今天的推文列表
1、多种翻译软件是否出现大规模轮换?机器翻译存在哪些不确定性?
2、《外语》2020年第3期目录预览!
3.航空语言·论坛ll北京航空航天大学外语大师论坛(6月22-27日)
4. 90个容易出错的习语
5.文化ll《你好,中国》英文版(71-72)
6.经典英语学习教材《穿越美国》视频(08)
本文为第(1)条。 您可以通过关注其余推文来查看它们。 欢迎关注!
作者 | 蒋宝尚
编辑| 从末
自然语言处理确实是人工智能皇冠上的宝石。 在采摘这种水果的路上,人类可能只走了一半。
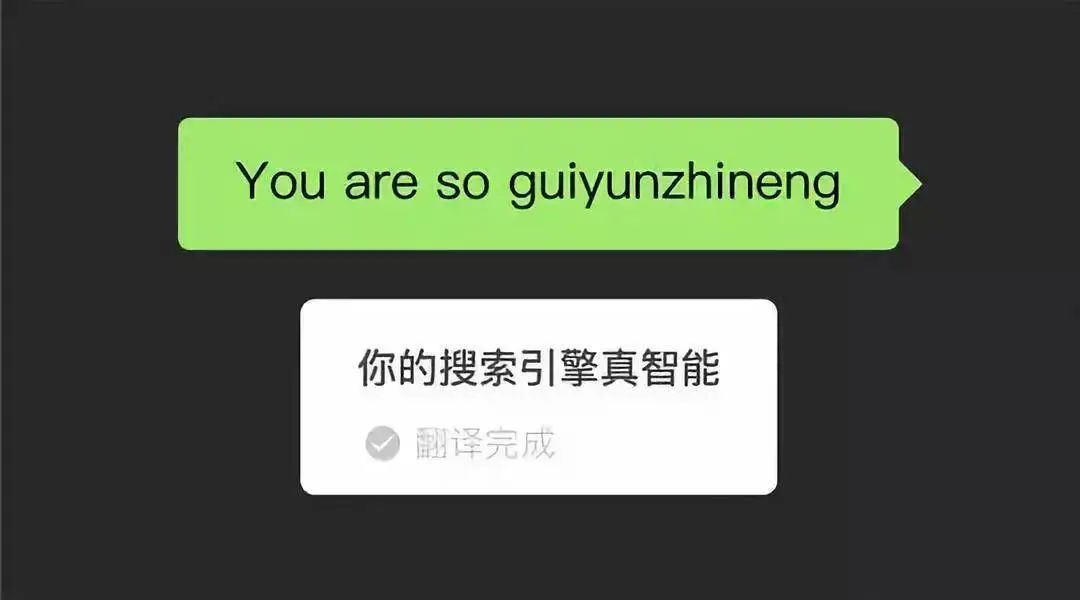
具体表现就是,在机器翻译的世界里,始终无法赋予机器足够的“灵性”。 例如,林则徐在虎门卖烟就被某软件翻译成“林则徐在虎门卖烟”。
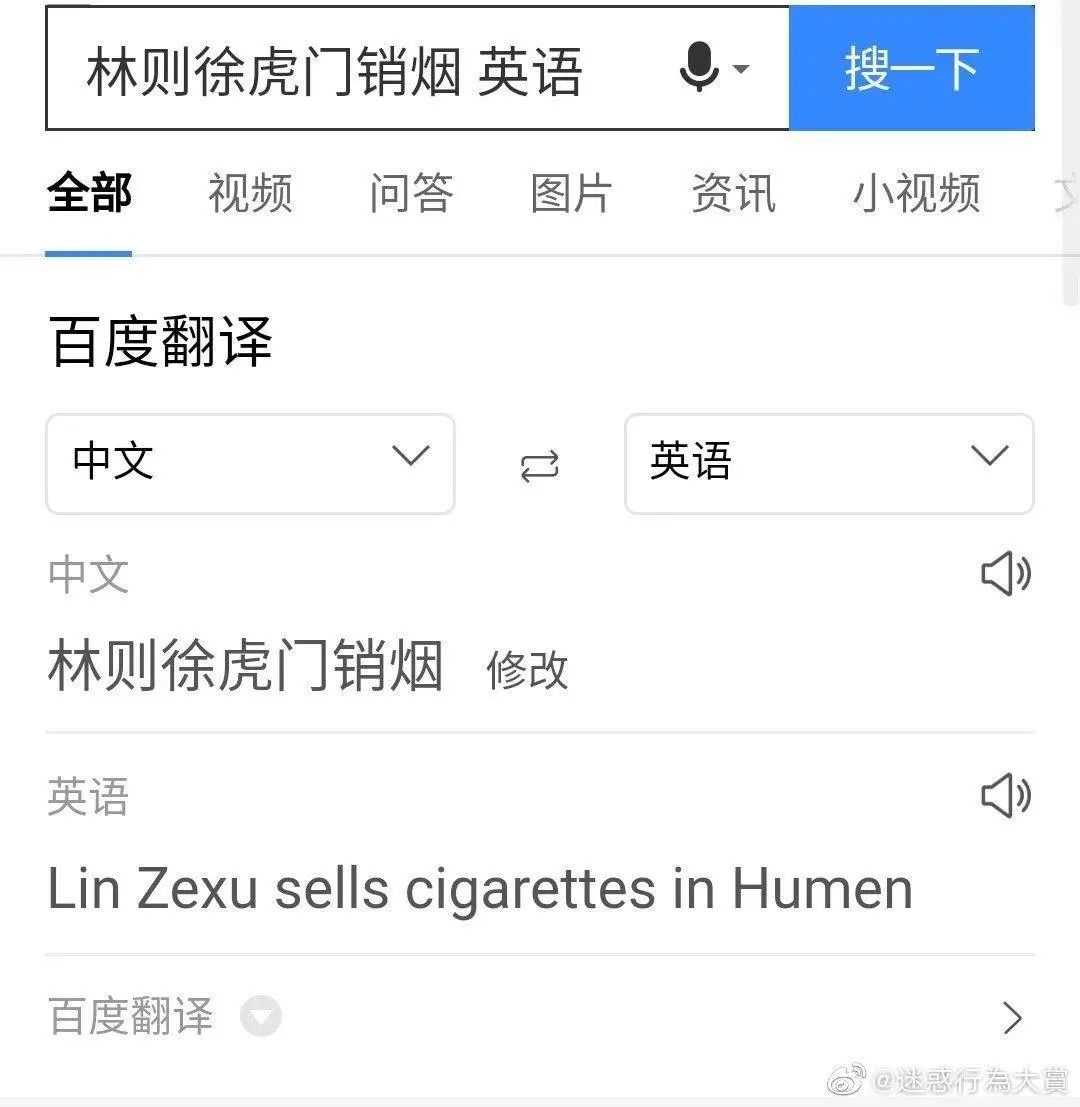
注:作者随后百度测试时发现翻译正确:“林则徐在虎门销毁鸦片”
显然,机器将“销售”等同于“销售”。 事实上,这种等价对于其他没有上下文的人来说是完全可行的。 比如小李虎门卖香烟=小李虎门卖(销售)香烟,小明虎门卖香烟=小明虎门卖(销售)香烟。 然而,对于林则徐来说,这种混淆是任何情况下都做不到的,因为句子本身就含有上下文。 虎门销毁鸦片是中国近代史上的一件大事。 对于翻译人员来说,这是非常重要的背景知识。 被销毁(销毁)的是鸦片(香烟)。 目前的机器翻译系统显然缺乏理解这类知识的能力。 这也可能是翻译错误的重要原因。
对此,AI科技评论还专门测试了其他几款知名翻译软件。 其性能如下:
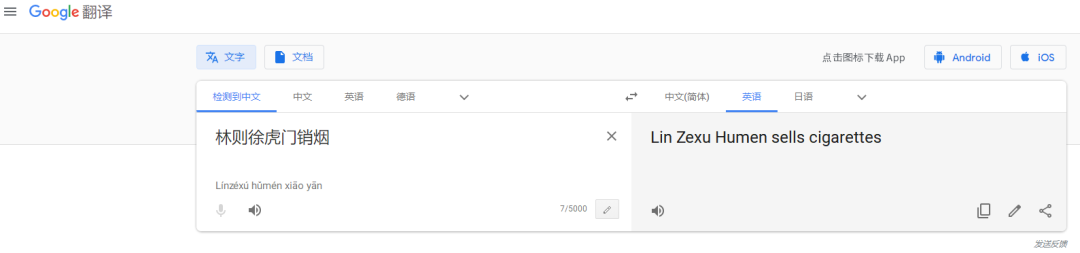
显然,谷歌翻译也未能经受住考验。
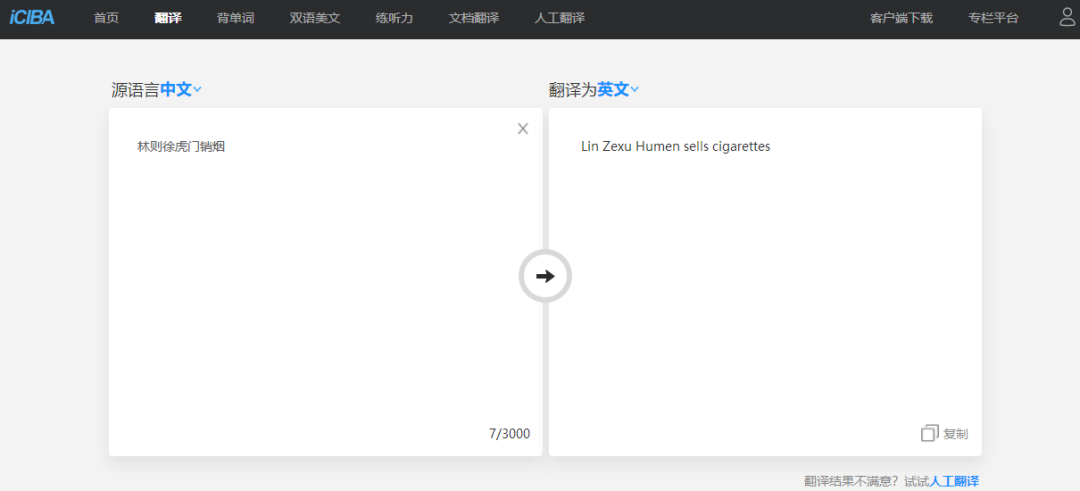
金山的翻译仍然是“卖”,而且这个动词也用第三人称单数!
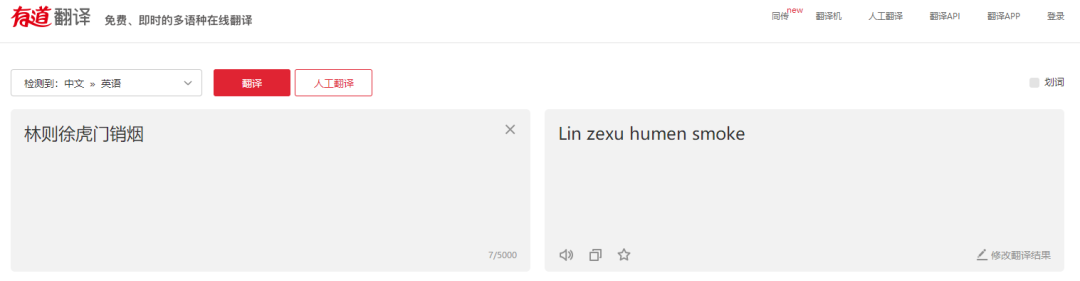
有道翻译为:“消除香烟=香烟”。 有道的整体翻译总感觉怪怪的。 如果把smoke当成动词“抽烟”,那就没有意义了! 难道它把“林则徐虎门”当成一个人了?
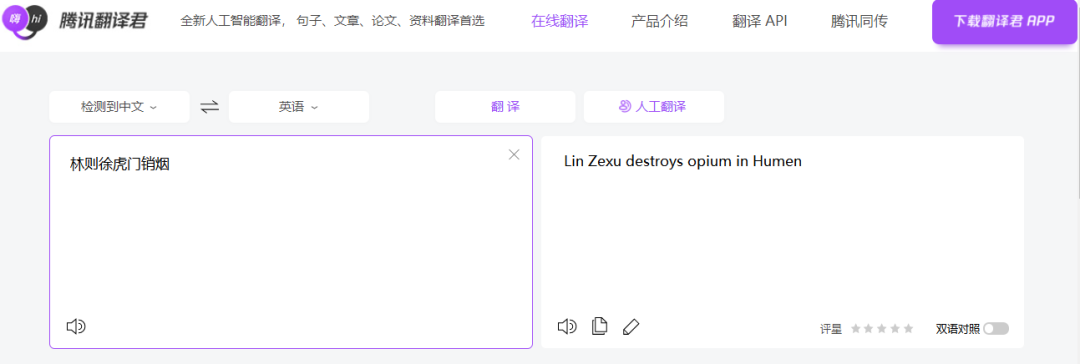
腾讯翻译硕果累累,《林则徐虎门销毁鸦片》点燃了希望之光~
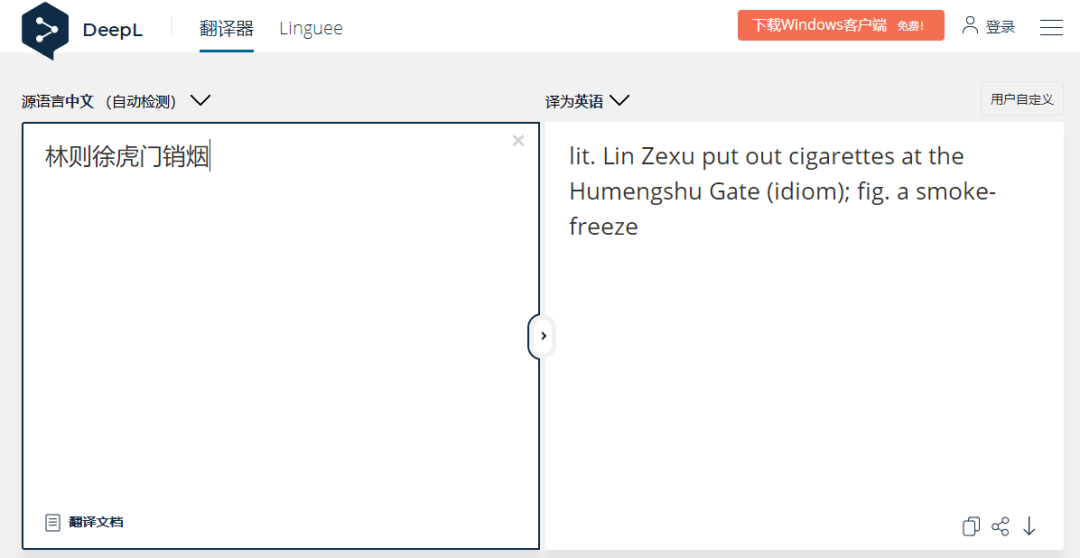
我们尝试了在日本流行的DeepL:翻译比较完整,但是它没有正确翻译“烟=鸦片”,并且翻译中包含一些多余的单词。
数据和算法双重问题导致翻译错误
那么,一个缺乏上下文的简单句子能否解释为什么这么多翻译软件存在错误呢? 为此,AI技术评论专门咨询了东北大学自然语言处理实验室主任肖童先生。 他解释道:“主要问题是训练数据的覆盖率。当数据中有大量‘销售’时,就视为卖出,对于不常见的数据,就视为卖出。有些用法不能还没有被机器翻译处理。说到底,机器翻译还是在“死记硬背”。它没有见过情景,无法像人类一样推理,缺乏真正理解句子的能力。”
小牛翻译创始人、东北大学教师朱静波将这种译文与原文含义不同的现象称为“飞走”现象。 他解释道:“造成这种现象的原因是神经机器翻译技术本质上不具备准确性。句子是真正被理解的,所以有时无法保证翻译的保真度。这个问题在早期的神经机器翻译中更为严重,但现在这个问题已经得到缓解。偶尔会出现,但并不常见。”

论文链接:
关于机器翻译的这些bug,2018年也有一篇论文详细阐述了这些现象。 这篇论文的第一作者是来自 FAIR 的 Myle Ott。 他在论文引言中提到:目前大多数机器翻译模型都是基于神经网络(NMT)的,而神经网络机器翻译显然不会给出新词(稀有词),最明显的表现就是曝光偏差机械英语翻译软件,这简直就是由于训练过程中的文本生成和推理过程中的文本生成不一致造成的。
在论文中,作者对包括但不限于“新词”在内的机器翻译现象进行了总结:所有机器翻译问题的基本主题是不确定性,即学习任务的一对多性质,换句话说,给定一个句子有多个翻译结果。
那么,对于这种不确定性,作者将原因分为两类,一类是数据的不确定性,一类是模型解释(搜索)信息的不确定性。
数据的不确定性有两个来源:内在的和外在的。
固有的不确定性表现在一个句子可以有多个等价的翻译。 因为在翻译的过程中,或多或少都可以是字面的,即使字面表达同一个意思的方式有很多种。 句子的表达可以是主动或被动,对于某些语言,“the”、“of”或“their”等词也是可选的。 除了一个句子可以有多种翻译的情况外,缺乏规范性也是翻译不确定性的一个来源。
此外,在没有上下文输入的情况下,模型通常无法预测翻译语言的时态或数量,因此简化或添加相关上下文也是翻译不确定性的来源。
外部不确定性表现在使用低质量的网络数据进行高质量的人工翻译。 这个过程很容易出错,并导致数据分布的其他不确定性。 目标句子可能只是源句子的部分翻译,或者目标句子可能包含源句子中未找到的信息。
为了量化模型输出的不确定性,作者首先在论文中比较了集束搜索和采样两种搜索策略,然后研究了数据中特定类型的外部不确定性对集束搜索的影响。 结论是波束搜索非常有效,并且较大的波束宽度在找到更高似然性输出方面也更有效,而外部不确定性通过影响波束宽度来影响搜索的有效性。
在论文的最后,作者采取了更全面的观点,并将估计分布与真实数据分布进行了比较。 结论是,模型在假设空间中传播的概率与数据分布相比太大,通常会低估单个假设的实际概率。 换句话说,模型根据概率输出翻译结果,有时可能不可靠。
机器翻译:如何阻止机器死记硬背?
回顾机器翻译技术的发展历史,第一代是基于规则的机器翻译技术RBMT机械英语翻译软件,主要由专家手工编写翻译规则来实现; 第二代是统计机器翻译技术SMT,第三代是目前主流的神经机器翻译技术NMT。
第二代SMT和第三代NMT采用机器学习方法,数据驱动,基于大规模双语句子对训练和构建机器翻译系统。 由于人工编写规则的成本非常高,因此构建大规模双语句子对的成本也非常高。 收集许多语言对的大规模双语句子对是很困难的。 在上面的例子中,机器将《虎门灭烟》中的“销”字作为“销售”处理,正是由于语料库的稀缺性。
朱静波老师曾在去年9月的AI时代活动中提到现在的机器翻译和我们的外语学习机制的区别:我们学习外语的方式不是通过阅读大量双语文章,而是通过背单词。 学习语法,阅读大量外国单语文章,不知不觉中掌握外语。 但机器学习外语的方式却截然不同。 无论是上一代的统计机器翻译,还是当前主流的神经机器翻译,机器翻译系统都是基于大量的双句对训练而构建的。 从这个角度来看,为了缓解神经机器翻译技术在稀缺术语上“翻车”的现状,需要引入新的学习机制,比如朝着人类学习外语新范式的方向发展,摆脱对大规模双语句子对的依赖。 。 这就像AlphaGo最初是根据人类棋谱学习的,然后AlphaGo Zero引入了一种新的学习方法,不依赖人类棋谱进行学习,下棋水平实际上更高了。
然而,要让机器像人类一样学习外语,有一个迫切需要解决的问题:翻译者拥有非常强的母语语法,能够准确判断母语翻译是否符合母语。 错误会自动更正,比如下面这句话:
“研究表明,汉字的顺序并不一定会影响阅读。比如,当你读完这句话后,你会发现这里的汉字都乱了。”
类似地,在翻译过程中,例如在英汉翻译任务中,为了构建表达特定含义的中文句子,仅从英文原句中获得少量的中文翻译词。 例如,使用“我明天要去北京”,我们可以很容易地构造一个合法的中文句子“我明天要去北京”或“我明天要去北京”,而不必说“我明天要去北京”和“明天我要去北京”等。合法的汉语句子在构建过程中不需要过多依赖英文原文。 这种能力被研究人员称为“生成能力”。 如何让机器具备与人类媲美的“生成能力”,是实现类似人类学习方式的“单语学习”第四代机器翻译的关键。
据《AI技术评论》报道,这项工作的瓶颈在于部分源语言的句法和语义分析技术仍处于起步阶段。 相关研究成果包括张跃、朱静波、刘群等人共同研究并于2014年发表在EMNLP上的论文《Syntropic SMT Using a Discriminative Text Generation Model》,论文首先分析了句子的句法成分和语义成分。源语言,然后根据部分翻译的基本单位生成目标语言,类似的工作最近也受到了一定的关注。

论文地址
毫无疑问,当前的机器翻译在重复性任务、翻译难度较低的低端翻译方面已经取得了一定的成绩,但要达到翻译“信、达、雅”的最终目标还需要时间。 天。 一个可喜的变化是,近年来,机器翻译和人工翻译领域的合作与交流日益频繁。 机器翻译技术目前正处于从量变到质变的积累期。 下一代机器翻译技术也将更加模仿人类的学习机制,开展人机协作的研究,而这种质变也许并不遥远。
OMT:微信和谷歌翻车小合集
这种对“生词”的处理不当,其实也是机器翻译的问题之一。 前段时间,火边B站的“谷歌翻译20遍”,正好反映了句子被机器翻译成英文,然后又翻译回来后,翻译不一致的情况。 以闰土少年为例,原文和二十遍后的译文分别是:
原文:一轮金色的圆月挂在深蓝色的天空中,下面是海边的沙地,那里种着一望无际的绿色西瓜。 其中有一个十一、十二岁的少年,脖子上戴着银环,手里拿着一把钢叉,用尽全力刺向阿云。 那媛扭动身体,从他的胯下逃了出来。
翻译:绿色的天空中几乎到处都有一轮无尽的金色月亮,海滩上布满了沙子。 此时,这名11岁的男孩用金属带将他的手尽可能地绑住,并将其放在金属手柄上。 大叔合身,从大叔身边逃了出来。

……看到这里,鲁迅叔叔的棺材板恐怕压不住了!
除了谷歌之外,【微信翻译】之前也出现过误译的情况,因为它无法有效处理未经训练的非正式英语词汇。 不过,微信翻译团队通过添加特殊词的复制机制初步解决了这个问题。 当时的截图如下:

当出现一个人的名字时,【微信翻译】就会产生乱码~~
