”
本文记录了作者使用Python爬取淘宝商品,挖掘分析商品数据,最后得出结论的整个过程。

项目介绍
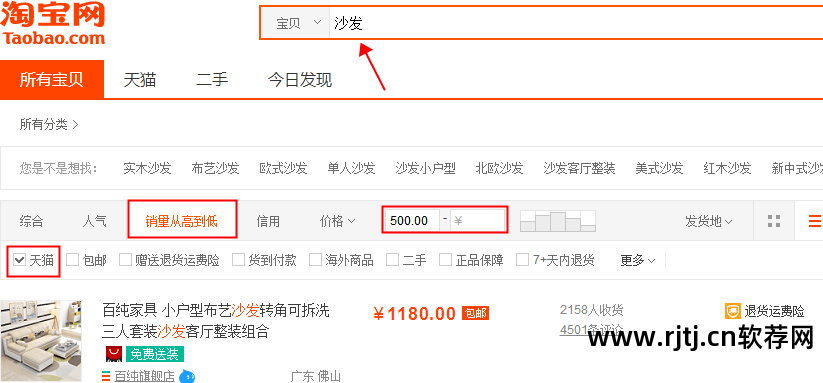
项目目的
注:本项目仅以上述分析为例。
项目步骤
工具和模块
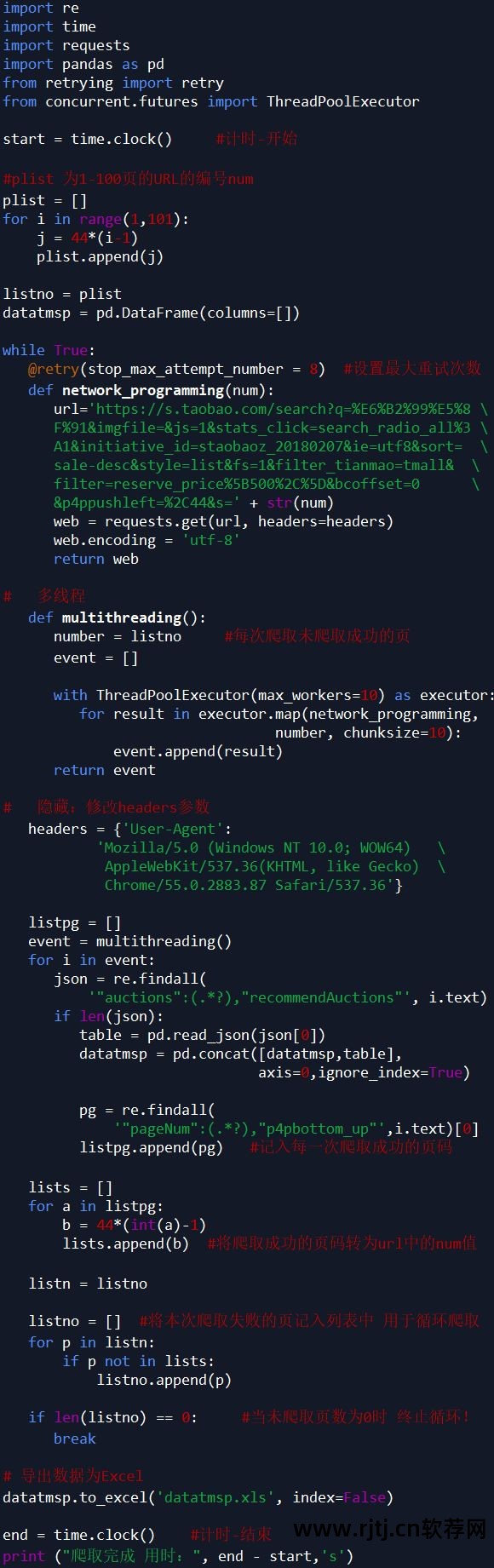
抓取数据
因为淘宝是反爬虫,虽然使用了多线程,修改了headers参数,但还是不能保证每次100%爬取,所以我加了一个循环爬取,每次循环爬取没有爬取成功的页面,直到所有Page抓取已成功停止。
注:淘宝商品页面为JSON格式,这里使用正则表达式进行解析。
代码如下所示:
数据清洗与处理
数据清洗和处理的步骤也可以在Excel中完成,然后读入数据。
代码如下所示:
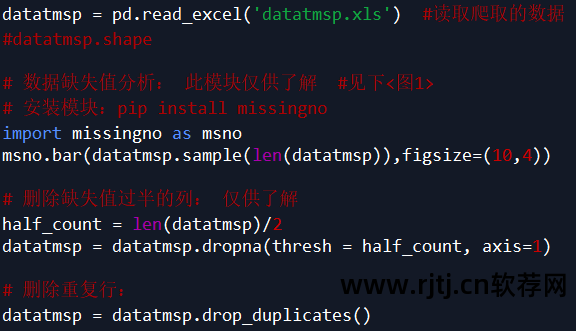
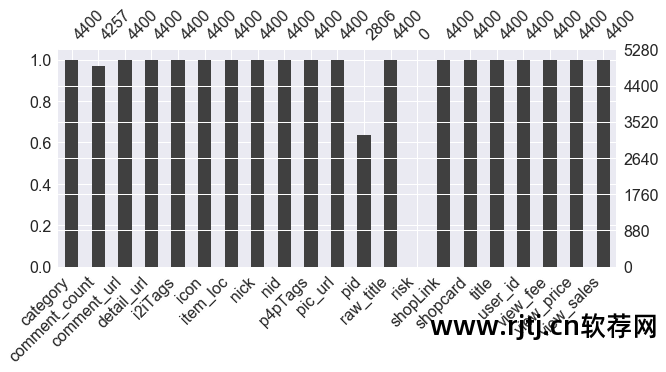
注:根据需求,本案例只取item_loc、raw_title、view_price、view_sales四列数据淘宝关键词挖掘软件,主要分析地区、标题、价格、销量。
代码如下所示:
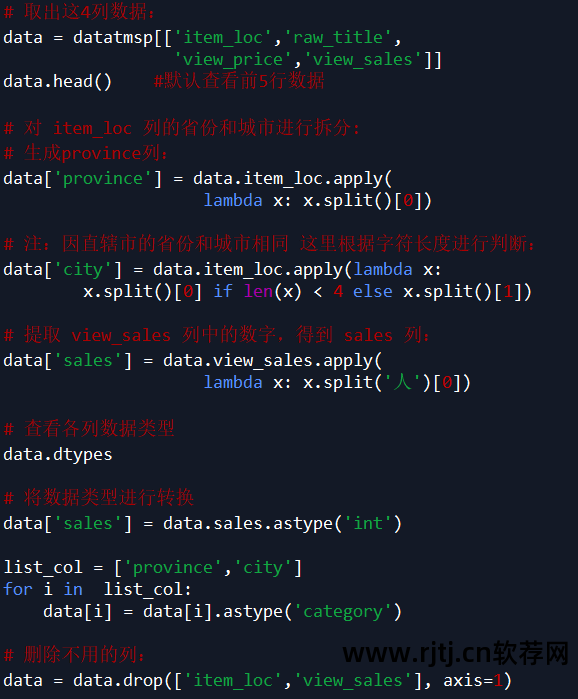
数据挖掘与分析
raw_title列标题的文本分析
使用口吃分词器,安装模块 pip install jieba:

过滤title_s(列表格式的列表)中的每个列表元素(str),删除不必要的单词,即删除停用词列表中的所有单词:
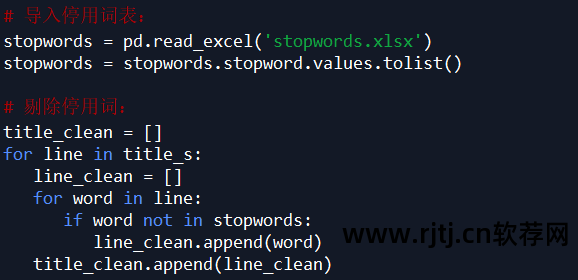
因为下面会统计每个单词的个数,所以为了准确起见,对过滤后的数据title_clean中每个列表的元素进行了去重,即每个标题划分后的单词是唯一的。
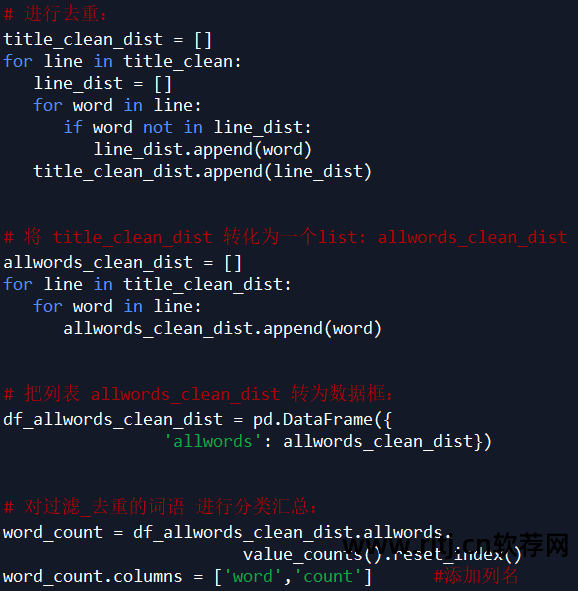
观察word_count表中的单词,发现jieba默认的词典无法满足需求。
有些词(如可移动、不可移动等)被剪掉。 这里,根据需要将新单词添加到词典中(也可以直接在词典dict.txt中添加或删除,然后加载修改后的dict.txt)。
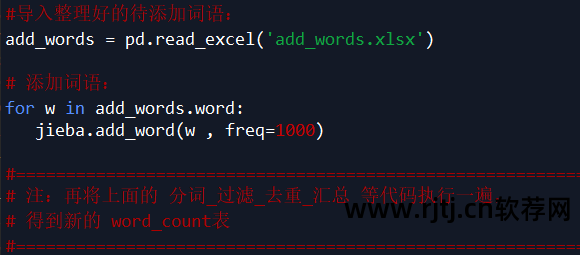
词云可视化需要安装wordcloud模块。
安装模块有两种方法:
软件包下载地址:~gohlke/pythonlibs/#wordcloud
注意:下载的软件包必须放在Python安装路径下。
代码如下所示:
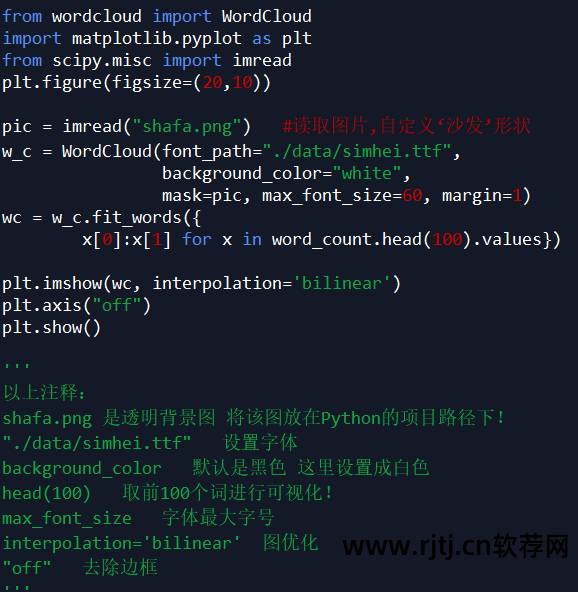

分析结论:
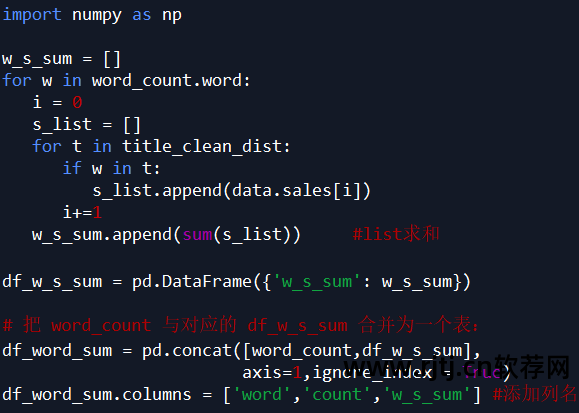
不同关键词对应的销售额总和统计分析
注:以“简单”一词为例,计算产品标题中含有“简单”一词的产品销售额总和,即计算风格为“简单”的产品销售额总和。
代码如下所示:
可视化表 df_word_sum 中 word 和 w_s_sum 列中的数据。 (本例以销售量最高的30个词进行绘制)
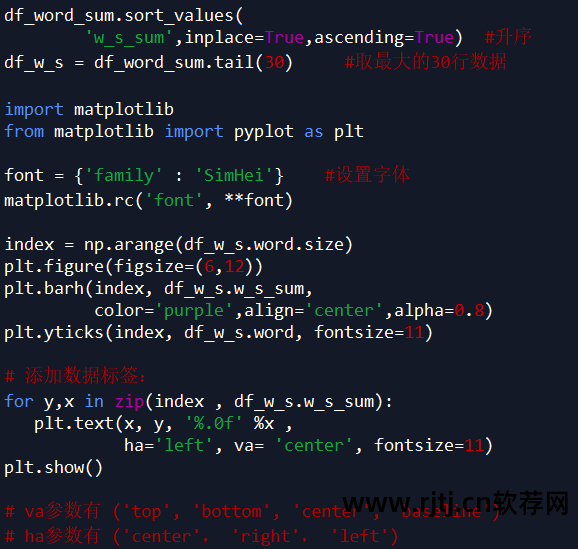
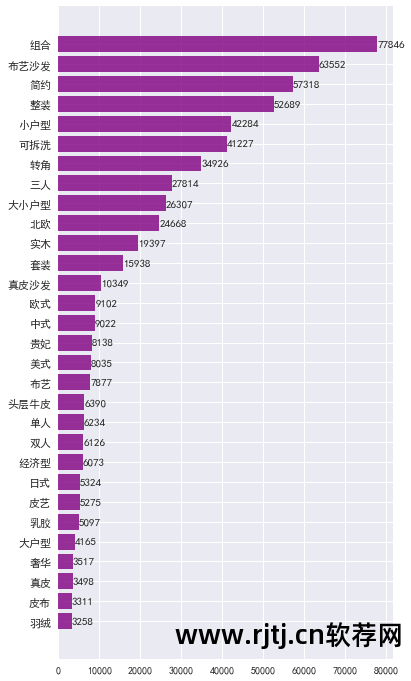
从图表中可以看出:
商品价格分布分析
分析发现有些值太大。 为了让可视化效果更加直观,这里我们结合自己的产品情况,选择了价格在2万以内的产品。
代码如下所示:

从图表中可以看出:
产品销售分布分析
同样,为了可视化更加直观,这里我们选择销量大于100的产品。
代码如下所示:
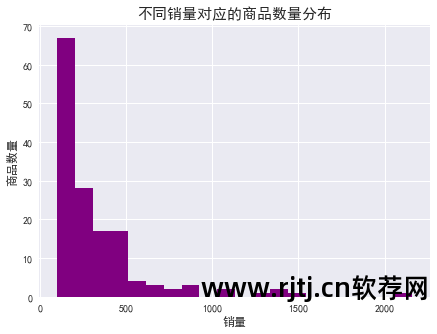
从图表和数据可以看出:
不同价格段产品平均销量分布
代码如下所示:
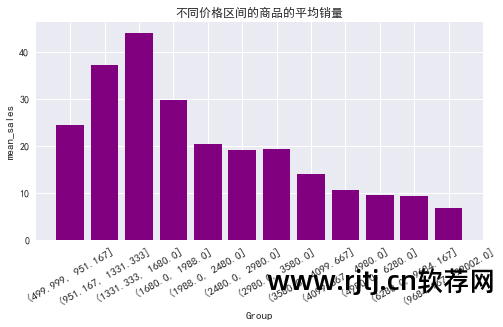
从图表中可以看出:
商品价格对销售的影响分析
同上淘宝关键词挖掘软件,为了让可视化效果更加直观,这里我们结合自己的产品情况,选择价格在2万以内的产品。
代码如下所示:

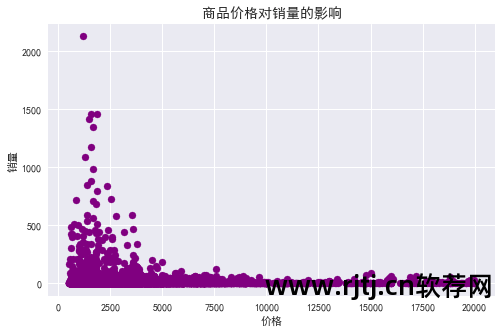
从图表中可以看出:
商品价格对销售的影响分析
代码如下所示:
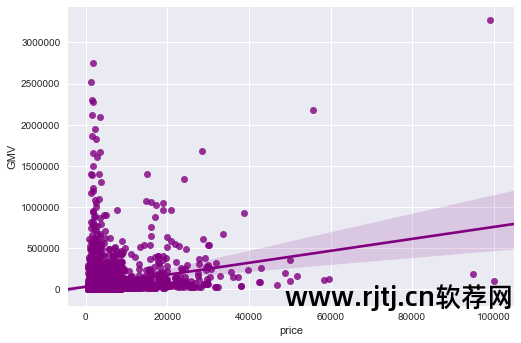
从图表中可以看出:
各省商品数量分布
代码如下所示:
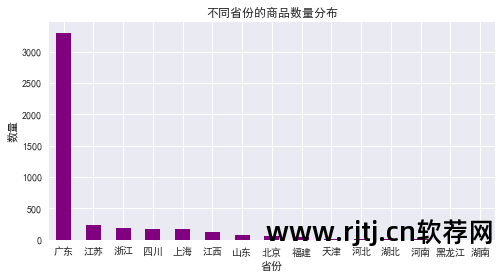
从图表中可以看出:
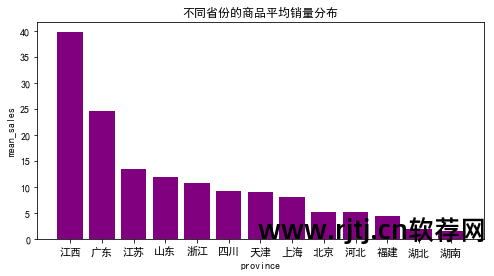
各省份商品平均销售分布
代码如下所示:

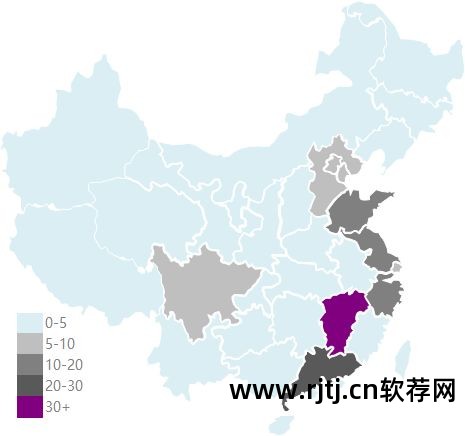
热图
微信后台回复关键词“淘宝”下载源码及相关文档
作者:孙芳辉,从事数据分析,热爱数据统计和挖掘分析
