适用系统:windows;
操作软件:
Adobe Acrobat Pro DC2019;
文字识别:
在上一篇教程中,小编讲到了使用其他识别软件,需要单独安装:
这个问题说明:
在DC 2019版PDF中实现OCR字符识别

本文以识别英文扫描的文档为例汉王ocr文字识别软件教程,中文识别准确率同样高;
步骤如下:
01
方法一:使用“编辑工具”;
(此方法一键识别,操作快捷方便;识别的文本准备情况与方法二相同汉王ocr文字识别软件教程,但复制的文本段落格式不如方法二准确);
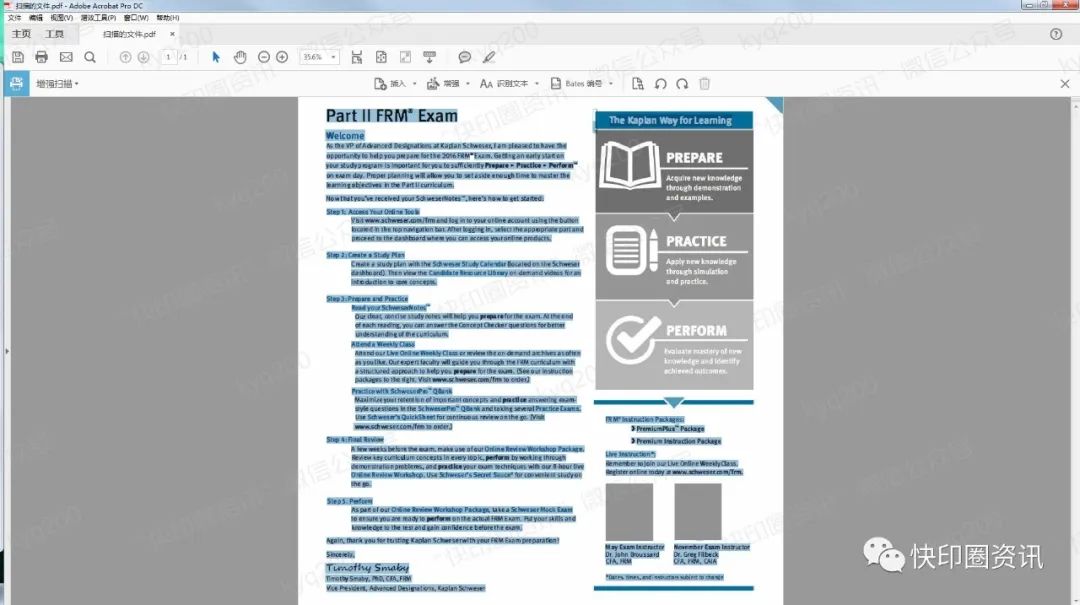
在PDF中打开扫描的PDF文件,按快捷键Ctrl+D检查该文件是否为不可编辑的PDF文件(如果是图像格式,请先将其转换为PDF格式),关闭文档属性窗口,然后单击“确定”。点击工具栏右侧的“编辑PDF”;
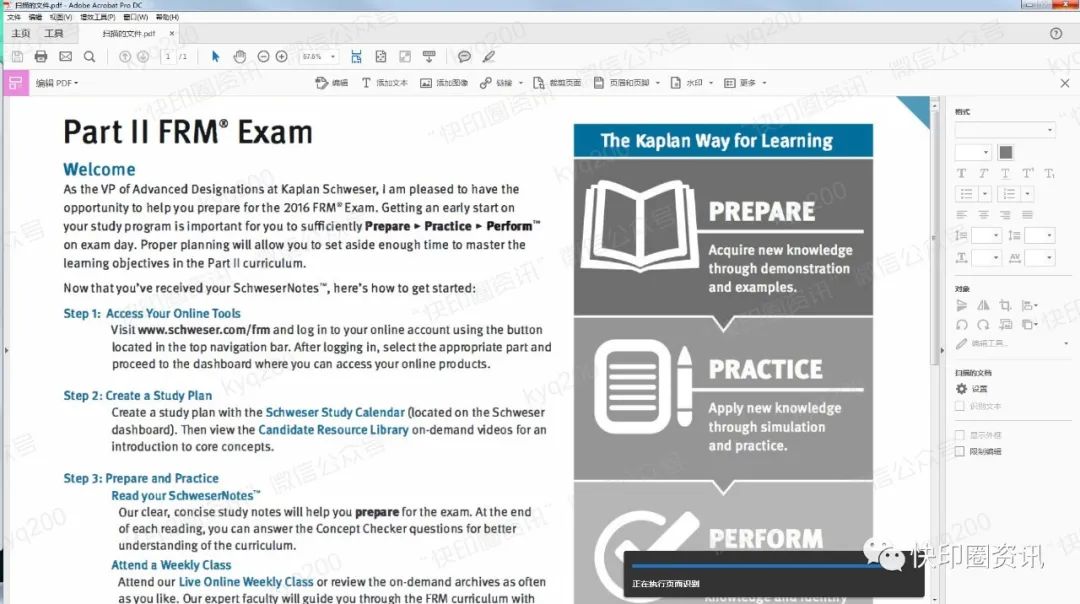
转换过程中,文件右下角有进度条指示“正在执行页面识别”;
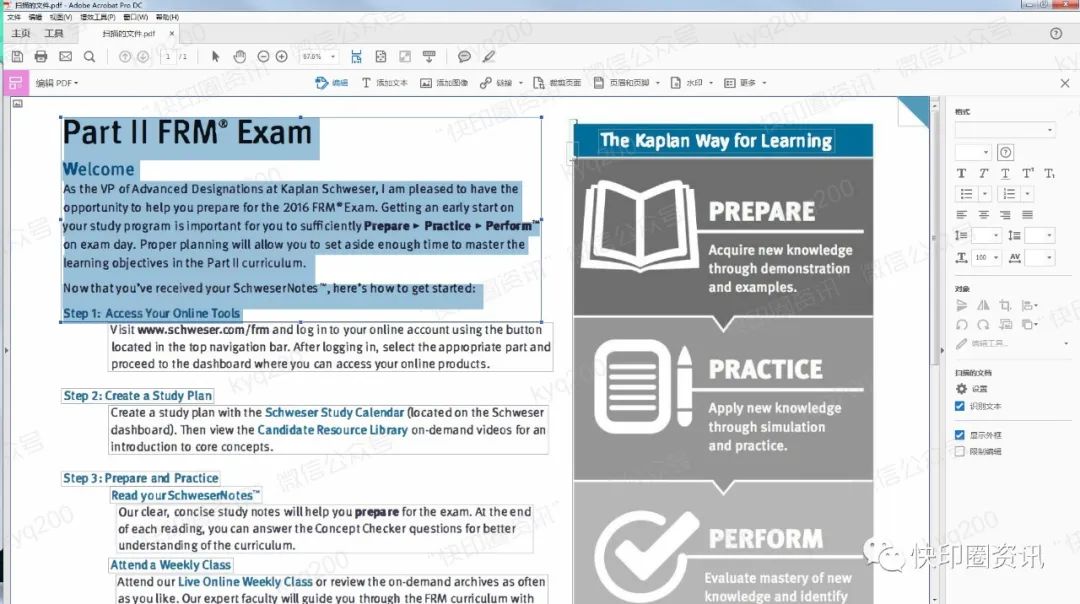
此时我们可以看到图片已经变成了一个带有可选择文本的文件。 鼠标左键,文本工具,可以选择识别的文本,右键复制;
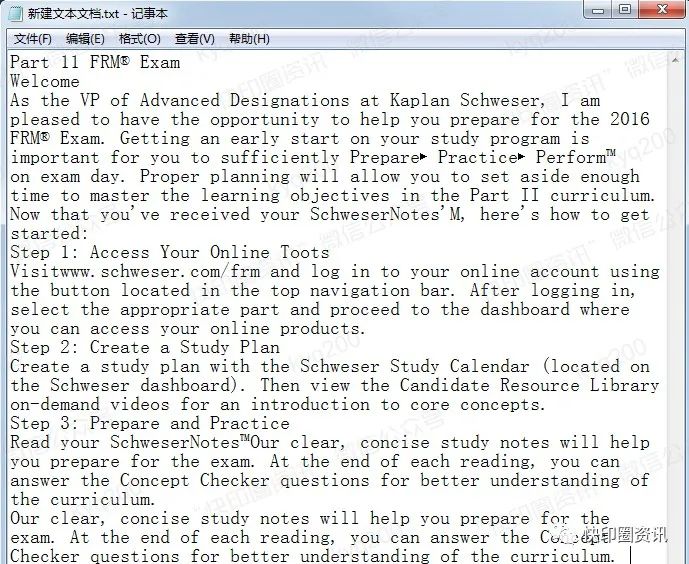
由于编辑工具中的识别会以段、帧的形式呈现,如果需要识别的文件较多,建议使用方法二。 如果我们需要整个页面的全部内容,我们将每个段落的内容复制到记事本中并粘贴;
02
方法二:使用“增强扫描”工具;
以PDF格式打开扫描的PDF文件,点击工具栏右侧的“增强扫描”;

单击文件顶部的“识别文本”,然后单击在此文件中;
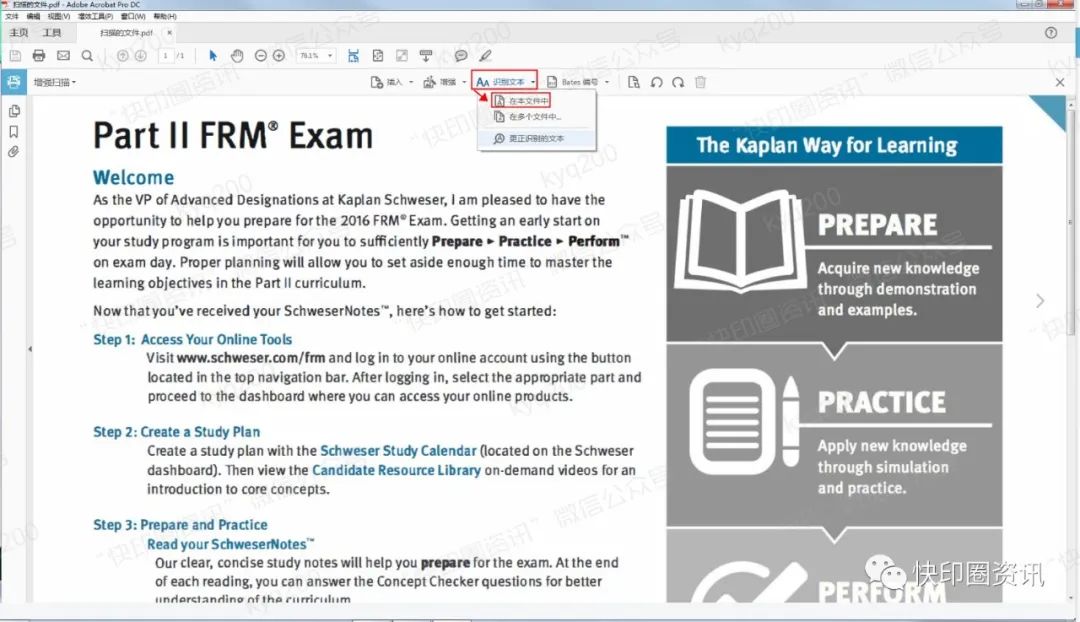
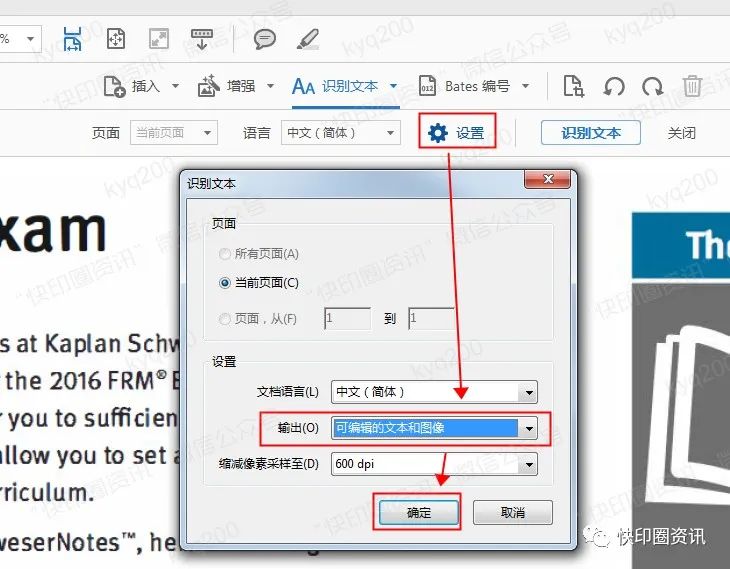
单击“设置”。 在弹出的“识别文本”窗口中,如果要识别单个页面,请点击“当前页面”。 如果要识别多页文件的所有页面,请选择“所有页面”;
文档语言默认选择“中文(简体)”;
选择“可编辑文本和图像”作为输出选项;
将像素下采样到默认选择的 600dpi;
单击“确定”
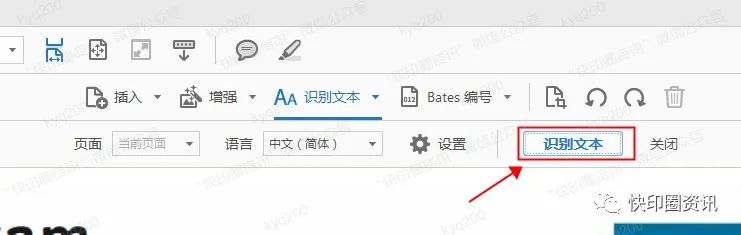
最后我们点击“识别文本”;
转换过程中,文件右下角有进度条指示“正在执行页面识别”;
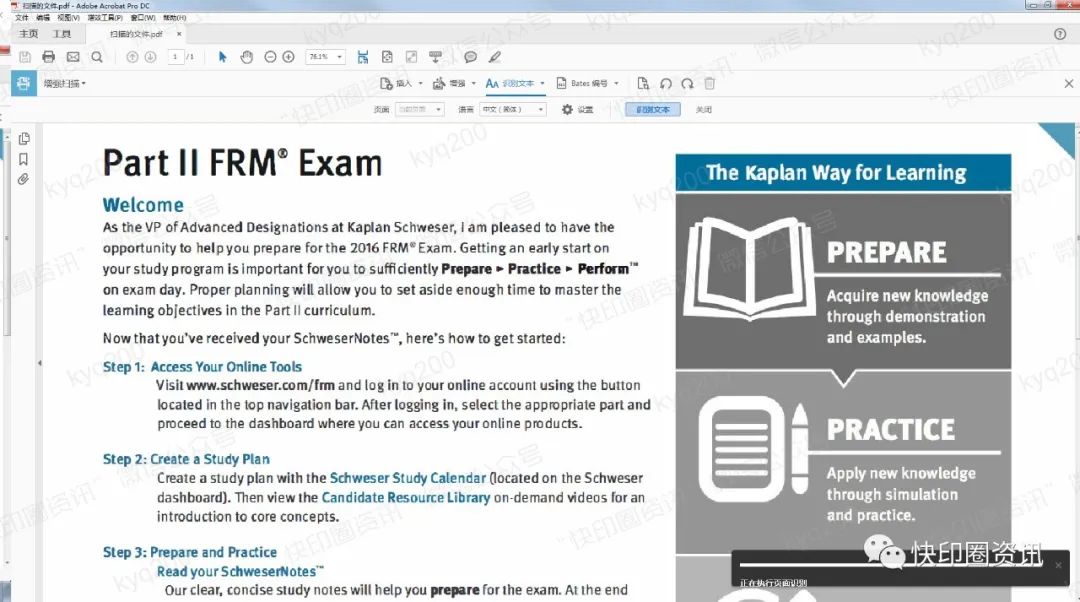
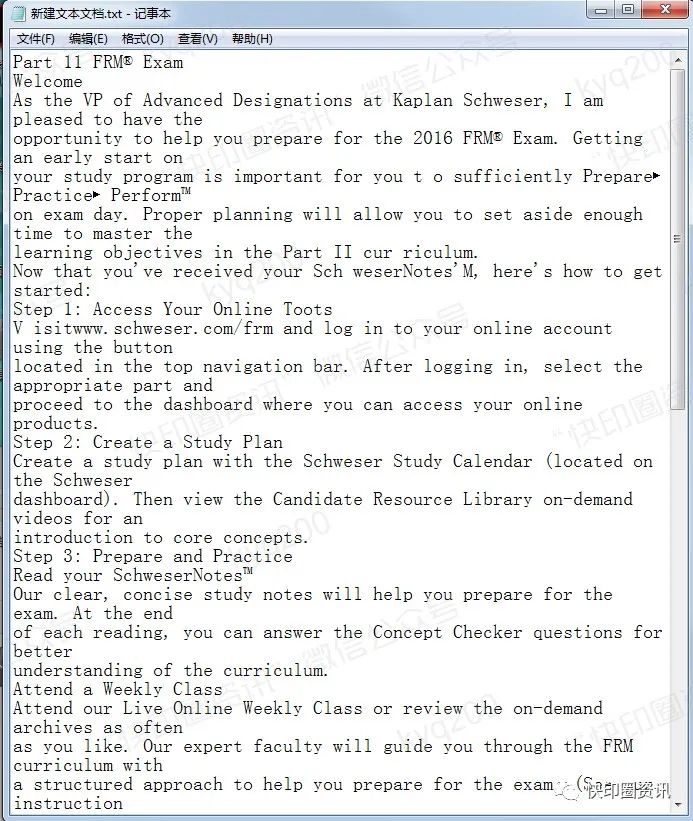
使用此方法,可以选择整个页面(单页)或整个文档(多页文件)的所有内容文件,并且可以将内容一次性复制到记事本中并粘贴;
粘贴到记事本中的内容格式与原始PDF文件的文本格式相同,非常准确;
概括
以上就是小编在Adobe Acrobat Pro DC 2019版PDF中识别图像中的文字并保存为文本文件的方法,利用PDF增强扫描快速分析图像文件,进行快速高精度的识别操作。
温馨提示:识别出来的文件可能需要稍作修改,所以输出前需要仔细检查文件。
