介绍
海量数据分析不一定需要使用elasticsearch,但搜索一定要用elasticsearch。 Elasticsearch 基于文档数据结构。
百度是全文搜索引擎,搜索内容不固定; 京东、淘宝是垂直搜索,搜索目的明确,站内搜索是垂直领域的一种。
搜索引擎包括NLP(自然语言分析与处理)、大数据处理、网页处理、爬虫、算法、elasticsearch等。
除了搜索之外,elasticsearch还可以做大数据分析。 ELK是使用的elasticsearch大数据分析功能。
搜索框架技术选型
Redis不适合大数据的搜索和存储。 它是一个内存数据库。 如果启用持久性,性能将会下降。
Mongodb适合大数据存储,可以作为搜索引擎,但更适合数据管理,不适合检索。
es更倾向于搜索。 数据写入的实时性不高。 es不支持事务。 es和mongodb都是基于文档数据库。
搜了一下这方面,能和es相提并论的是solr,两者都是基于lucene的。 Lucene 是单点的。 Solr是一个技术比较老的框架。 es的稳定性不会随着数据量的增加而发生明显变化。 es 本质上支持分布式分发。 Solr 则不同。 它本身并不支持分布式。 需要自己管理分布式集群,使用第三方中间件zookeeper管理集群状态。 es还支持数据迁移,比如从solr迁移到es。
为什么mysql索引结构不适合搜索引擎?
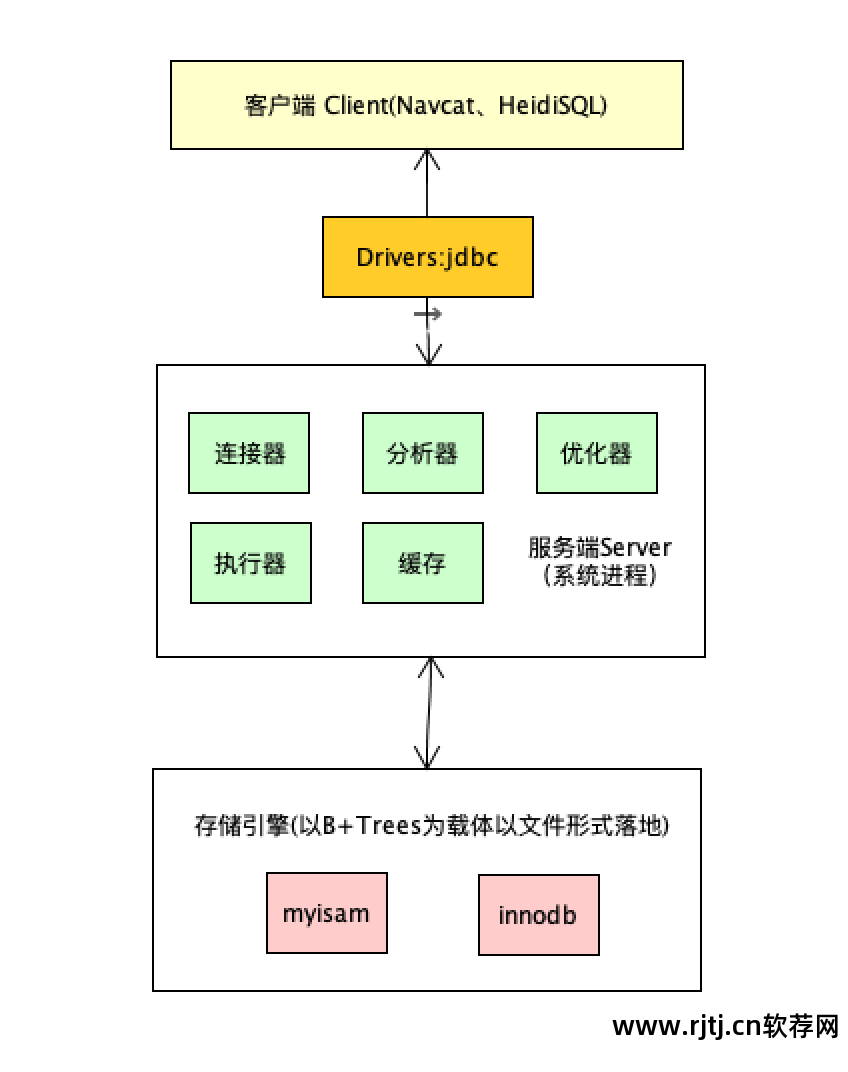
数据库结构
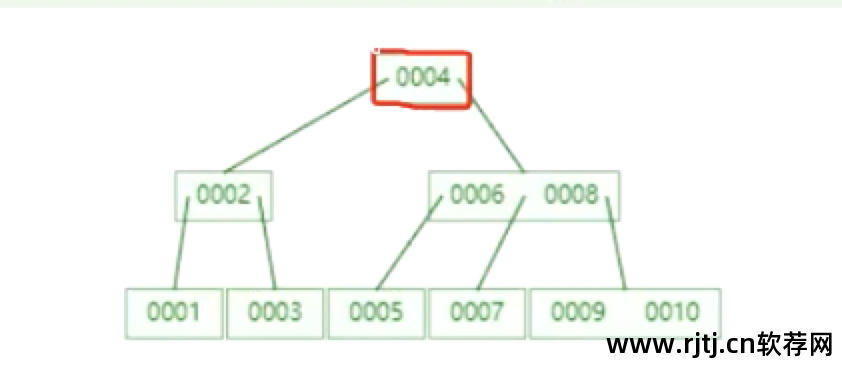
图1
在mysql中,这样的节点的大小是固定的。 节点是要寻址的最小数据单元,也就是数据页。 默认大小为 16KB。
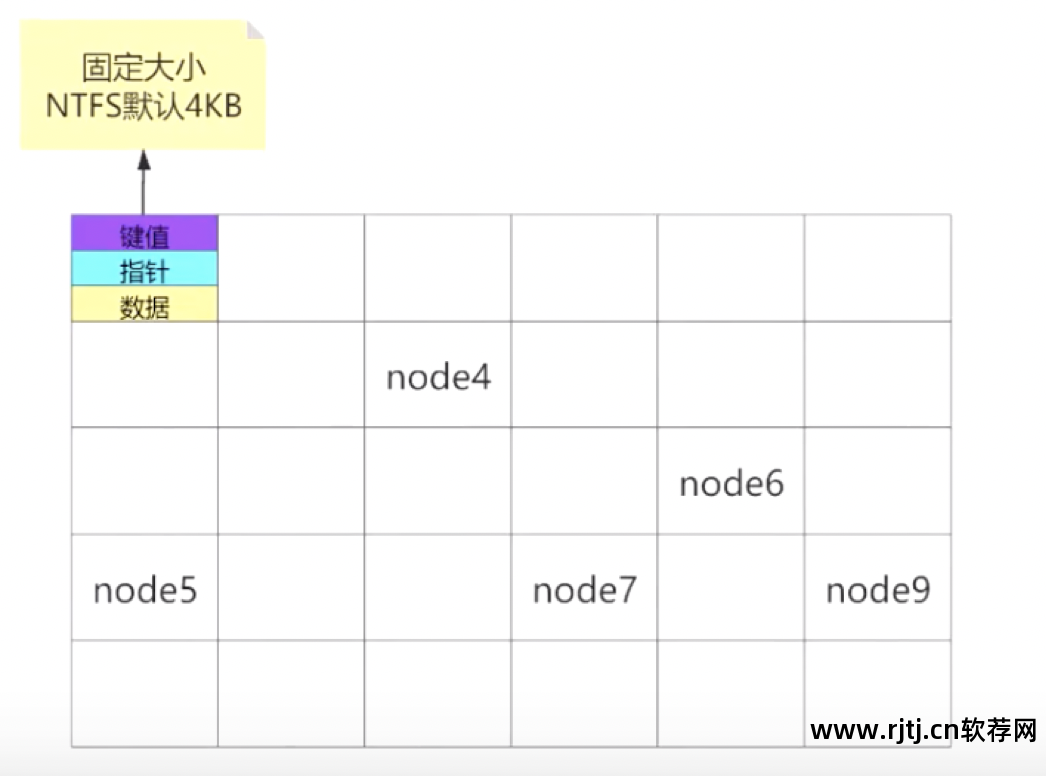
假设这是一个磁盘。 磁盘由许多节点数据单元组成。 每个节点包含键值、指针和数据。
当磁盘和内存之间交换数据时,一次至少取出这样一个数据单元。
需要多少次IO操作才能找到图[1]中id=7的数据?
首先将后面的节点的16KB放入内存(创建索引树时根节点会放入内存,这里忽略这一点)。 一次IO后,CPU判断id=7的数据不在本节点中。 根据当前磁盘中的节点004寻址,找到节点006~008,然后从磁盘加载到内存中。 这是第二次IO操作。 CPU判断数据在007节点上,然后查找007节点并加载数据。 到内存中,然后读取里面的数据。 这是第三次IO操作。 在这个过程中,内存和磁盘之间总共有3次交互。 计算结果为16KB*3=48KB。
一旦用户数量过多,任何小数据都不能被忽略,因此应尽可能减少磁盘IO次数。
随着树的深度不断增加,意味着磁盘IO数量不断增加。
B树
非叶节点包含键值、指针和数据。 单个节点的大小是固定的,这意味着单条数据量越大,单个节点所能容纳的数据量就越小,所需的节点数量也就越多。 Max Degree确定,即每个节点的子节点数。 是固定的,所以树越深,搜索路径越长,搜索效率越低。

类比电梯,人越重,电梯里的人就越少,所以需要更多的电梯。
所以尽量避免单个节点的数据太大。 节点包含键、指针和数据。 指针就是索引,单个索引的长度越小越好。

键值是第一列中的id数据。 除了第一列之外,其余都是数据。
如果节点中不存在数据,即节点只包含键值和指针,那么节点中存储的数据数量会增加,所需的节点数量会更小,树的深度也会增加会更小。
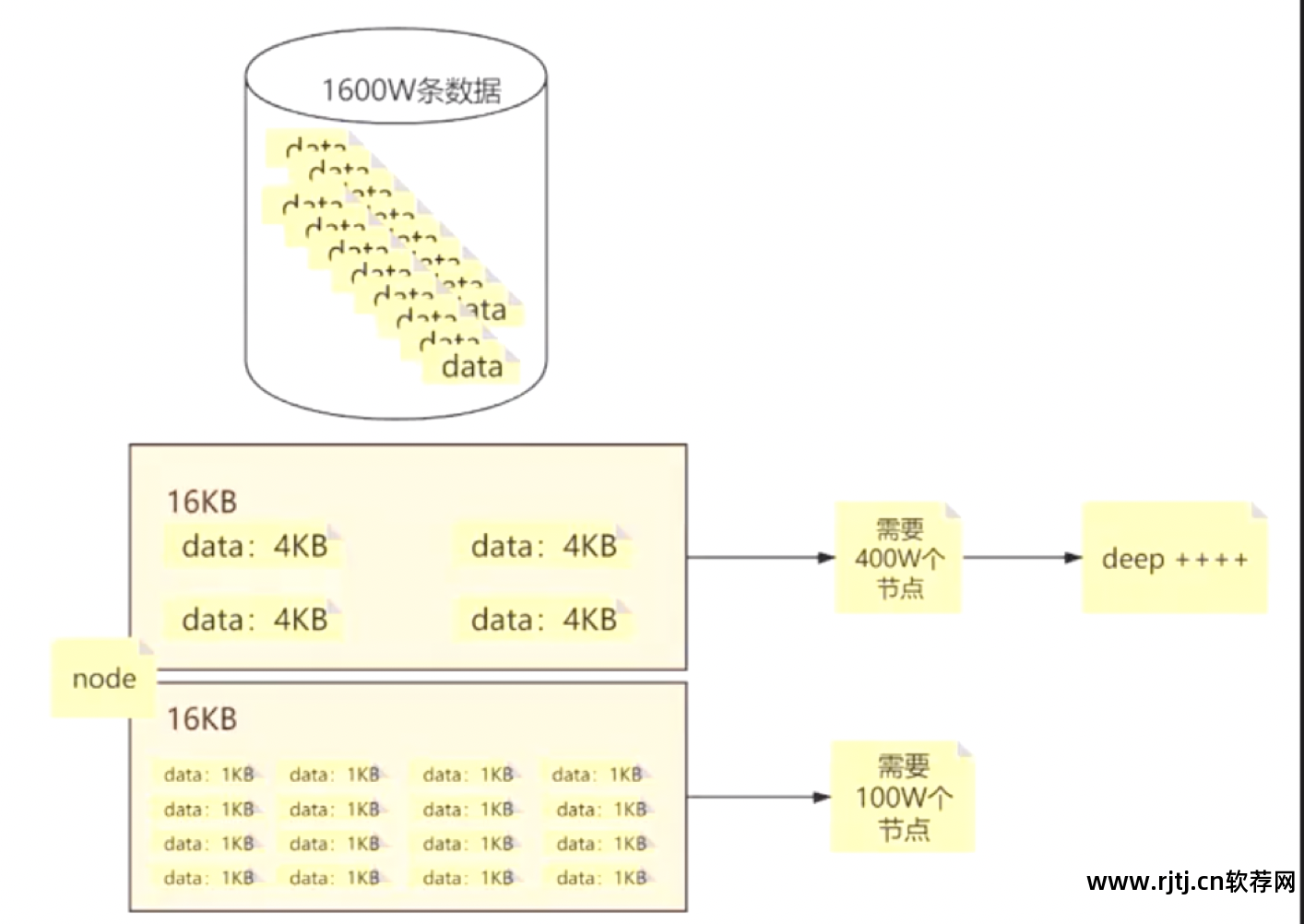
1个节点空间16KB,1条数据4KB,可存储4条数据。 1600万条数据需要400万个节点,树越深; 如果一条数据是1KB,那么一个节点可以存储16条数据,也就是1600万条数据。 需要100万个节点,树的深度变浅。
B+树
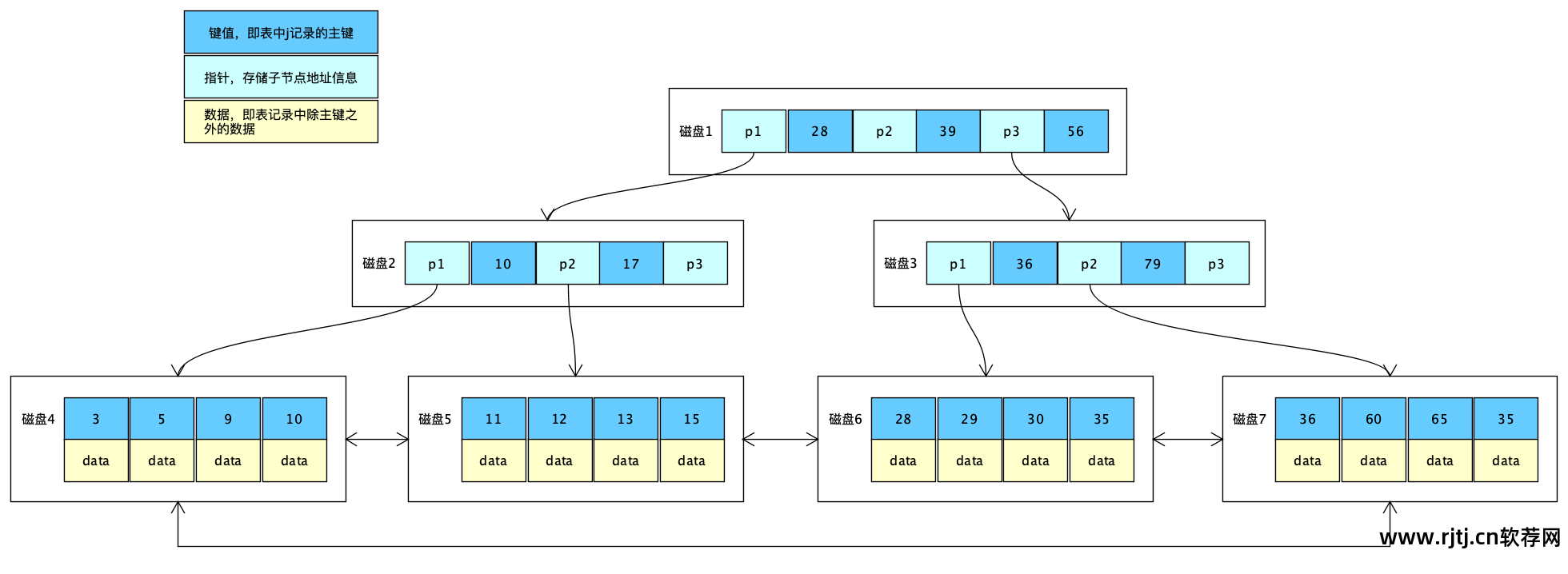
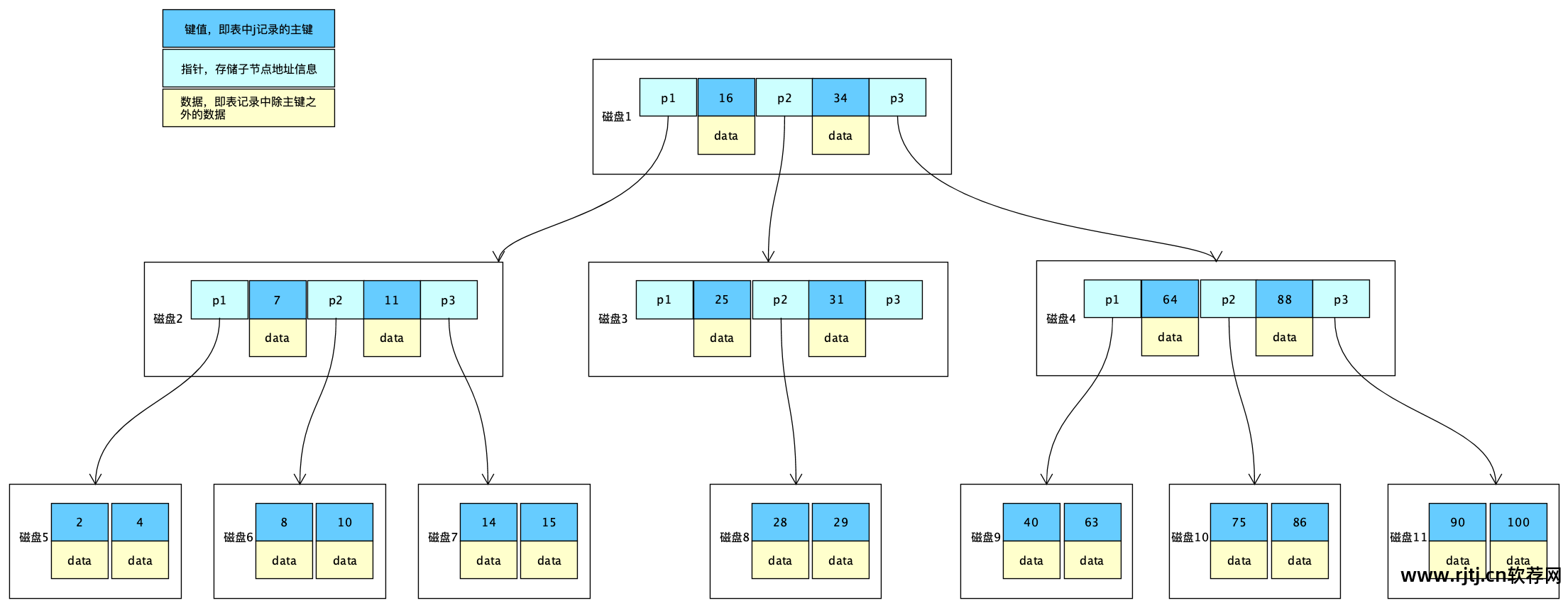
与B-Trees相比,B+Trees去掉了非叶子节点的数据部分,只留下键值和指针。 这样做的好处是每个非叶子节点可以存储更多的数据,从而减少树的深度,提高检索效率。 数据放置在叶节点中。
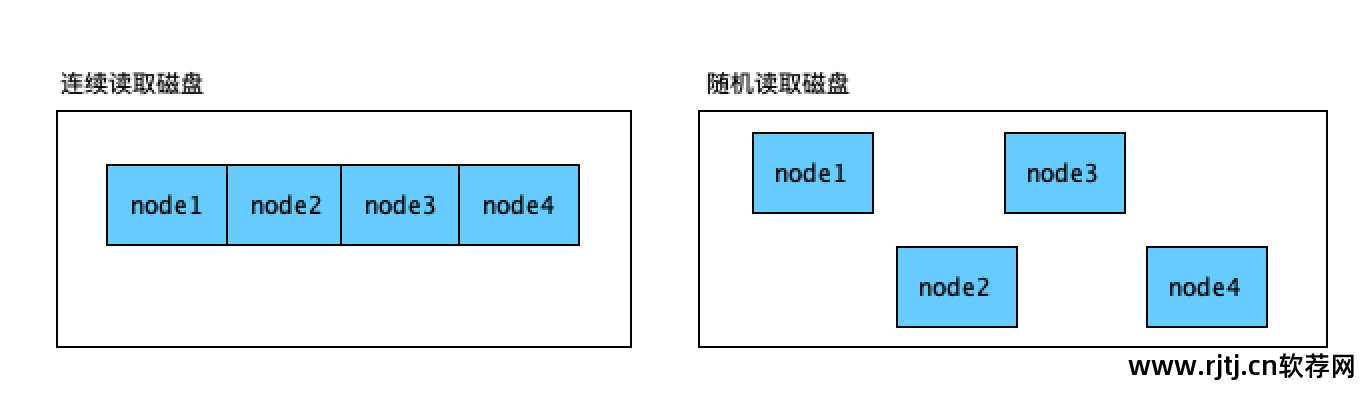
如果将磁盘数据复制到U盘中,如果复制的是源代码,比如数千个文件,传输速度只有几KB每秒。 超过100M的原始大小需要10分钟或更长时间。 如果只是一个zip压缩包,速度会很快,因为zip包是一个文件,一个文件在磁盘上占用的空间是连续的。 多个文件在磁盘上的位置是随机分布的,复制过程中会不断产生IO。 如果是连续数据,可以从起始位置读取到结束位置。 连续读取比随机读取快得多。
当检索大数据文本时,B+Tree的性能会直线下降。
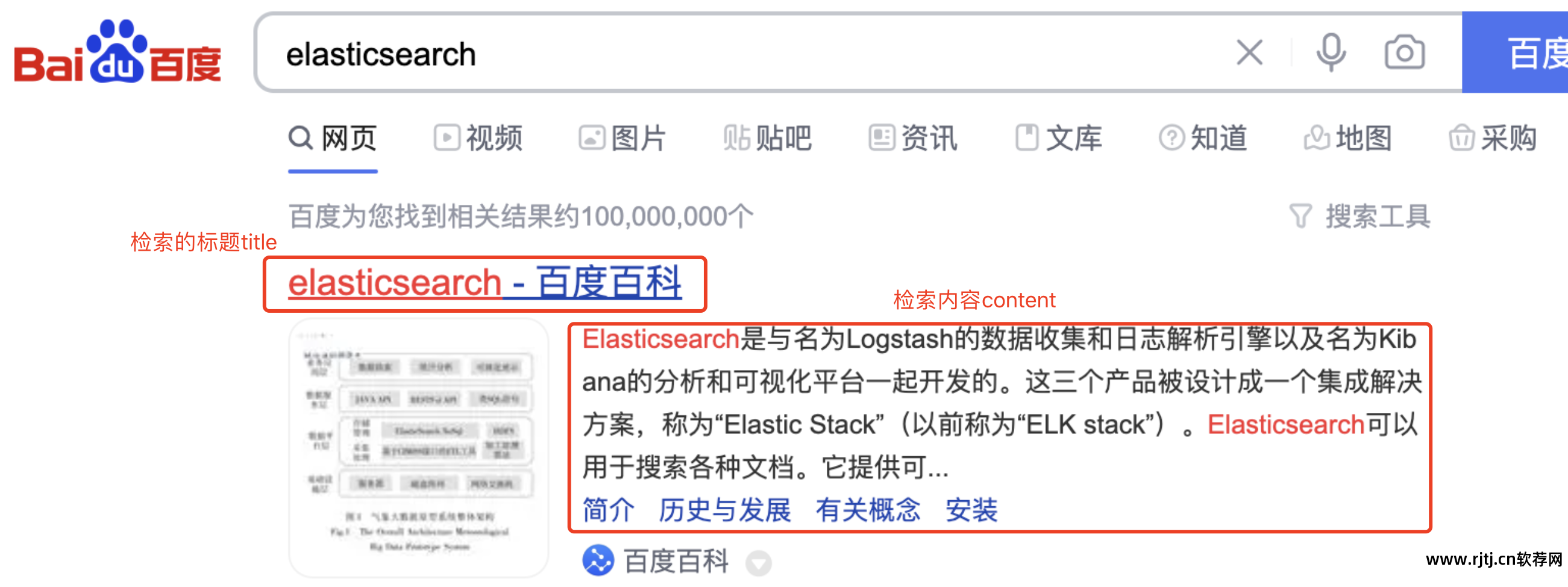
您正在搜索的段落可能是一个长文本字段,您需要在标题和内容字段上创建索引。 因为B+Tree的要求是单个索引的长度要尽可能小,所以这种场景下没办法使用B+Tree,因为当要索引的字段都是文本字段时,一个索引可能占用很多节点,会导致树的深度无限,iO数量无限,性能极差。 索引可能会失效。 准确度也较差。 因此,MySQL索引无法解决大数据检索的问题。
全文搜索
索引系统扫描文章中的每个单词,为其创建索引,并指示文章中出现的次数和位置。 当用户查询时,索引系统根据预先创建的索引进行搜索,并将搜索结果反馈给用户的搜索方法。
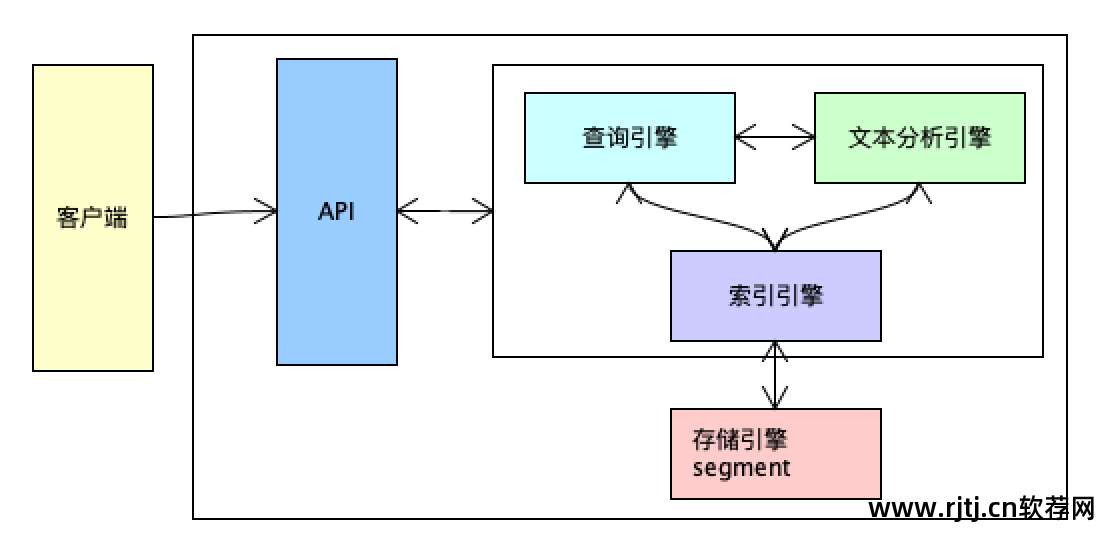
倒排索引原理
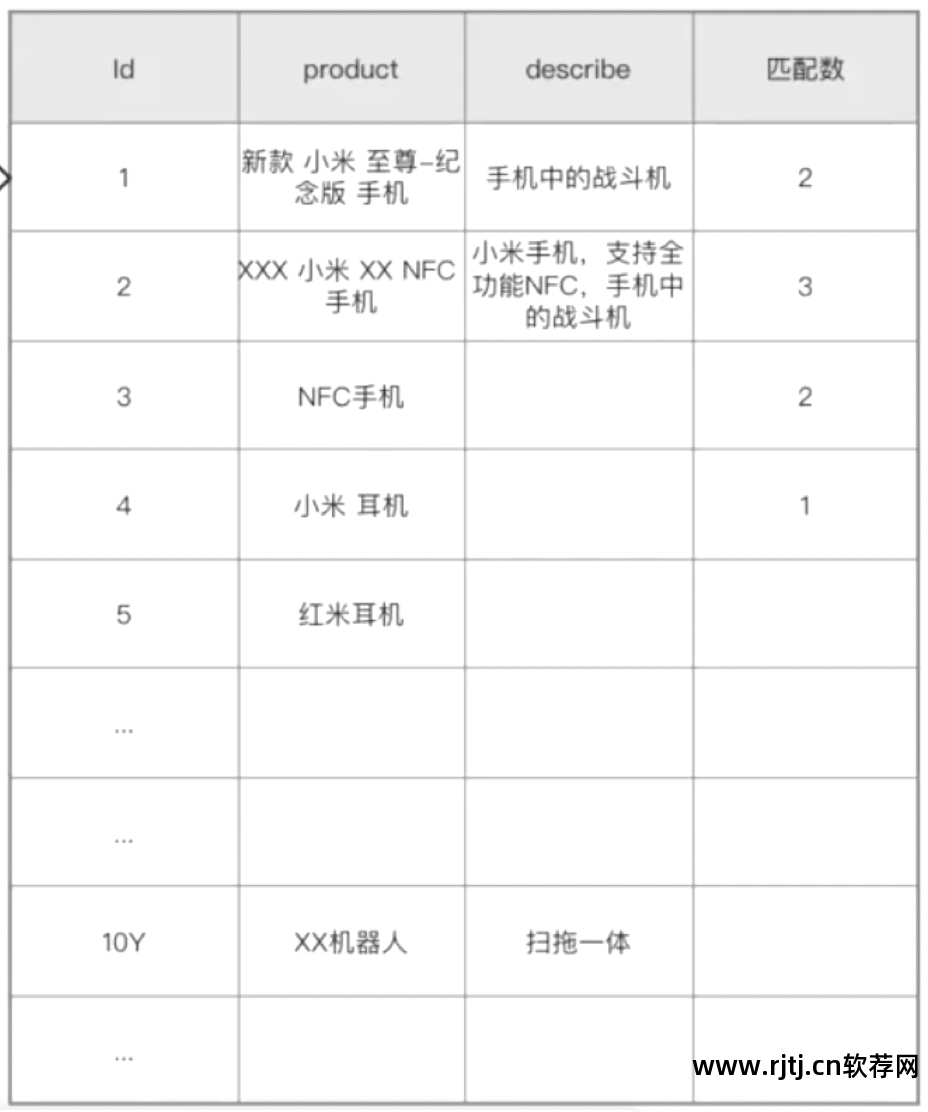
假设这是一个数据量为10亿的表(在实际开发过程中,10亿数据不会以数据表的形式存储,这只是为了说明原理)。

执行此模糊查询来检索产品字段将导致全表扫描。
这种查询的缺点:索引效率慢,准确性差(上面的查询语句中,无法查询到id=2的数据)
创建倒排索引数据表
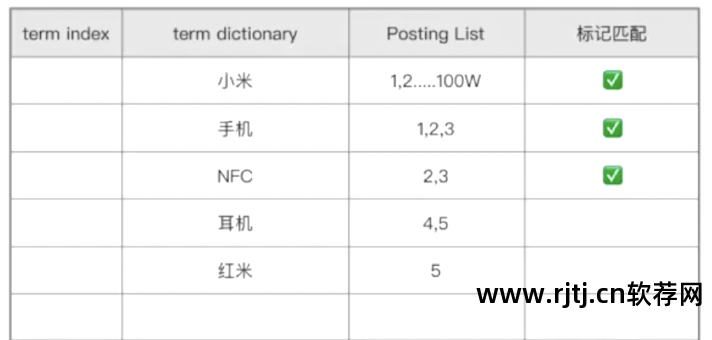
术语词典:术语词典,存储索引字段积分词、归一化、去重、字典序后的术语。
发布列表:存储当前term所在数据的ID集。 ID 从小到大排序。
查询需求为“小米NFC手机”。 分词后得到的第一个词是小米。 在术语词典中搜索。 第一条数据打到小米,获取小米所在数据的ID集。 然后,获取相应的原始数据。 里面有10亿条数据。 我只查了一遍,就找出了这10亿条数据中哪些数据包含了这个词。 命中索引后,做一个标记,将其标记为命中。 这就是倒排索引。 目前分别检索三个术语的过程是全文检索。 百度是一个全文搜索引擎。
倒排索引中的三种数据结构
倒排列表包含当前term的每个数据的id。 这是一个int类型的数组。 不管id本来是什么类型,这里都是int类型。
术语词典存储创建索引词典的每个术语。
这是一个抽象的数据结构。 为了加快当前术语的检索速度,使用了底层 FST 数据结构。
如果将每条数据拆分为多个term,则每个term就是索引中的一条新数据。 如果一条数据被拆分为5个索引数据行,10亿条数据,那么索引行数甚至可能大于原始数据的行数,如果索引被检索了10亿次还没有被发现了树叶快照软件,所以检索本身也是一个问题。
如果包含小米这个词的数据有100万条数据,一个索引项有100万条数据,那么如何存储Post List数据本身就是一个问题。
帖子列表是一个 int 数组。 一个int是4个字节,也就是32位。 如果有100万个ID,就是100万*4B=400万字节。 即一个索引带来的存储成本约等于3.8M。10亿数据就是10亿*3.8,那么如何解决这个存储问题呢?
如何节省存储空间并提高检索性能?
访问量大的使用SSD,可读写; 访问量较小的使用HDD机械硬盘,只读; 访问量较低的使用COLD冻结索引并以快照的形式存储。 es 7.x版本支持可搜索快照。
当然这并不能解决主要问题。
在软件层面要节省存储空间,需要考虑的是如何解决压缩数据的问题。
一个int类型占用4个字节,即32位,一位由8个01组成。
一个字节有 8 位。 如果要存储一个0,则表示8个0; 当你存储1时,表示00000001; 当您存储 2 时,表示 00000010(执行一位数字)。
一位可以存储的数据是2的8次方-1。这就是为什么int类型的范围是2的31次方-1。为什么是31,因为有一个位用来存储+-符号。
如果有100万个ID,则为100万*4B=400万字节,即一个索引的存储成本约等于3.8M。
FOR 压缩参考系
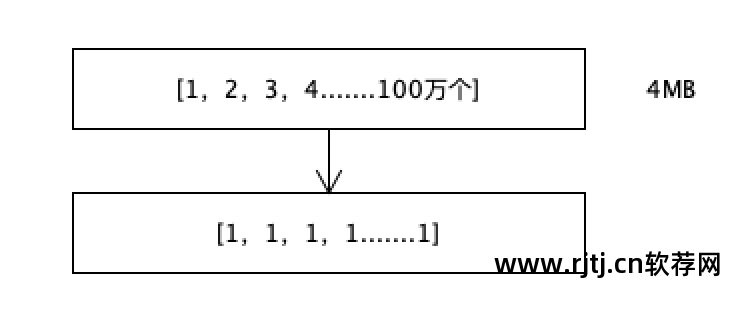
假设int数组中有1,2,3,4....多达100万个数字,大约占用4MB的空间。
每个数字都存储它与前一个数字之间的差异。 差值总是1。如果一个数字是1,那么它可以存储在一位中,因为一位的存储范围是0-1。 最初,32 位用于存储数字。 现在使用1位来存储。 一百万个数字只使用一百万位。 原数为3200万比特,压缩比为32倍。
如果数据量是32T,压缩后就变成1T。 1T检索效率是32T检索效率的32倍。
这是一个极其特殊的情况,因为实际上 ids 不会重复,也不会连续。 如果它们不连续,则差值不会为 1。
倒排表中存储的是ID。 这里的数字不是连续的,但是一定是按顺序,从小到大的。 顺序是在创建索引时排序的。

6个数字,1个数字占4个字节,即占24个字节。
计算差异,差异结果列表为
1位的取值范围是0-1; 2位为0-3,可存储4个数字; 3位,即2的3次方为8,取值范围为0-7。

8位可以存储256个数字。
自定义类型来存储数字。
我们看看差值列表中最大的数字是不是227,能用7位来存储吗? 7位可以存储的最大值是127。显然,它不能存储小于227的。只能用8位来存储,因为8位可以存储最大的数字。 存储255。
目前,这个数组中的每个数字只需要8位来存储,即6个数字、48位、6个字节。
本来这6个数字需要24个字节,现在只需要6个字节,压缩到原来大小的1/4。
继续优化...
227用8位来存储,但是2位可以存储2,因为2位的存储范围是0-3。

当这个值被剪切时,前面用8位存储大数,后面用4位存储小数。 不用担心从哪里剪,只要看哪一侧的数字间隔较大就可以了。 比如前面的数字突然从227变成了2,后面的数字就比较小。 前面的数字以8位存储,后面的数字取决于其最大值。
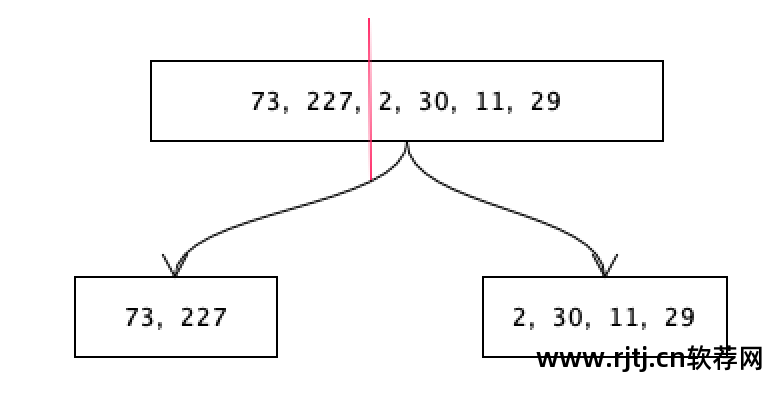
后面的最大数字是30,可以用5位来存储(取值范围是0-31),也就是说后面数组中的每个数字都可以用5位来存储。
至此,一个大阵已经被分割成了两个小阵。 前一个数组使用8位来存储每个数字,后一个数组使用5位来存储每个数字。
JDK定义32位用于存储int类型数据,64位用于存储long类型数据。
自定义一个使用5位存储的类型,称为α,定义一个使用8位存储的类型树叶快照软件,称为β。 类型定义也占用一个字节的空间。 如果为每个数字都定义一个类型,那么定义的类型就会太多,并且会占用大量空间。 如果73和227都用8位alpha存储,则alpha类型本身占用一个字节。
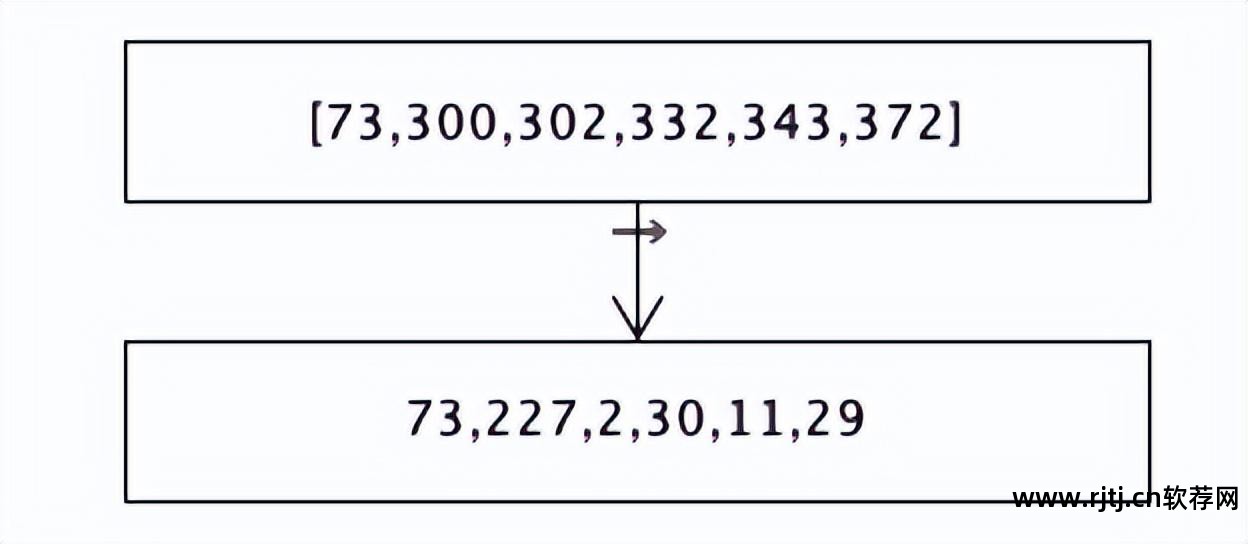
接下来计算一下这个差异列表[73,227,2,30,11,29]总共占用了多少空间?
73和227使用8位自定义类型β存储。 β类型占用1字节。 每个数字占用 8 位或 1 个字节。 2位数字占用2个字节,总共占用3个字。 节日。 以下数组 2、30、11 和 29 使用 5 位的自定义类型 α 进行存储。 α类型占用1个字节,每个数占用5位。 4个数字是20位,也就是3个字节,总共4个字节,所以这个数组总共占用3+4=7个字节。
使用自定义类型来存储每个数字,看看它会占用多少空间?
73是使用7位来存储的(在计算机操作系统层面,数据存储的最小单位是字节,一个字节就是8位。这里使用7位,其实并不节省空间,实际占用的空间还是8位bits(假设这里占用7位),这个定义的类型占用1个字节;8位存储227,自定义类型占用1个字节;那么数组[73,227]总共占用1B+7b+ 1B+1B一共是3个字节+7个位,这意味着不但没有节省空间,反而浪费了好几个位的空间,也就是说,不需要把数组分割得那么细,把这些数据浮点成很小的数。放在一起,把这些较小的数据放在一起是最合适的。
倒排索引的流程
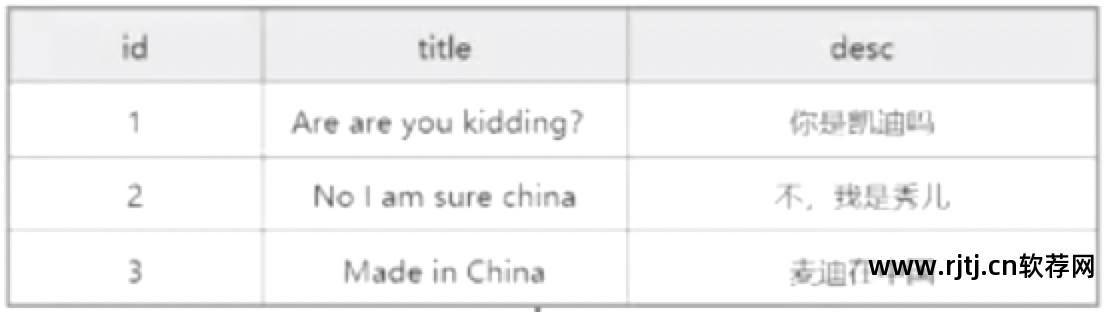
首先,分词。 英语的分词规则是按照空格来分词。 分割后,你会得到几个词汇项。

然后对当前term进行归一化(例如,Are开头的大写字母转换为are,china和chinese转换为china(这是两个词,我希望将它们转换为一个词以减少检索成本),转换为is,过去分词转换为现在分词(made转换为make,kidding转换为kid)),去重,字典排序(根据abc..),最终结果存在于术语字典(termdictionary)中
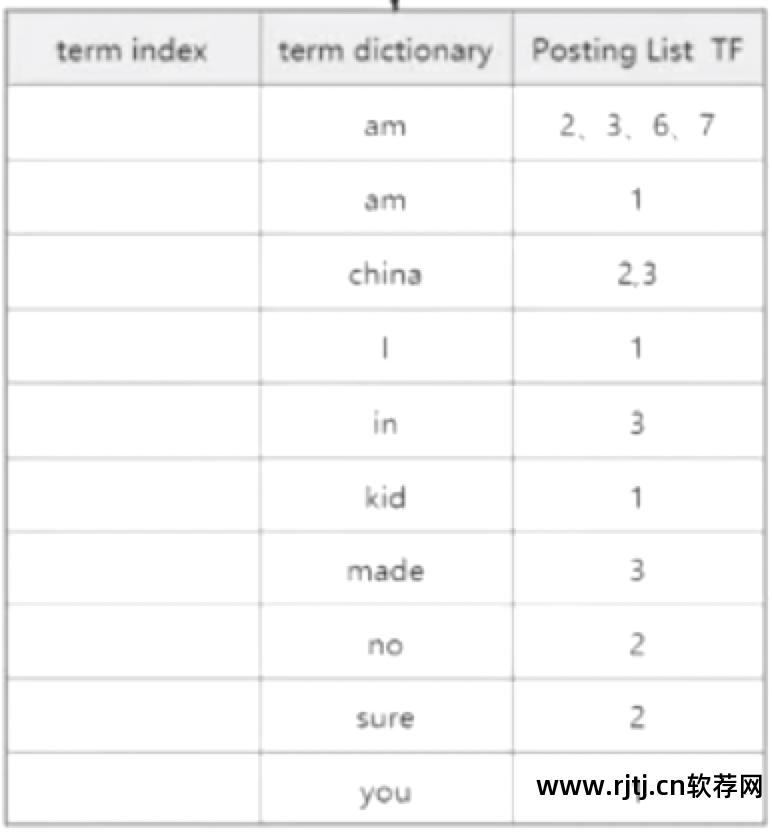
有序术语词典存储去重后的所有结果。 当然,存储并不是以二维表的形式存储的。
Posting List是一个倒排列表,存储了包含当前term的id集合。
TF 是该术语出现的频率。
磁盘格式化
1、容量是选择要格式化的磁盘。
2. 文件格式:
Windows、Linux 和 macos 都有这种文件格式。 缺点是每个网格都比较大。
使用这种格式,如果是大文件还好,但是如果是小文件就会占用很多磁盘空间。
3、单位是数据页空间的大小。 exFAT 的默认值是 128KB,NTFS 的默认值是 4KB。
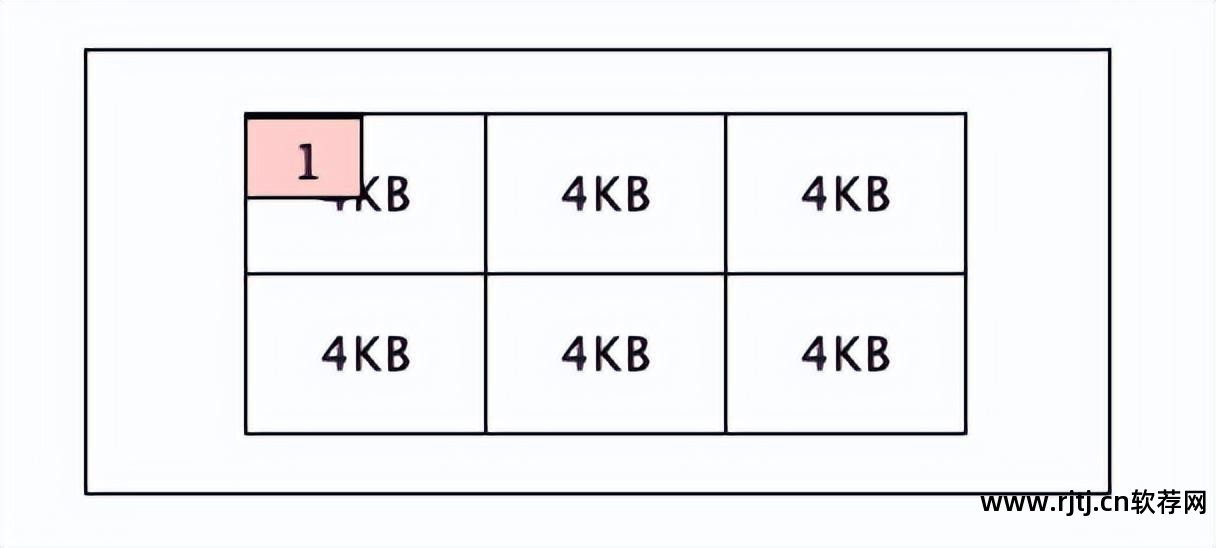
如果一个文件大小为1KB,不占用4KB的网格,那么该文件也会占用4KB的空间。

当内存检索数据时,它会从磁盘读取至少一格数据。 磁盘上的一个格子占用4KB的空间,因此内存从磁盘读取的最小数据单元是4KB的格子。
搜索引擎相关指标
全文检索的搜索引擎有百度、搜狗、Google; 垂直搜索的搜索引擎包括汽车之家和小米有品。
高效压缩、快速编解码
两种相关性评分算法BM25和TF-IDF
召回率是衡量返回数据丰富程度的指标,返回的数据越多,召回率越高。
搜索和检索之间的区别
搜索要么满足条件,要么不满足条件。 它并没有说它部分满足条件;而是说它部分满足条件。 但搜索是相关的。

本查询示例中,查询“小米NFC手机”时,id=1的数据包含2个term,相关性为2; id=2的数据包含3个term,那么id=2的数据和查询需求更相关。
