
虎嗅注:谷歌刚刚在博客中宣布,谷歌神经机器翻译系统进行了重大更新,使得单一模型能够通用表示多种语言。 该系统还实现了“零数据翻译”,这意味着它可以在以前从未见过的语言之间进行翻译。 这意味着传说中的“巴别塔”有望成真。 而像百度、科大讯飞这样的国内公司,一不小心就被扔到了10万公里之外。 至少公开信息是这么说的。 这篇文章发表在谷歌研究上。 作者是迈克·舒斯特 (Mike Schuster)、梅尔文·约翰逊 (Melvin Johnson) 和尼基尔·索拉特 (Nikhil Thorat)。 由微信公众号“新智元(微信公众号AI_era)”编译,译者:李静宜。
过去10年,谷歌翻译从仅支持几种语言发展到支持103种语言,每天翻译超过1400亿字。 为了实现这一目标,我们需要构建和维护许多不同的系统来在任意两种语言之间进行转换,这会产生巨大的计算成本。
神经网络已经彻底改变了许多领域,我们确信我们可以进一步提高翻译质量,但这样做意味着重新思考谷歌翻译背后的技术。
今年9月,谷歌翻译改用了名为谷歌神经机器翻译(GNMT)的新系统,这是一个端到端的学习框架,可以从数百万个示例中学习并显着提高翻译质量。
然而,虽然启用 GNMT 的多种语言的翻译质量有所提高,但将其扩展到 Google 翻译支持的所有 103 种语言是一项重大挑战。
实现零样本翻译
在论文《Google 的多语言神经机器翻译系统:实现零样本翻译》中,我们通过扩展之前的 GNMT 系统来解决这一挑战,以便单个系统可以在语言之间进行翻译。
我们提出的架构不需要更改基本 GNMT 系统,而是在输入句子的开头使用额外的“标记”来指定系统将翻译成的目标语言。 除了提高翻译质量之外,我们的方法还实现了“零射击翻译”,这使得系统可以在没有先验数据的情况下翻译以前从未见过的语言。
下图展示了最新GNMT的工作原理。 假设我们使用日语和英语、韩语和英语之间的翻译示例来训练多语言系统,如动画中的蓝色实线所示。
这个新的多语言系统与单个GNMT系统的大小和参数相同,并且能够实现日英和韩英两种语言对的双语翻译。 参数共享使系统能够将“翻译知识”从一种语言对转移到其他语言对。 这种迁移学习和多种语言之间翻译的需要迫使系统更好地利用其建模能力。
由此,我们思考:系统能否在它从未见过的语言对之间进行翻译? 例如,系统尚未经过韩语和日语之间翻译的训练。
但答案是肯定的——尽管从未被教授过,但新系统确实能够在两种语言之间生成合理的翻译。 我们称之为零镜头翻译,如动画中的黄色虚线所示。 据我们所知,这是此类迁移学习首次应用于机器翻译。
零数据翻译的成功提出了另一个重要问题:系统是否已经学习了一种通用表示,即不同语言中具有相同含义的句子以相似的方式表示,即所谓的“国际通用语言”(interlingua) )?
使用内部网络数据的 3D 表示,我们可以看到系统在翻译日语、韩语和英语时在各种可能的语言对(例如日语到韩语、韩语到英语、英语到日语等)之间进行转换。 等),内部发生了什么。
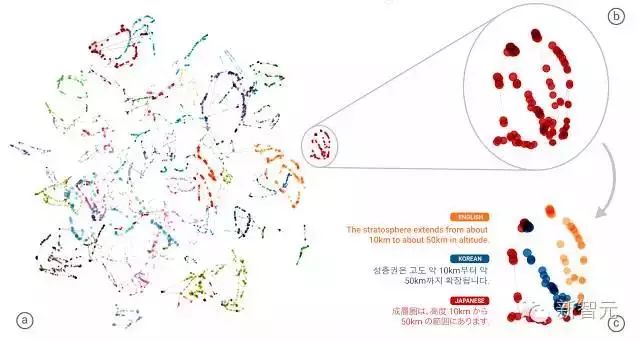
上图(a)部分显示了这些平移的整体几何构成。 图中不同颜色的点代表不同的含义; 具有相同含义的句子,从英语翻译成韩语,与从日语翻译成英语的句子具有相同的颜色。 从上图中我们可以看到,不同颜色的点形成了组。
(b)部分是这些点集之一的放大结果,(c)部分由原始语言的颜色显示。 在单个点集中,我们可以看到日语、韩语和英语三种语言中具有相同含义的句子聚集在一起。
这意味着网络必须对句子的语义进行编码,而不是简单地记住从一个短语到另一个短语的翻译。 因此,我们认为这代表了互联网上国际通用语言(interlingua)的存在。
我们还在论文中写下了更多的结果和分析,希望这些发现不仅能帮助从事机器学习或机器翻译的研究人员,还能帮助语言学家和对使用单一系统处理多种语言感兴趣的人们。 有用。
最后,上述多语言谷歌神经机器翻译系统(Multilingual Google Neural Machine Translation)将从今天开始逐步向所有谷歌翻译用户提供服务。 目前的多语言系统能够转换最近推出的 16 种语言对中的 10 种机械英语翻译软件,提高翻译质量并简化生产架构。
商用部署后,实现技术突破
前面提到,今年 9 月,谷歌宣布针对部分语言推出名为谷歌神经机器翻译(GNMT)的新系统,并显着提高了几种首次使用的测试语言(包括中文)的翻译质量。
下面的动画展示了GNMT进行中英翻译的过程。 首先,网络将汉字(输入)编码为向量序列,每个向量代表当前读取的含义(即e3代表“知识就是”,e5代表“知识就是力量”)。 读完整个句子后,开始解码,每次生成一个英语单词作为输出(解码器)。
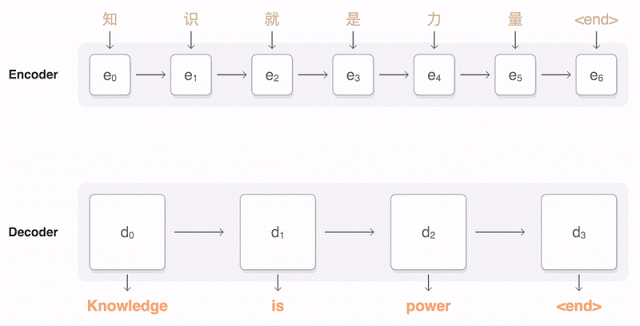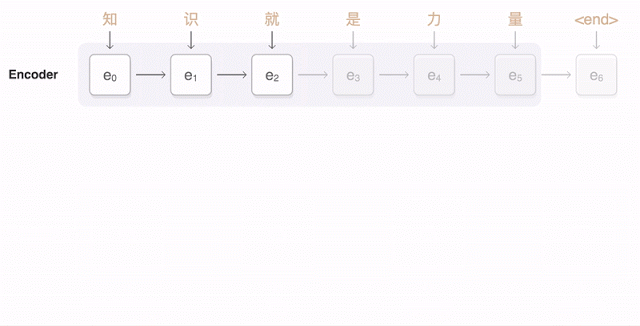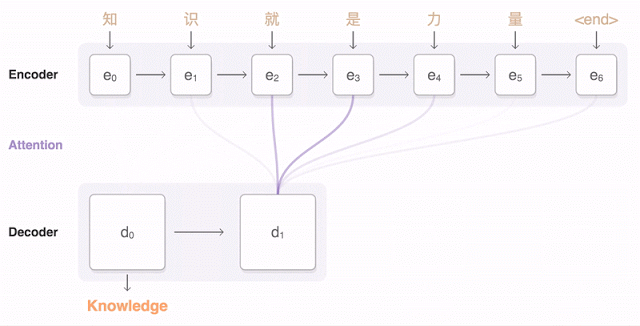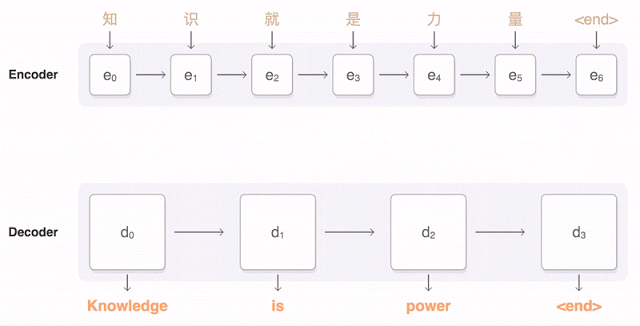
为了在每一步生成翻译后的英文单词,解码器需要关注与生成的英文单词关系最密切的编码中文向量的加权分布(上图中的解码器d,多个透明蓝色中最暗的)该栏上方的线条),解码器关注得越多,蓝色就越深。
与之前的翻译相比,GNMT 系统使用人类比较评分指标,产生显着改进的翻译。 在几种重要语言中,GNMT 可以将翻译错误减少 55%-58%。
然而,当时的许多研究人员认为,谷歌翻译当时取得的“里程碑”更多的是工程上的胜利,而不是技术上的突破——大规模部署本身确实需要软硬件方面的超强实力,尤其是如果你想像谷歌翻译这样支持一万多种语言的商业应用,对速度和质量的要求非常高。 然而,神经机器翻译技术早已存在,从语言和图像处理中汲取灵感,是多种技术的融合。
现在,仅用了大约 2 个月的时间(该论文于 11 月 14 日首次上传到 arXiv),谷歌翻译和谷歌大脑团队就实现了技术突破——允许系统解释以前从未见过的语言对。 翻译,也称为“零样本翻译”。
不仅如此,谷歌研究人员还在论文最后分析称,新模型代表了实现“国际通用语言”模式的可能性。 有评论称,这可以说是实现“巴别塔”的第一步。
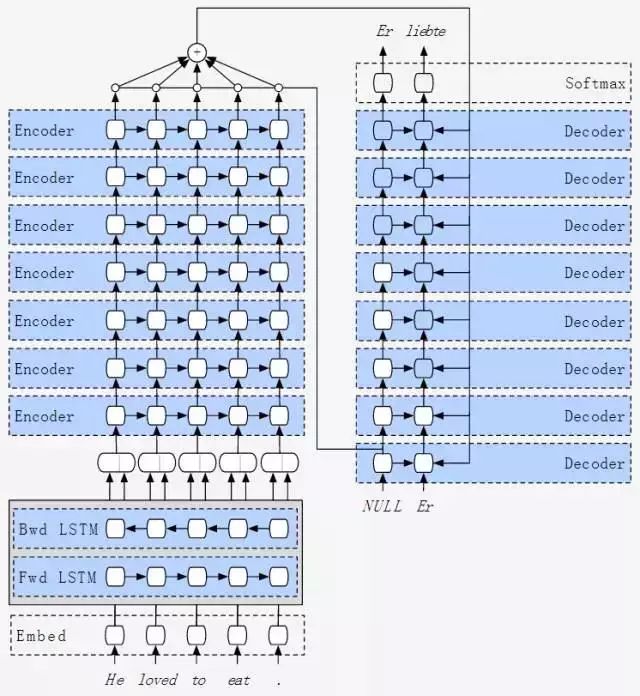
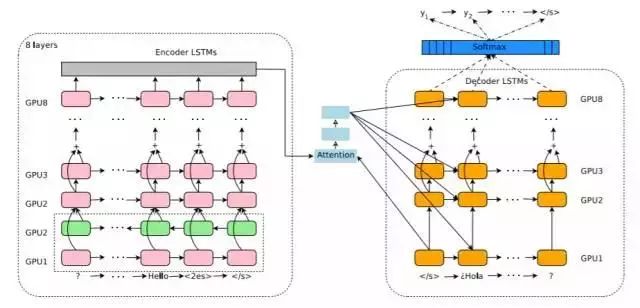
谷歌神经机器翻译系统架构
就在几天前,国外研究员Smerity在其博客上发表了一篇分析谷歌神经机器翻译(GNMT)架构的文章,引发了HackerNews、Reddit等网站的大量讨论。
Smerity在博文中指出,GNMT的架构并不标准,很多情况下偏离主流学术论文提出的架构。 不过,根据谷歌的具体需求,谷歌对系统进行了修改,重点是保证系统的实用性,而不是追求顶级结果。
[论文]谷歌多语言神经机器翻译系统:实现零样本翻译
总结如下:
我们提出了一种简单而优雅的解决方案,用于使用单个神经机器翻译(NMT)模型在多种语言之间进行翻译。 无需修改Google现有的基本系统模型架构。 相反机械英语翻译软件,在输入句子前面添加一个手动标记(token),以明确其要翻译成的目标语言。
模型的其他部分,包括编码器、解码器和注意力模型,保持不变,并且可以在所有语言之间共享。 该方法利用共享词片词汇表,可以在不增加参数的情况下使用单一模型实现多语言神经机器翻译,比之前提出的方法更简单。
实验表明,这种新方法可以在大多数时间提高所有相关语言对的翻译质量,同时保持整体模型参数不变。
在WMT'14基准上,单一多语言模型在英法双语翻译上取得了与state-of-the-art相同的结果,并且超越了在英-德双语翻译上的state-of-the-art。
同时,单一多语言模型分别超越了目前 WMT'14 和 WMT'15 基准上最好的法语-英语和德语-英语翻译成绩。 在生产语料库中,具有多达 12 个语言对的多语言模型能够比许多单独的语言对获得更好的性能。
除了提高用于训练模型的语言对的翻译质量之外,新模型还可以在训练过程中将未见过的语言对相互桥接,展示神经翻译的迁移学习和零数据翻译。 有可能的。
最后,我们分析了最先进的模型对通用语言间表示的指示,并展示了混合语言时出现的一些有趣的案例。

