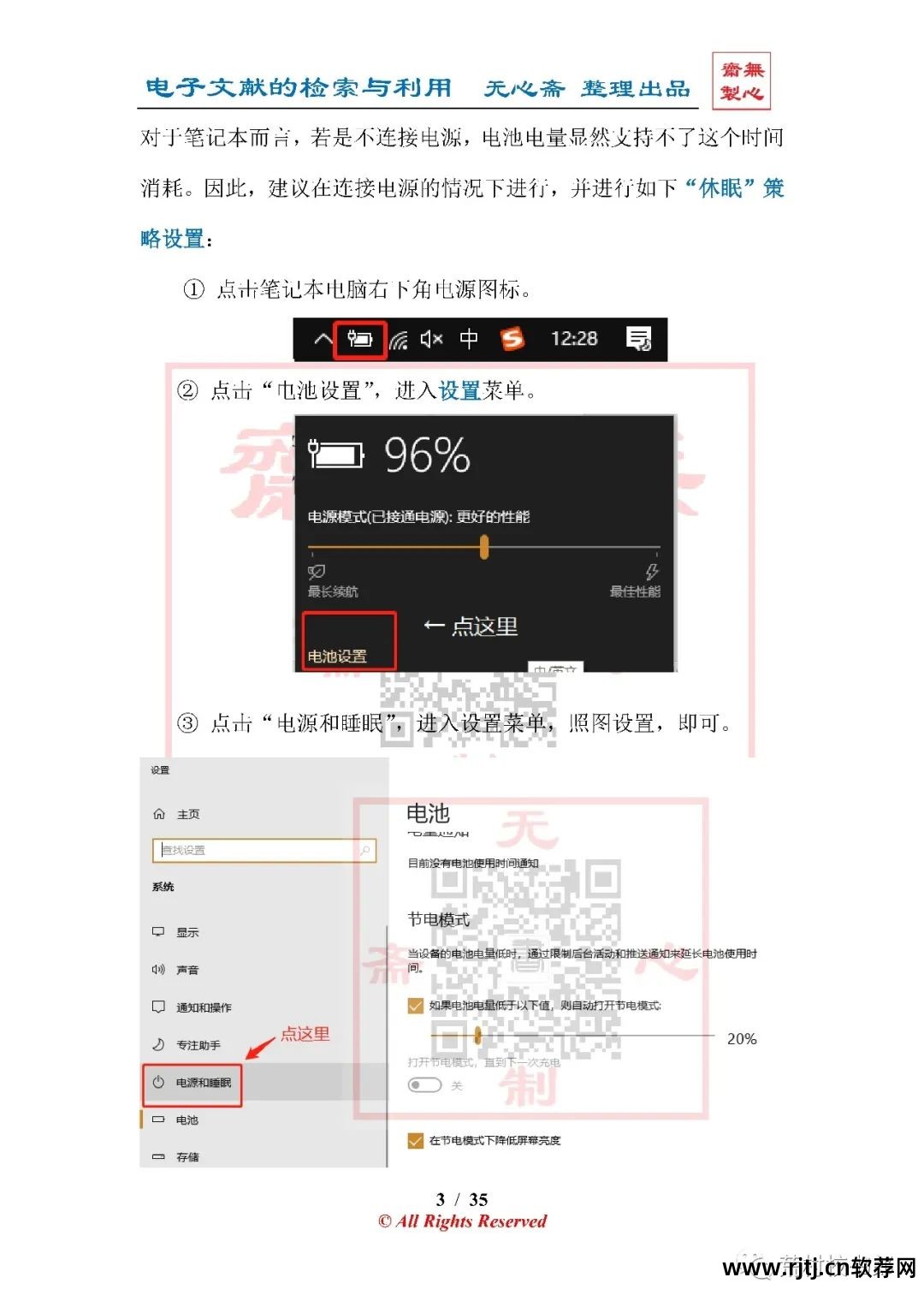
经过不断的努力汉王ocr文字识别软件教程,终于被淘汰了。 由于内容较多,再加上我的笔记本配置太差,早上Edge浏览器就崩溃了。 编译的部分没有及时保存。 现在刚刚修复并发布,所以更新时间被推迟了。 在这里我也想向读者们解释一下。
本文是前天发布的推文“”的第一部分,而前天发布的内容实际上是这篇文档的第二部分。 因为图片太多,所以分成两篇。 后续将推出“PDF使用技巧”系列文章合订本汉王ocr文字识别软件教程,将合二为一并进行修订和更新。 有需要的可以关注一下。
【高能预警】niubility~~~ ↓
该解决方案不仅对PDF有效,而且对一般图片也有效。
这个解决方案可能是迄今为止最好、最实用、最简单、最重要的是完全免费的OCR解决方案,也是学术界无数工作者的零基础PDF教程。
有需要的请仔细观看和学习。
从那时起,我将不再发表有关专业 OCR 解决方案的文章。
我愿意相信这篇文章足以征服世界。 那些打字的PDF,你应该有意识地颤抖,因为——
一旦你学会了我的这个技巧,你可能就能侧着走了。 (道路千万条,安全第一,请勿使用本方案进行非法操作,否则后果自负。)
最后喊出一句顶级内功:
有了Acrobat在手,你就可以拥有世界上所有的纯文本!
(我只能说这么多,剩下的你们自己体会吧,默契的,这样最好了~~~
)
牛皮做好了,上菜吧! 祝你周末愉快!
本期内容
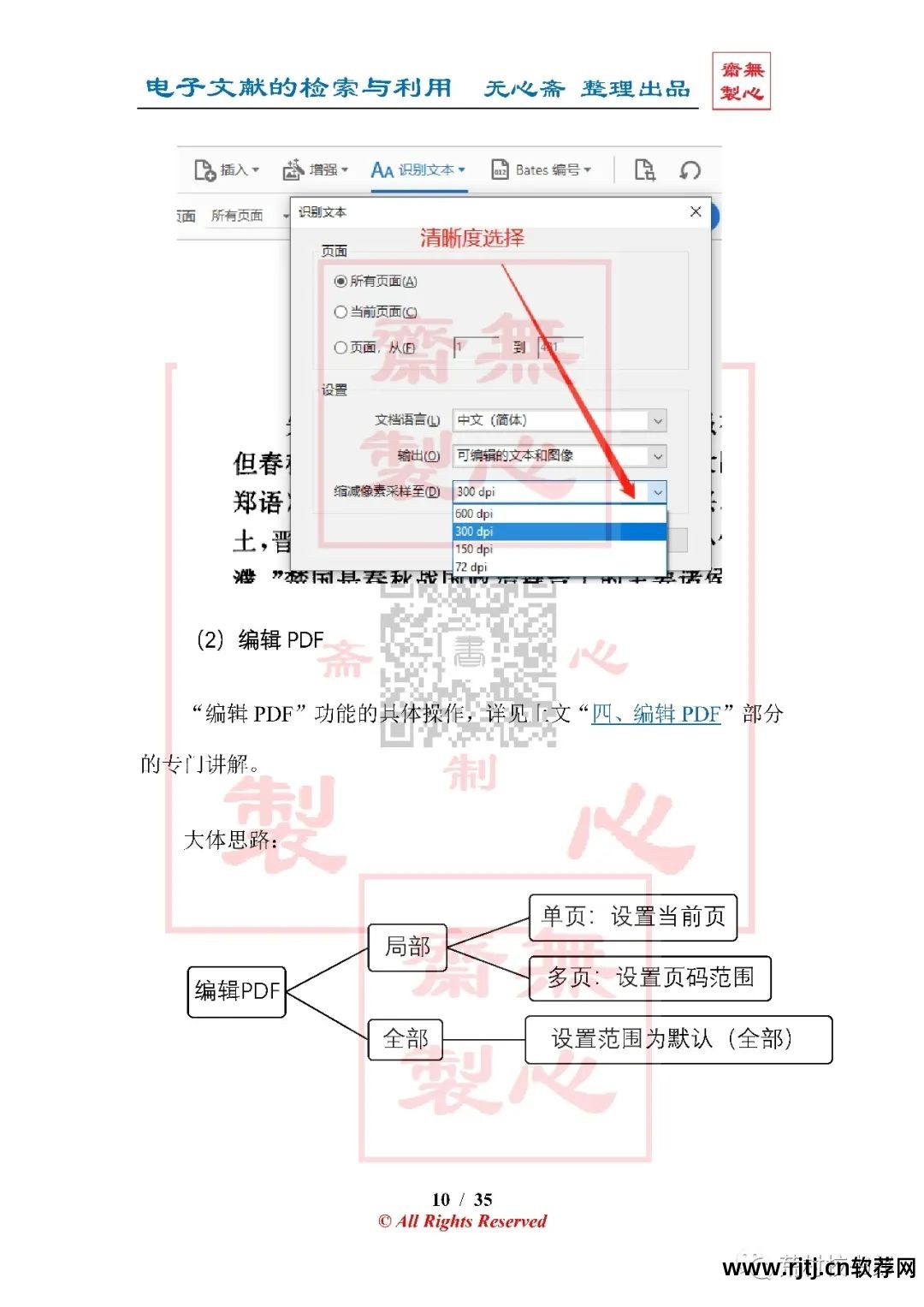
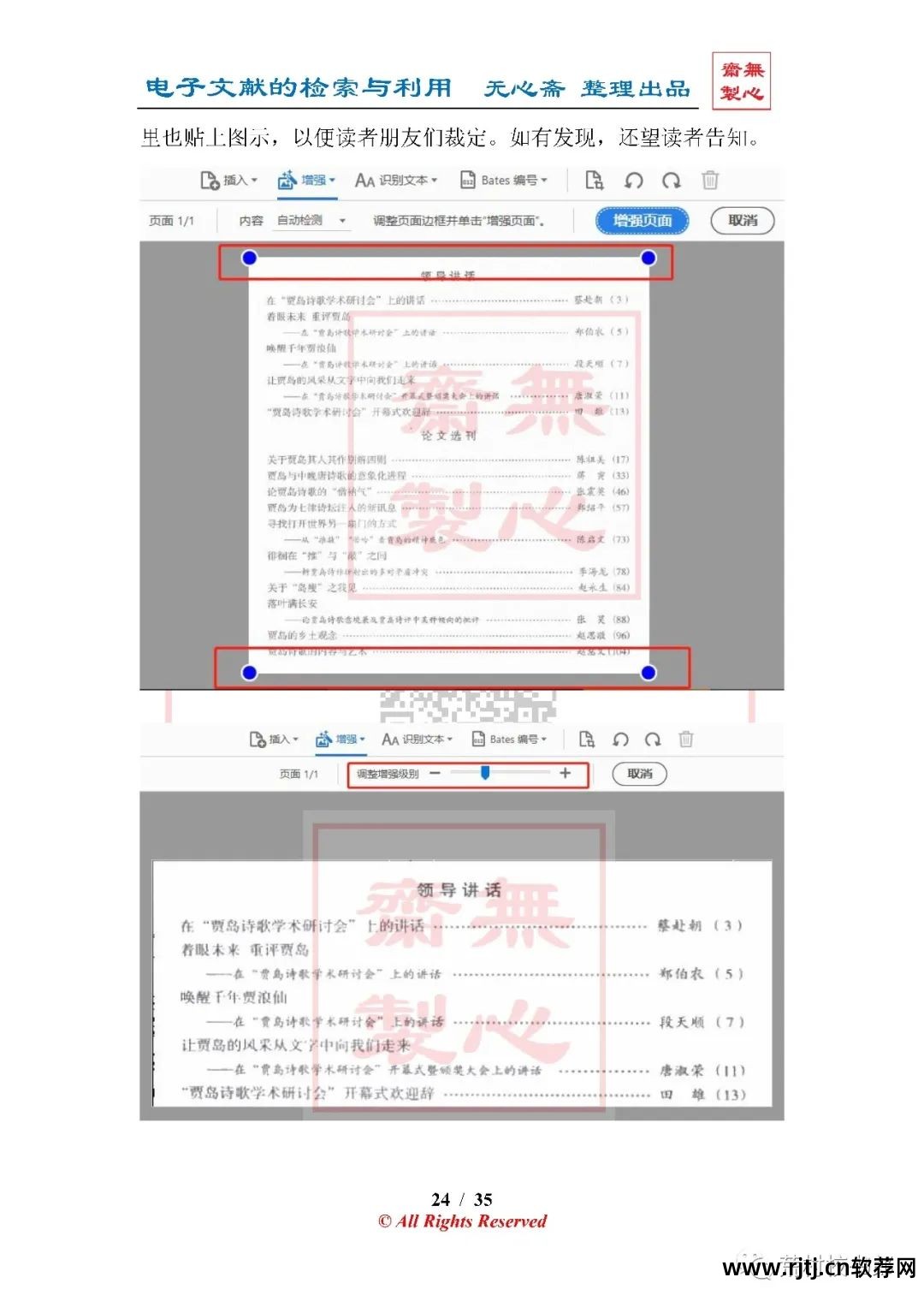
5.增强扫描
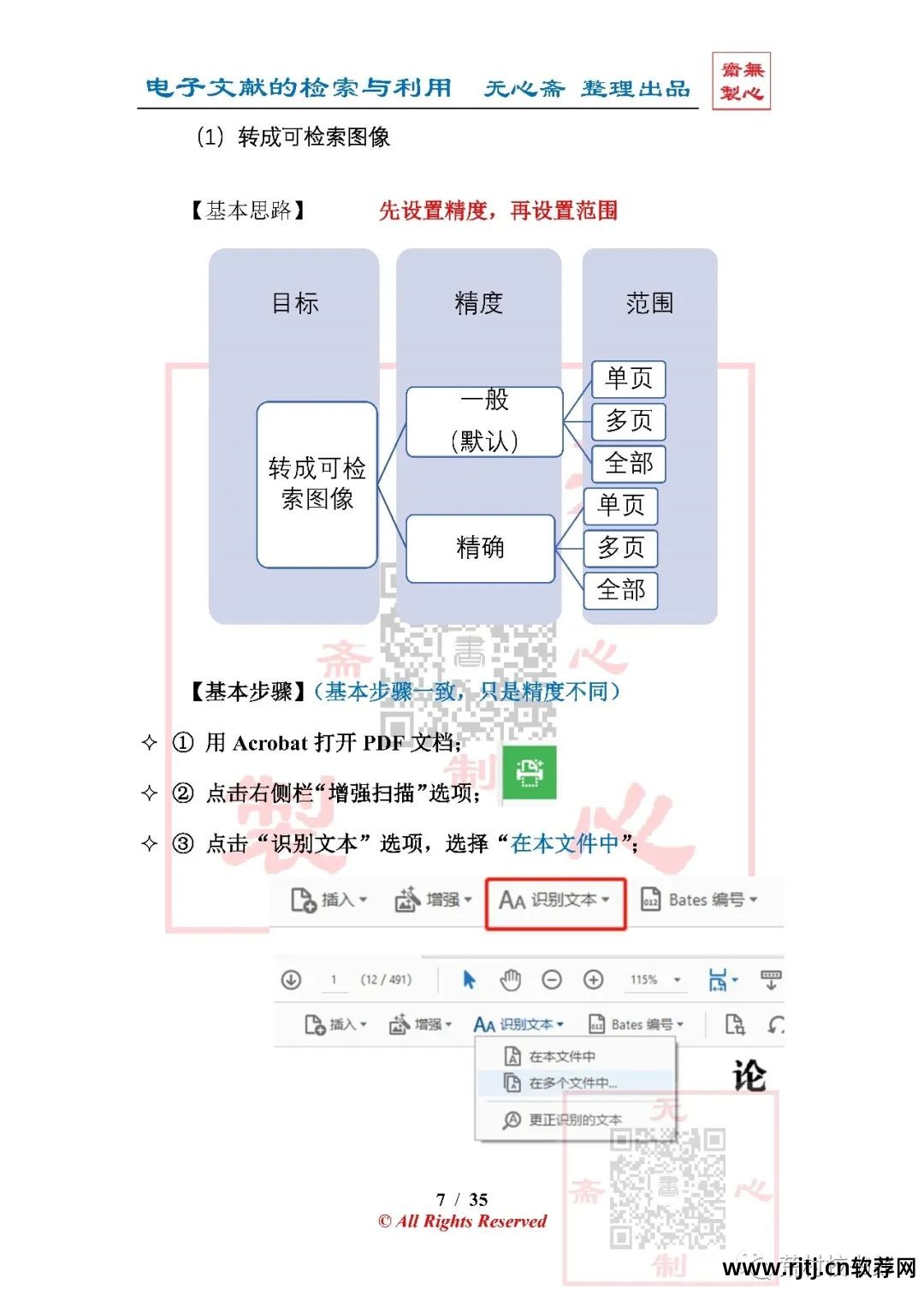
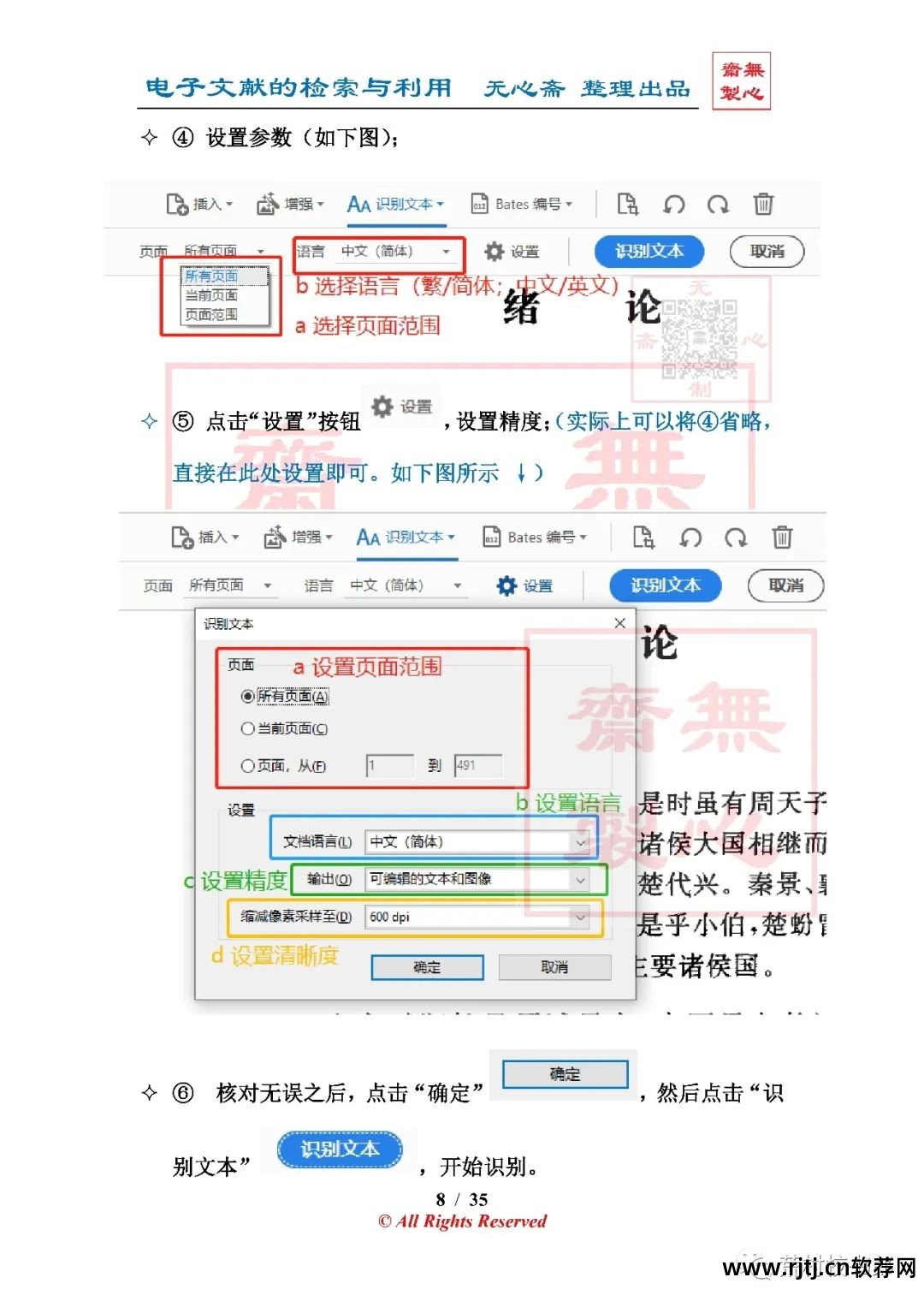
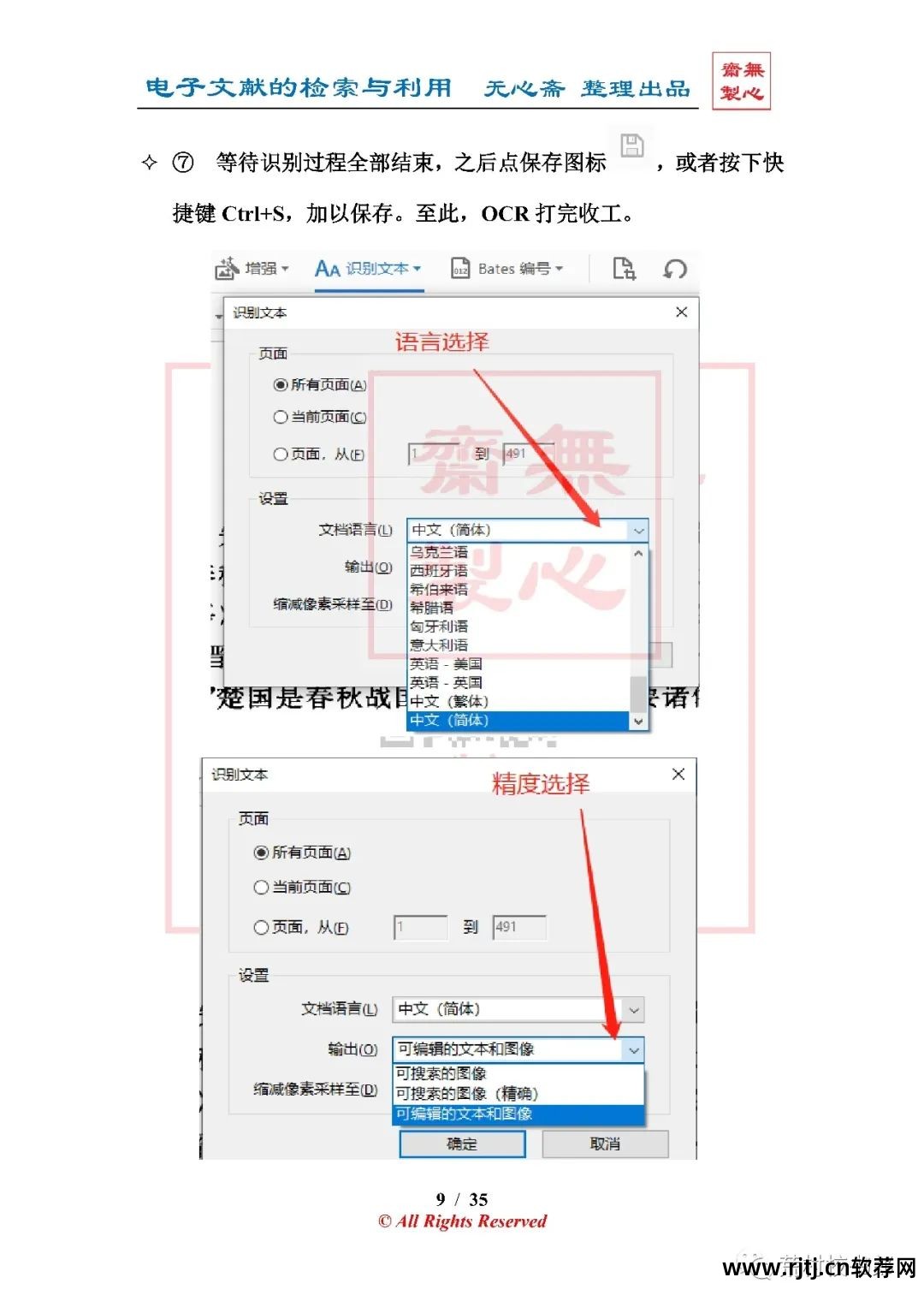
(1)本地字符识别(OCR)
【防范措施】
1.OCR(文字识别)
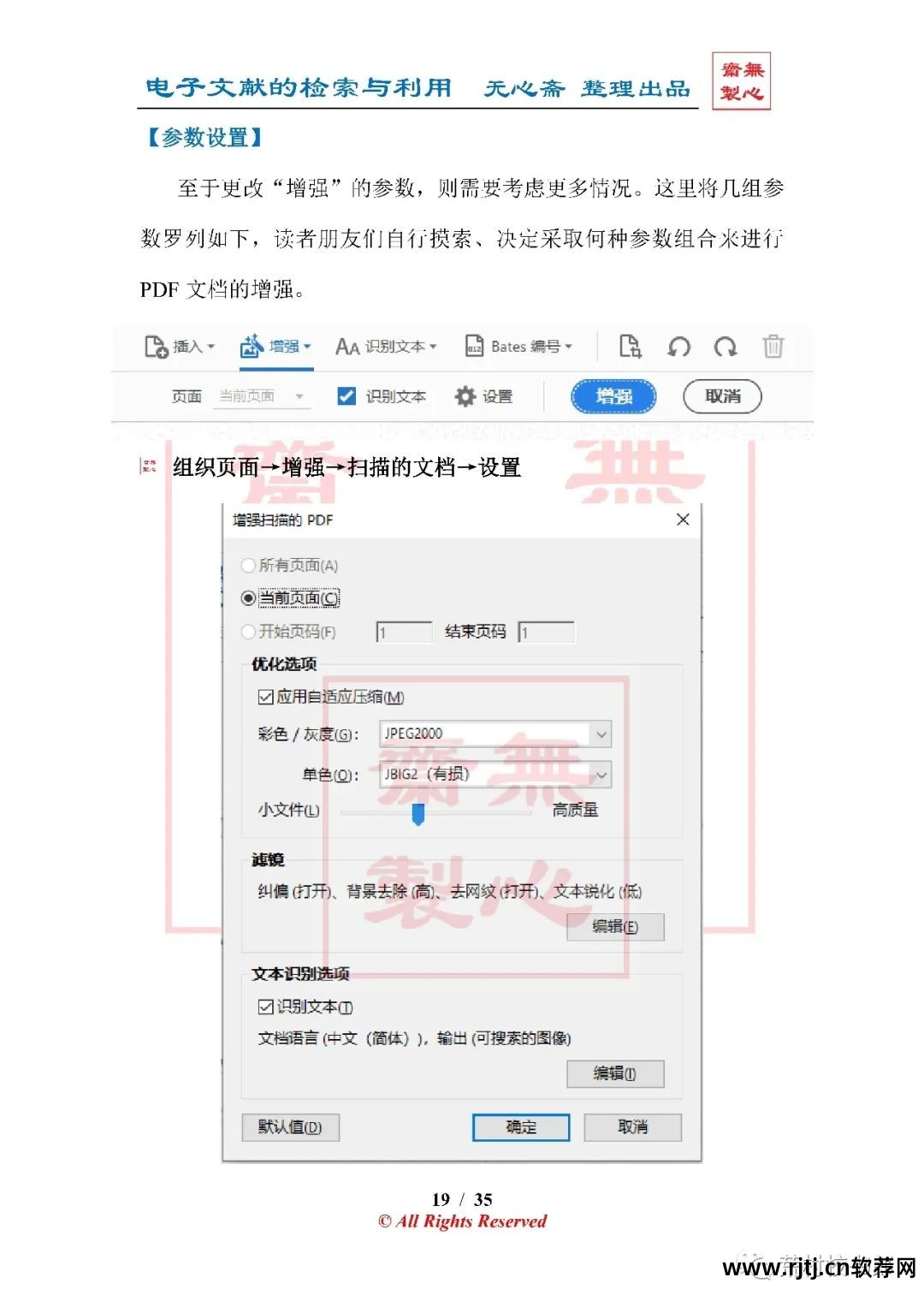
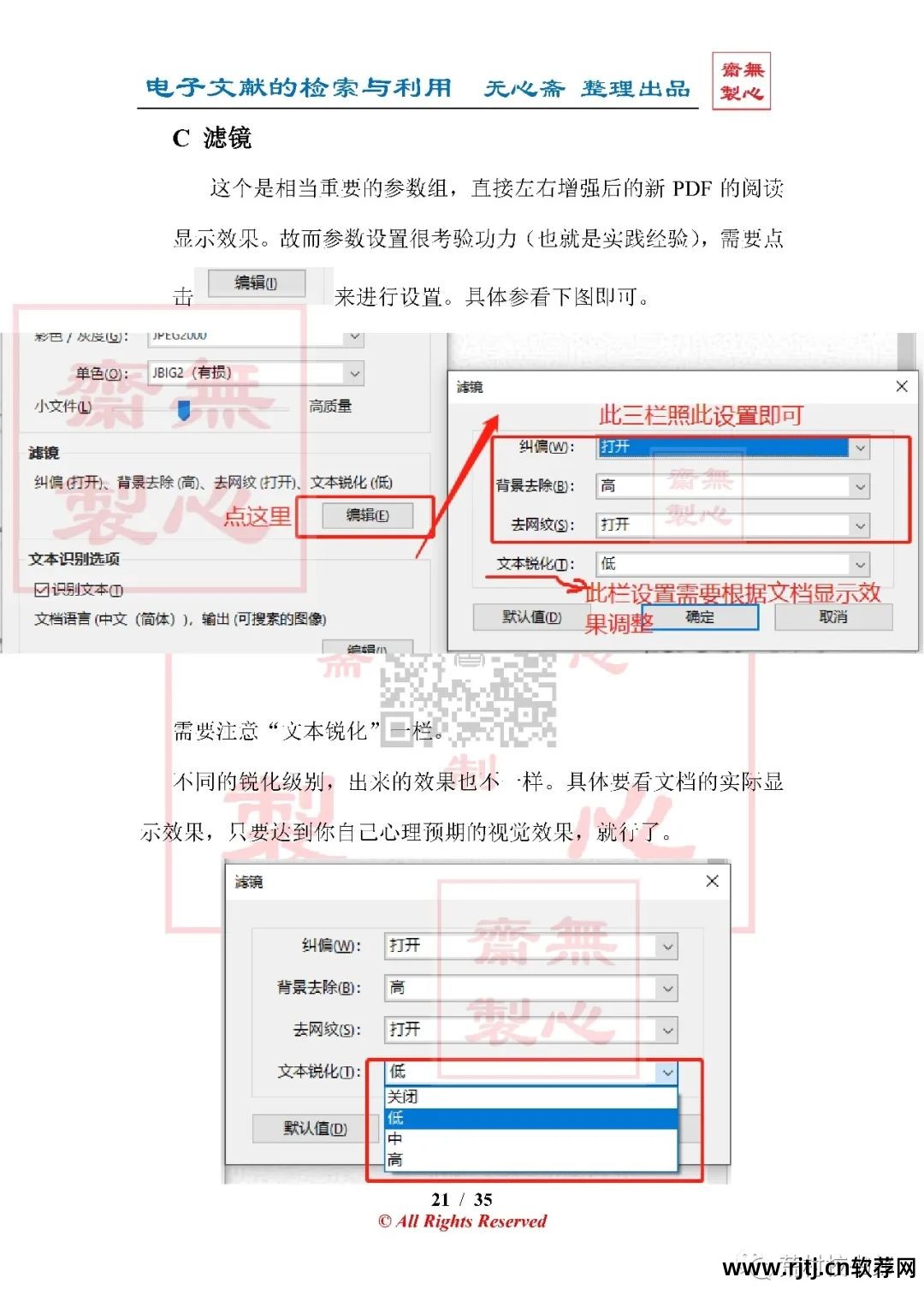
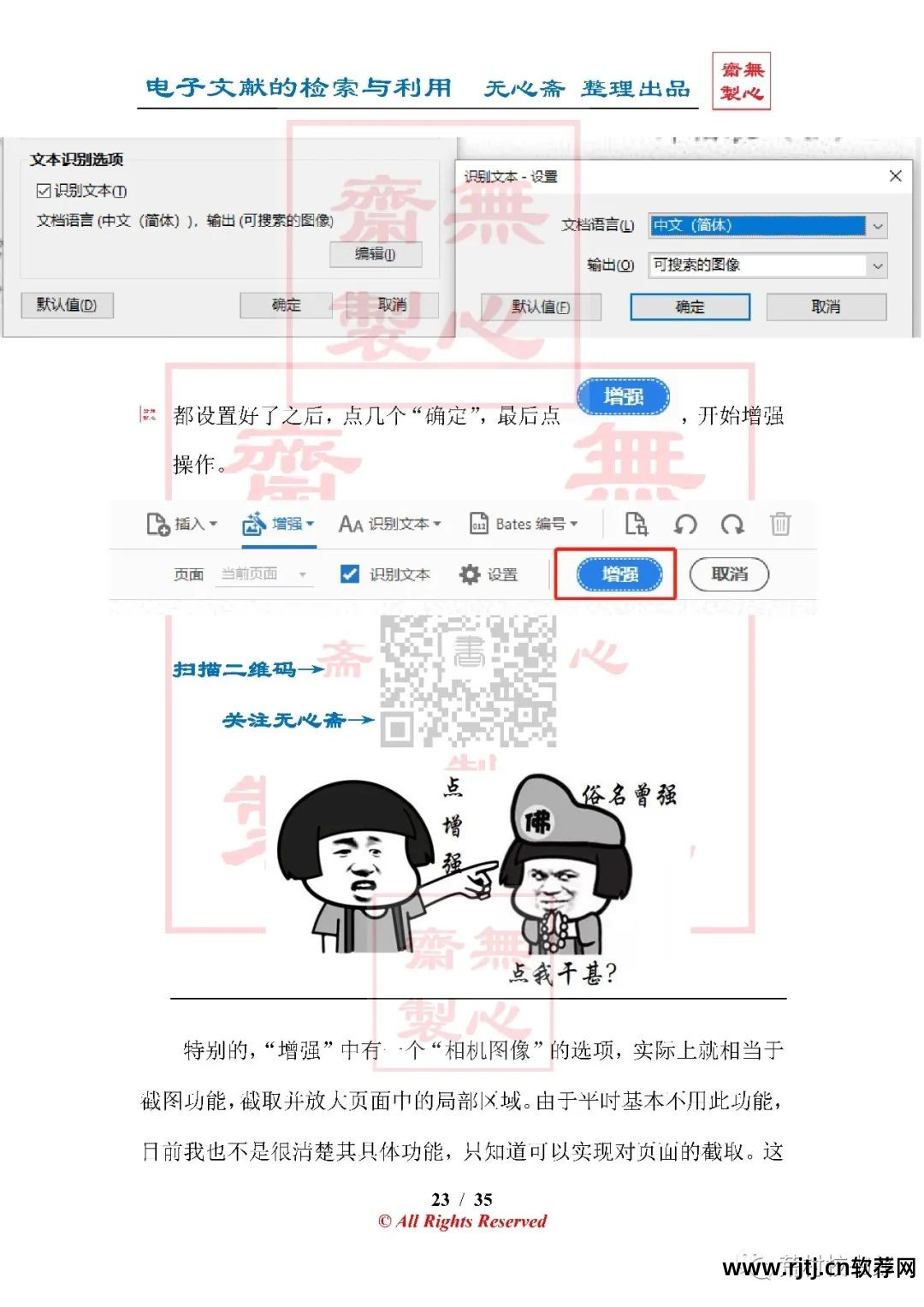
2.增强(压缩体积)
3.艾比软件
4.汉王PDF OCR软件
5.使用手机软件实现OCR
本期正文共有图片30张。
建议使用电脑阅读。
单击图像并将其放大以便更好地阅读。





















【补充】
看完上面的文章和上一期的《》,可能有人会问:文章为什么不讲OCR文字层中的文字修正呢?
我认为这个问题没有必要解释,所以我不会特别说什么。 这里就说说思路吧。
既然已经可以用我系列文章中的方法实现全文OCR,转换成Word文档,导出为纯文本,那为什么还需要直接修改PDF-ocred文本图层中的文本呢?
要知道,PDF文本图层的检索速度极其缓慢,远远不及Word的逐字检索,更不用说批量检索所有TXT文档了。 如果需要校对修改,当然优先考虑TXT和Word,而不是直接修改PDF。
——关于这个问题,其实在《电子文档检索与利用》V1.0中已经提到过,专门开辟了“校对”版块,并提供了专门的处理工具和软件。 有需要的可以自行浏览。 这里不多说。
””
最后,这是对上一期相关推文的补充一点。
百度云盘的技术非常独特。 基本上可以说,所有文档只需要在服务器上保存一份,其他所有帐户都保存其“快捷方式”。 当用户需要下载时,会直接从服务器“传送”。 ”。
同理,百度云盘的“PDF转Word”功能也是如此。 只要有人使用该功能处理过某个文档,服务器就会留下一条“记录”,任何人都会请求服务器处理该PDF文档。 对于“PDF转Word”操作,服务器会直接给出一个“快捷方式”,调用服务器的库存,发货——将快捷方式发送到账户。 这就是为什么有些文件直接“秒传”的原因。
【下一期预览】
PDF编辑和处理
(由于目前日程繁忙,发布可能会有所延迟。)
如果您觉得这个账号不错,欢迎您推荐给更多人。
他们都从事文科和研究工作。
不要隐藏它。
看这里
↓↓↓

由于本人精力和时间有限,排版和校对可能会有错误。 各位读者看到请指出,并在留言区留言,让更多人看到,以免“误导他人”。
