在日常办公或者学习中,经常会出现这样的工作场景,比如“老王,我这里有一张图片,请帮我整理一下里面的文字信息。” 已经是 2021 年了,你还真的还在用手打字。 图片文字信息? 所以赶快收藏这本秘籍吧。 这里我总结了三种方法教大家如何从图片中提取文本信息以及如何将图片转换为文本信息。

方法一:QQ/微信聊天工具
是的,你没看错,就是QQ聊天工具。 新版微信还支持从图片中提取文字信息,还支持翻译。 相信大多数人应该都用过,而且效果也很好!

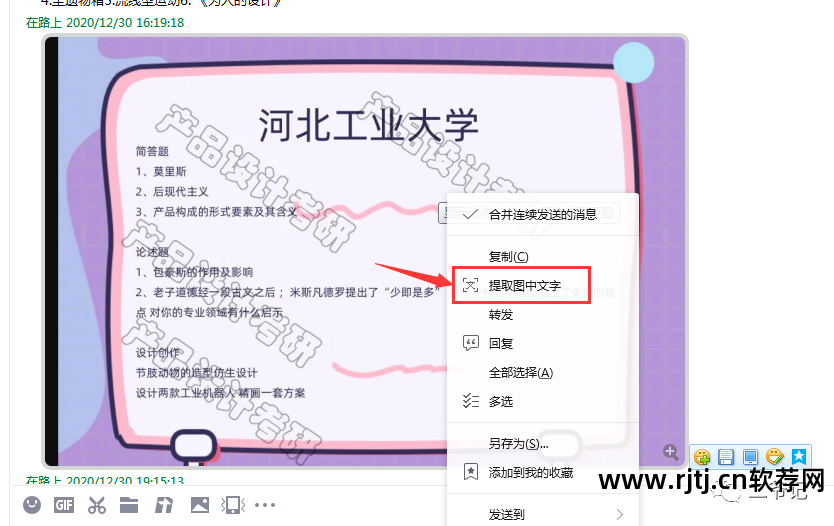
方法二:在线图文识别工具
直接在百度上搜索就可以找到很多图像和文字识别工具。 大多数应该是通过调用接口封装的Web工具。 操作比第一种复杂。 毕竟,您需要上传文件,然后下载文件。
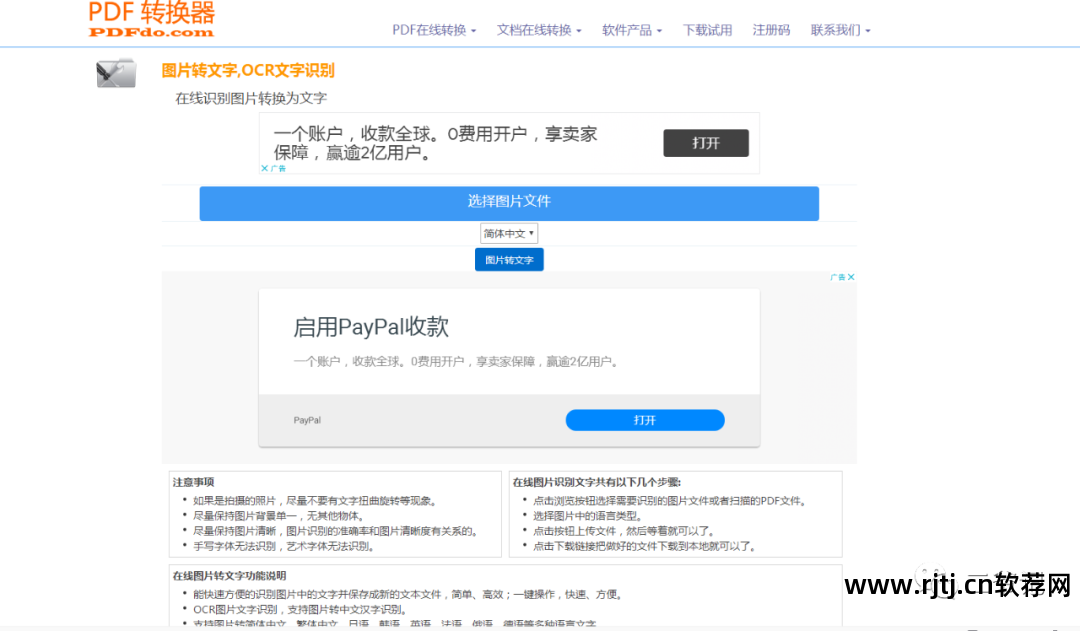
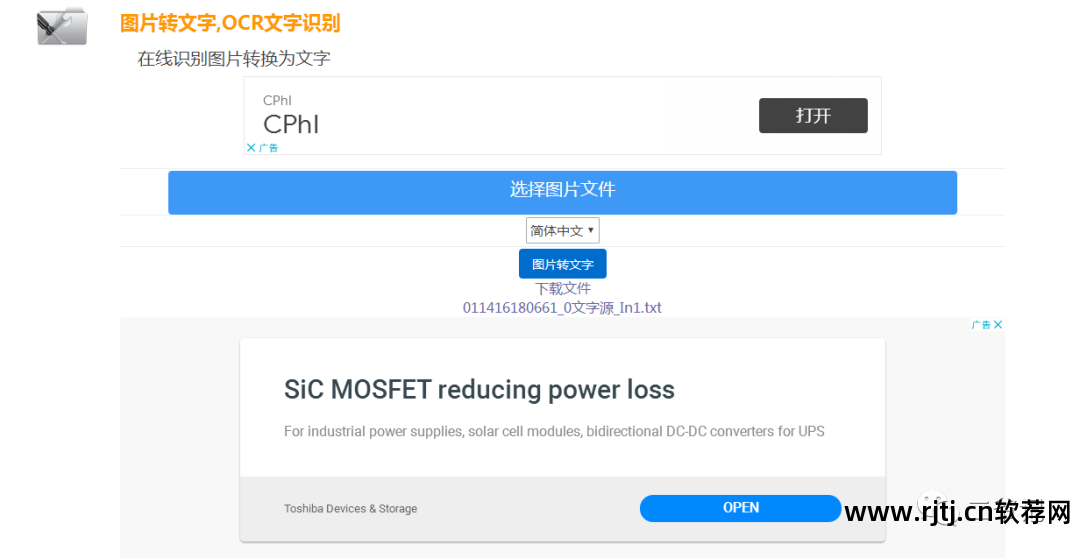
例如:
你可以尝试这个方法。 互联网上有很多这样的工具。 如果图像识别量较小,可以免费使用。 切韭菜时要小心。 当然,识别率并不是100%,大家不妨尝试一下,仅供参考!

方法三:使用Python编写图像识别文字工具(操作比较俏皮,仅用于安装)
炫酷的操作来了,我们可以用python自己写一个工具脚本,图片识别文字工具脚本,可以批量操作,解放双手。 当然,这只是为了安装。 当然,我这么渣,肯定是直接调用接口的。 !
方法一:EasyOCR库
Python中有一个不错的OCR库——EasyOCR,它在GitHub上有9700个star。 可以在python中调用它来识别图像中的文本并将其输出为文本。

EasyOCR支持80多种语言的识别,包括英语、中文(简体和繁体)、阿拉伯语、日语等,并且该库正在不断更新,未来将支持更多语言。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple easyocr
注意:EasyOCR库比较大,一定要换成国内源自动打码软件源码,不然就要等到时间结束了!
EasyOCR的使用非常简单,分为三步:
1、创建识别对象; 2. 阅读并识别图像; 3.导出文本。
参考源码:
# 导入easyocr
import easyocr
# 创建reader对象
reader = easyocr.Reader(['ch_sim','en'])
# 读取图像
result = reader.readtext('test.jpg')
# 结果
print(result)
遗憾的是,调试并没有成功。 我还不知道问题所在。 我将问题发布出来,有知道的人可以给我一些建议!
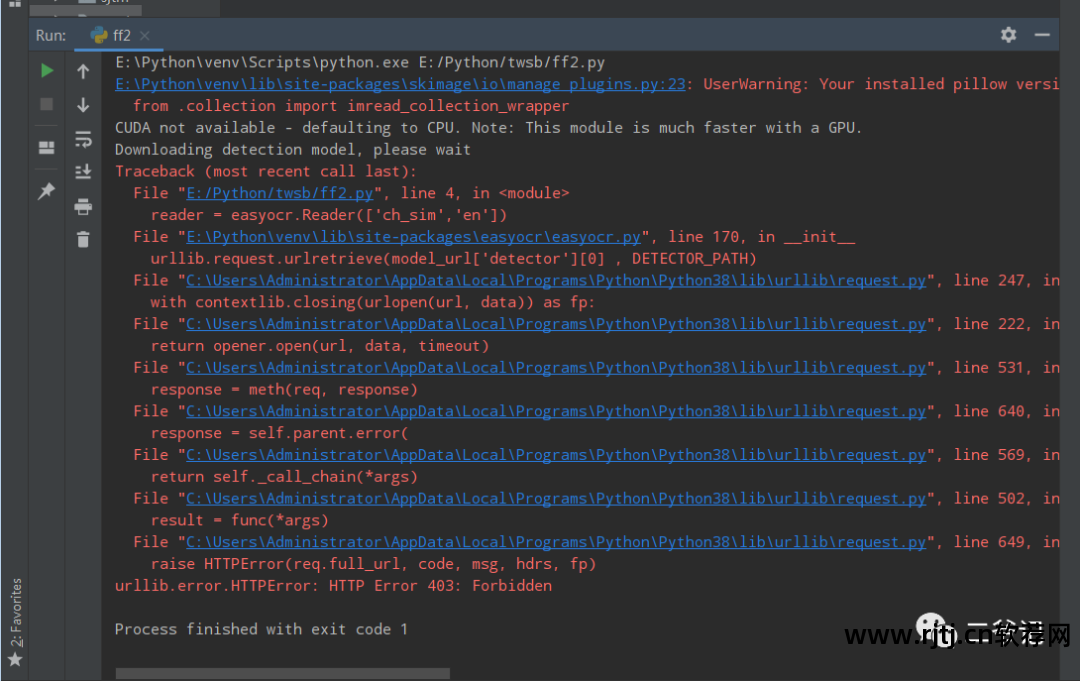
错误信息:
E:\Python\venv\scripts\python.exe E:/Python/twsb/ff2.py
E:\Python\venv\lib\site-packages\skimage\io\manage_plugins.py:23: UserWarning: Your installed pillow version is < 7.1.0. Several security issues (CVE-2020-11538, CVE-2020-10379, CVE-2020-10994, CVE-2020-10177) have been fixed in pillow 7.1.0 or higher. We recommend to upgrade this library.
from .collection import imread_collection_wrapper
CUDA not available - defaulting to CPU. Note: This module is much faster with a GPU.
Downloading detection model, please wait
Traceback (most recent call last):
File "E:/Python/twsb/ff2.py", line 4, in
reader = easyocr.Reader(['ch_sim','en'])
File "E:\Python\venv\lib\site-packages\easyocr\easyocr.py", line 170, in __init__
urllib.request.urlretrieve(model_url['detector'][0] , DETECTOR_PATH)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 247, in urlretrieve
with contextlib.closing(urlopen(url, data)) as fp:
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 531, in open
response = meth(req, response)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 640, in http_response
response = self.parent.error(
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 569, in error
return self._call_chain(*args)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 502, in _call_chain
result = func(*args)
File "C:\Users\Administrator\AppData\Local\Programs\Python\Python38\lib\urllib\request.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 403: Forbidden
Process finished with exit code 1
方法二:ORC(tesseract-ocr)识别
安装pytesseract库首先要安装它所依赖的PIL和tesseract-ocr。 PIL是图像处理库,后续的tesseract-ocr是Google的OCR识别引擎。
安装 tesseract-ocr。 对此,没什么好说的。 下载程序,单击“下一步”并按照安装步骤进行安装!

不过需要配置系统环境变量自动打码软件源码,或者调用程序时需要指明该工具的路径,即安装后tesseract.exe的路径!
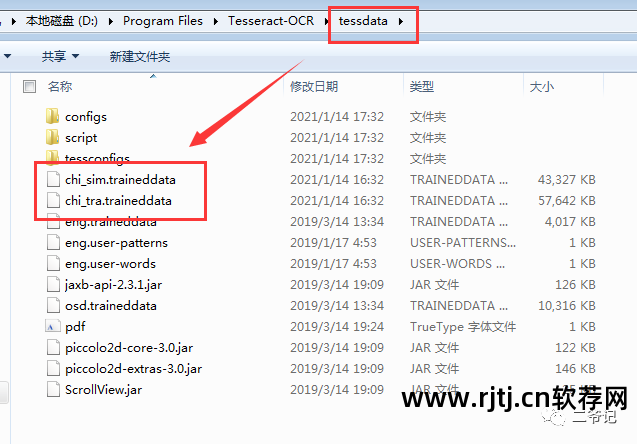
关于配置系统环境变量,可以自行百度配置。 这里没有配置。 可以直接指明应用路径地址:
pytesseract.pytesseract.tesseract_cmd = r'D:/Program Files/Tesseract-OCR/tesseract.exe'
注意:
下载 chi_sim.traindata 字体。 这是识别中文所必需的。
下载后放置在Tesseract-OCR项目的tessdata文件夹中。
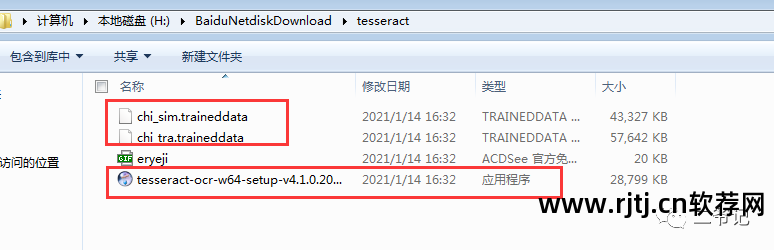
为了方便大家测试和使用,我这里封装了一个工具包!
