在计算机的早期汇编软件 64位,硬件很昂贵,程序员很便宜。 这些廉价的程序员甚至没有“程序员”的头衔,而填补这一角色的往往是数学家或电气工程师。 早期的计算机是用来快速解决复杂的数学问题的,所以数学家天生就适合“编程”的工作。
什么是程序?
首先,了解一些背景知识。 计算机本身无法做任何事情; 他们执行的任何行为都需要由程序来指导。 您可以将程序视为一个非常精确的配方,它接受输入并产生相应的输出。 配方中的每个步骤都包含用于操作数据的指令。 听起来有点复杂,但你可能知道这句话的意思:
1 + 2 = 3
加号是“指令”,数字1和2是数据。 数学中的等号意味着等式两边“等价”,但在大多数编程语言中对变量使用等号意味着“赋值”。 如果计算机执行上述语句,它会将加法的结果(即“3”)存储在内存中的某个位置。
计算机知道如何用数字执行数学运算以及如何在内存结构中移动数据。 这里我就不展开记忆了。 你只需要知道内存一般分为两类:“速度快/空间小”和“速度慢/空间大”。 CPU寄存器的读写速度非常快,但空间很小,相当于一张速记纸条。 主存通常有很大的空间,但读写速度却远不如寄存器。 程序运行时,CPU不断地将其需要的数据从主存移至寄存器,然后将结果放回主存。
汇编器
当时电脑价格昂贵,劳动力相对便宜。 程序员花费大量时间将手写的数学表达式翻译成计算机可以执行的指令。 第一批计算机的用户界面非常差,有些甚至在前面板上有切换开关。 这些开关代表存储器“单元”中的“0”和“1”。 程序员需要配置一个内存单元,选择存储位置,然后将该单元提交到内存中。 这是一个耗时且容易出错的过程。

程序员 Betty Jean Jennings(左)和 Fran Bilas(右)操作 ENIAC 主控制面板
后来,一位电气工程师认为自己的时间很宝贵,所以他写了一个程序,可以将像“菜谱”这样人们可以理解的输入转换成计算机可以理解的版本。 这就是最初的“汇编器”,在当时引起了不小的争议。 这些昂贵机器的所有者不想将计算资源浪费在人类已经可以完成的任务上(尽管速度缓慢且容易出错)。 然而,随着时间的推移,人们发现使用汇编程序比人类编写机器语言更快、更准确,并且计算机完成的“实际工作量”也随之增加。
尽管汇编程序比在机器面板上切换位状态有了很大的改进,但这种编程方法仍然非常专业。 上面的加法示例在汇编语言中看起来像这样:
01 MOV R0, 1 02 MOV R1, 2 03 ADD R0, R1, R2 04 MOV 64, R0 05 STO R2, R0
每一行都是一条计算机指令,前面是指令的缩写,后面是指令操作的数据。 这个小程序首先将值 1“移动”到寄存器 R0,然后将 2 移动到寄存器 R1。 第03行将寄存器R0和R1中的值相加,然后将结果存储到寄存器R2中。 最后,第 04 行和第 05 行确定结果应放置在主存储器中的哪个位置(在本例中为地址 64)。 管理数据在内存中的存储位置是编程中最耗时且最容易出错的部分之一。
翻译员
汇编器比手写的计算机指令要好得多,但早期的程序员仍然渴望能够以他们习惯的方式编写程序,比如编写数学公式。 这种需求推动了高级编译语言的发展,其中一些已经成为过去,而另一些至今仍在使用。 例如,ALGO 已经成为过去,但像 Fortran 和 C 这样的语言仍然在解决现实世界的问题。
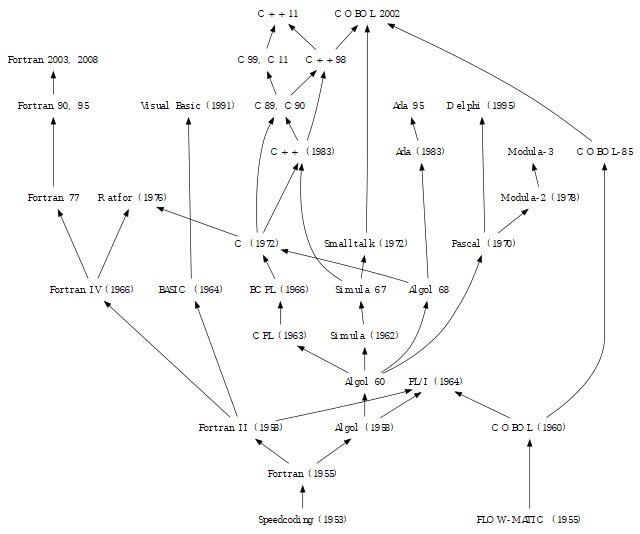
ALGO 和 Fortran 编程语言的谱系树
这些“高级”语言允许程序员以更简单的方式编写程序。 在C语言中,我们的加法程序就变成这样:
int x; x = 1 + 2;
第一条语句描述了程序将使用的内存块。 在此示例中,该内存应占用一个名为 x 的整数的大小。 第二个语句是加法,尽管它是倒着写的。 AC 程序员会说这是“X 被分配了值 1 加 2”。 需要注意的是,程序员不需要决定将x存储在内存中的何处,这个任务留给编译器。
这种新程序被称为“编译器”,可以将用高级语言编写的程序转换为汇编语言,然后使用汇编器将汇编语言转换为机器可读的程序。 这种程序组合通常称为“工具链”,因为一个程序的输出直接成为另一个程序的输入。
编译语言相对于汇编语言的优势在于从一台计算机迁移到另一台不同型号或品牌的计算机时。 在计算机发展的早期,许多公司,包括 IBM、DEC、德州仪器、UNIVAC 和惠普,都生产各种不同类型的计算机硬件。 这些计算机没有太多共同点,只是它们都需要连接到电源。 它们在内存和 CPU 架构方面的差异相当大,将程序从一台计算机翻译到另一台计算机通常需要数年时间。
使用高级语言汇编软件 64位,我们只需要将编译工具链迁移到新平台即可。 只要有编译器,用高级语言编写的程序最多只需稍加修改就可以在新计算机上重新编译。 高级语言的编译是真正的革命性成就。

1983 年发布的 IBM PC XT 是硬件价格下降的早期例子。
程序员的生活得到了很大的改善。 相比之下,通过高级语言表达他们想要解决的问题会让事情变得容易得多。 由于半导体技术的进步和集成芯片的发明,计算机硬件的价格急剧下降。 计算机变得越来越快、越来越强大、而且越来越便宜。 在某个时间点(也许是 20 世纪 80 年代末),事情发生了逆转,程序员变得比他们使用的硬件更有价值。
口译员
随着时间的推移,出现了一种新的编程方式。 一种称为“解释器”的特殊程序可以直接读取程序并将其转换为计算机指令以立即执行。 与编译器非常相似,解释器读取程序并将其转换为中间形式。 但与编译器不同的是,解释器直接执行程序的中间形式。 解释型语言每次执行都会经历这个过程; 编译后的程序只需要编译一次,然后计算机每次只需要执行编译后的机器指令。
顺便说一下,这个特性就是人们感觉解释型程序运行速度较慢的原因。 但现代计算机的功能如此强大,以至于大多数人无法区分编译程序和解释程序之间的区别。
解释型程序(有时称为“脚本”)更容易移植到不同的硬件平台。 由于脚本不包含任何特定于机器的指令,因此同一版本的程序可以直接在许多不同的计算机上运行,无需任何修改。 但当然,必须先将解释器移植到新机器上。
Perl 是一种非常流行的解释语言。 用 Perl 完全表达我们的加法问题将如下所示:
$x = 1 + 2
虽然这个程序看起来和C语言版本类似,执行起来也没有太大区别,但是缺少初始化变量的语句。 实际上还存在一些其他差异(超出了本文的范围),但您应该已经注意到,我们编写计算机程序的方式与数学家使用笔和纸手写数学表达式的方式非常接近。
虚拟机
最新的编程方法是虚拟机(通常称为VM)。 虚拟机分为两类:系统虚拟机和进程虚拟机。 尽管范围不同,但这两种虚拟机都提供了与“真实”计算硬件不同的抽象级别。 系统虚拟机是替代物理硬件的软件,而进程虚拟机被设计为以“系统无关”的方式执行程序。 所以在这个例子中,进程虚拟机(以后我所说的虚拟机就是指这种类型)的作用域和解释器类似,因为程序首先被编译成中间形式,然后虚拟机执行它。 这种中间形式。
虚拟机和解释器之间的主要区别在于虚拟机创建虚拟CPU和虚拟指令集。 有了这层抽象,我们就可以编写前端工具,将不同语言的程序编译成虚拟机可以接受的程序。 也许最流行和最知名的虚拟机是 Java 虚拟机 (JVM)。 JVM 在 20 世纪 90 年代最初仅支持 Java 语言,但如今它可以运行许多流行的编程语言,包括 Scala、Jython、JRuby、Clojure、Kotlin 等。 还有一些不太常见的例子,这里就不一一列举了。 我最近还了解到,我最喜欢的语言Python并不是解释性语言,而是运行在虚拟机上的语言!
虚拟机延续了一个历史趋势,要求程序员在使用特定领域的编程语言解决问题时对特定计算平台的了解越来越少。
就是这样
我希望您喜欢这篇简短解释该软件如何工作的短文。 接下来您还希望我讨论其他话题吗? 在评论中告诉我。
通过:
本文由 LCTT 原创编译,Linux China 自豪推出
正在学习C/C++的朋友可以回复小编私信“学习”领取全套免费的C/C++学习资料和视频。
