AI技术评论注:本文为狐老大为雷锋网AI技术评论独家撰稿。 未经许可严禁转载。
最近,关于生成模型的两件事被广泛讨论。 第二个是Nvidia基于样式的StyleGAN生成了足够的假脸高清图像(1024x1024)[1],另一个是论文DeepFakes:aNewThreattoFaceRecognition?AssessmentandDetection[2]表明DeepFakes生成的假脸足够了误导大多数更先进的面部识别和测量系统。 凭借这两件事,2017年底诞生、后来被Reddit讨论区禁止的Deepfakes再次进入了我们的视野。 时隔一年,此时此刻deepfakes取得了哪些进展?
不仅仅是Deepfakes,另一个热门话题是深度学习在工程中的实现。
本文希望通过deepfakes从第一个版本到当前版本的演变来思考深度学习的实现和论文发表之间的差异。
什么是 Deepfakes?其原理是什么?
在 RethinkDeepfakes 之前,先回答一个你第一次接触 Deepfakes 时可能会有的问题。 为什么要这样设计而不是使用CycleGAN呢?
看一张图(图1):

这张图展示了CycleGAN在同一数据集(Trump、Cage)上的效果,其中第一列和第三列是输入,第二列和第四列是对应的输出。
对于成功的例子来说,生成的图像是清晰的,而且转换是全局转换(Deepfakes是局部转换,后面会讲到),但是对于失败的例子来说,问题较多:
第一个明显的点是表达式不能是一一对应的。 一是出现混合且无意义的像素。
关于第二点,虽然Deepfakes也会存在,但作为一个工程项目,Deepfakes有一定的手段来处理这一点,但第一点是一个致命的错误。 如果很难保证对应的表达,那么输出再清晰也是没有意义的。
至于为什么会这样,我会在介绍DeepFakes之后给出我的解释。
我们在这里了解了 CycleGAN 的局限性。 CycleGAN 保证语义变化,但不能保证一些细节。 让我们介绍一下Deepfakes的初始结构。
首先,DeepFakes的整体结构是denoiseautoencoder。 作者做了一个假设:对于任意一张脸A,经过仿射变换后,得到WA,其中WA相当于任意一张脸,即任意一张脸都是A扭曲的,所以如果网络能够从WA中学习去噪和patch到 A,那么网络可以将任意面转换为 A。
而且在网络结构的设计上,作者应该也是花了很多心思的。 它利用编码器中的全链接层来破坏前面频域层提取的特征中的空间关系,从而使每个像素都可以得到充分的计算,而解码器中的PixelShuffler结构也是这样考虑的。 在[3]中,有知乎用户指出,如果省略这个结构,模型就会退化为AutoEncoder,无法得到想要的结果。
整个网络共享一个编码器,而使用两个解码器的目的是让编码器学习更丰富的头部特征,在同一个潜在空间中对不同的人脸进行编码,然后使用不同的解码器使用不同的方法“重构”回来。

图片来自[4]
但有趣的是,乍一看,无论是假设还是设计都很巧妙,但 2017 年底设计的模型并没有使用 CV 领域的一些常见设置,比如方差结构,甚至范数层。 图像未缩放为 [-1, 1],而是缩放为 [0, 1]。 有相关文献认为方差和范数都可以起到平滑损失表面的作用。 后续的改进修改了这三点,有帮助模型收敛。
原始DeepFakes的输出效果如图所示:

第一列和第四列是原始图像,第二列和第五列是构建结果,第三列和第六列是换脸结果。 可以观察到原始 Deepfake 转换中的面部表情细节得到了保留,但比 GAN 生成的结果更加模糊。
动机分析
1.对于CycleGAN的结果,我们可以分析它的损失。 CycleGAN如何判断从A到B的转换? 没错,就是针对损失。 无论是KL散度、JS散度……都是判断两个分布之间的距离。 从概率论的基础知识我们可以知道,当X和Y均匀分布时,我们的意思是X和Y在概率上具有相同的性质,比如EX=EY,但不能得到X=Y,这说明: GAN具有非常强大的“创造力”。 同时,当数据量不够时,GAN的训练是有问题的(因为数据不能很好地表示分布,很容易崩溃生成某种特殊情况)。 数据集中,Cage的正面数据较少,而Trump则相反,所以Trump的正面转换基本失败。 如图1所示,第三行第一、第二列。
在将cyclegan应用于马和斑马的转换过程中也可以观察到同样的问题。

而以MSE和MAE的逐像素偏差作为优化目标可以缓解此类问题。
2.DeepFakes并不完美。 二是使用MAE作为loss有平均值,会导致图像模糊。 首先,WA=任意面,这个假设是有局限性的。
第一点,用女面B代替男面A,本质上比用女面B代替男面A更困难。
其次,这个假设将变换限制在面部特征周围的部分,无论面部是否对齐,仿射变换的参数都会影响结果。 DeepFakes改进版的每个模型插件对应不同的仿射变换参数,对人脸进行预处理需要花费很大的精力。 而cyclegan对预处理的要求并没有那么高。 正是因为变换只能在局部进行,而原模型生成的图像大小固定为64x64,所以生成后几乎不可避免地要做resize,原本模糊的人脸会进一步模糊。
第三点军装照片合成软件,这一点完全是对数据的理解能力。 在美图横行的时代,如果只考虑五官数据,一些女演员的脸部数据对五官的辨别力极低,导致疗效不理想。
提升
分析完问题后,首先要解决的也是最容易解决的问题就是清晰度问题。
生成图片清晰度的问题是由于MAE的平均值造成的。 我们可以通过引入GAN来解决这个问题。 目前,在[4]中,作者引入了两个Discriminator,对应AB图,就像cycleGAN一样,甚至还引入了cycleconsistencyloss。 ,并且在官方项目中,作者像pix2pix中一样引入了conditionGAN,不仅可以判断真伪,还可以区分是否配对。
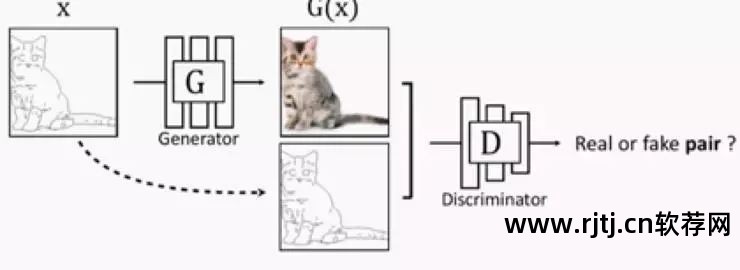
在我的实验中,由于早已确定 Deepfakes 是 denoiseautoencoder 的思想,因此只需要引入一个 Discriminator 来补充生成图像的细节,而不管 A 和 B 之间的差异。就像其他 SR 和去噪任务一样。 这样得到的结果在视觉上是相似的,这样可以节省一些参数,其次,如果A或B的数据量不大,虽然这会让训练更加稳定。 其中非常强调的是,gan看似让图像更加清晰,但并不能保证细节与原图一致,这涉及到两个应用场景。 更注重视觉效果或者细节还原,即使Deepfakes是后者,所以引入对抗也是可以接受的。

可以看到,经过GAN得到的结果比没有经过GAN的结果更加清晰,但同时又存在另一个问题。 当A没有胡子而B的训练样本有胡子时,GAN会捕捉B有胡子的特征。 当A转换B时,将手动添加胡须。 如果AB中的任何一方有太阳镜而另一方没有,这种转换的效果也是一样的。
为什么要提这个,因为即使从常识理解,GAN 的“添油加醋”也不正确,但其实,我们不妨从人类自身出发,我们如何判断 A 是 A人类感知的术语?
这很简单。 与五官相比,一个人是否有胡须、墨镜、短发也同样重要。 虽然单独取出五官,但人们的识别率并不高。 如果是四肢的照片,身体的姿势同样重要,所以如果一个人长期被表现为留胡子的人,你看到他没有胡子,但你觉得这是违法的。 因此,GAN从数据中捕获了主要特征,从而产生了更多的胡须。 虽然不是大问题,但更重要的是解决视频转换。 胡须的特征在某个画面中会突然丧失,违和感会更加严重。 一些。
为了解决这个问题,[4]和DeepFakes官方更新中采用了Mask机制。 Mask网络和生成网络共享除最后一层之外的所有层的编码器和解码器。 最后一层生成一个Mask,取值范围为0到1。假设生成的图片记为G,原图记为S,所以最终使用的图像为
这样,让模型学习图像中需要转换的部分。

图片来自[4]的项目主页
我们再多谈谈 GAN 的结构。 我之前也曾迷茫过。 在这么多的图像转换或者图像编辑中,为什么更多的使用StandardGAN的损失,而其他理论上和结果都很漂亮的GAN(如WGAN-GP、SAGAN)却很少使用。 经过一番讨论,结果是这种GAN带来的差异还不如在论文中贴一张好看的图片。 结果让人无语,但却很现实。
造成这一现实的原因可能有以下几个:
1、任务类型不同。 目前效果惊人的GAN大多是随机分布生成图片,图片转换大多是在encoder-decoder结构下进行改进。 前者比后者多了一个编码器来对图像进行编码,而额外的 σ 先验信息可能会增加对生成器结构的依赖。
2.GAN评估本身存在局限性。
在知乎上,有朋友在[5]和[6]中指出了IS和FID的缺点。 GAN作者本人也提出了一种新的评估GAN的方法,但并没有引起太大的反响。
在我看来,不同的GAN之间肯定存在差异,但至少在图片的视觉效果上不需要应用另一个GAN。
在[4]中,作者介绍了self-attention机制,即SAGAN,并且self-attention的层数比SAGAN更多,但是在官方改进版本中,并没有介绍这一点。 我根据SAGAN-attention的结构添加了self,得到如下生成结果:

可以看出,与 self-attention 和 SpectralNorm 引入的额外估计器相比,SAGAN 并没有给 Deepfakes 带来足够的优势。
分析完损失函数对清晰度的影响,我们再来说说另一个影响清晰度的因素,规格问题。
规格问题很简单。 现在生成模型甚至可以生成1024张图像,高清人脸也不成问题。 但这里我想让大家思考一个问题,DeepFakes真的需要生成高清人脸吗? 或者什么时候需要?
后面详细解释Deepfakes的原理时,我们提到最好不要去掉全连接层,所以此时降低图像规格必然会导致全连接层的参数激增,从而造成延迟用户对自己的数据集进行迁移的时间。
我们需要意识到规范对DeepFakes应用场景的影响。 市面上的换脸场景大致有两种。 第一个就是之前的“军装照”,属于单张照片的换脸。 一是合成视频图像。
后者,人脸大多占图像的绝大多数,此时形成高质量的人脸就显得很重要。 前者大多出现在半身照片中,人脸的码率对感知影响不大。 此时,高帧率图像形成后,需要调整码率大小以降低码率军装照片合成软件,这也会导致细节的丢失。
数据质量对DeepFake的影响
在数据挖掘和机器学习领域,有一个说法非常被指出,那就是GarbageIn,GarbageOut。 数据质量决定了模型的上限。 这一特性在 DeepFake 中得到了充分的体现。
上文提到,DeepFake 的关键假设是 Wrapface=anyface,因此采用 denoiseGAN 的结构。 不难想到,除了利用仿射变换制作噪声头之外,还有没有其他方法呢? 答案是肯定的。 在[4]中,作者使用probrandomcolor_match交换两种不同人脸颜色的均值和残差来制造噪声,并使用motionblurs、运动模糊来破坏原始人脸,而这两种处理方法也可以看作是一种数据手段增强。
另外,为了让模型更好的训练,我们利用了eye-aware(人脸对齐)、edgeloss以及上面提到的Mask机制,修改了官方原版Dlib,改成了MTCNN来进行人脸定位和关键点定位,以及人脸对齐等操作,以获得更好、更灵活的数据。 由于Dlib在正面和遮挡的情况下表现比MTCNN差。
对数据的干扰不仅包括数据预处理,还包括数据后处理。
获得模型输出后,需要将其映射回来。 这时也可以采用传统的图像处理方法,如高斯模糊、泊松融合等图像融合方法。
不难知道,无论是[4]还是官方项目,在DeepFakes第一个版本之后所做的改进中,在模型的层上仅采用了场景的NormLayer和ResBlock等常见方法,而不是采用场景的NormLayer和ResBlock等常见方法。比重新发明更强大的网络结构可能会使用一些先进的层和理论,但侧重于数据干预和问题建模的重新思考。
论文和项目之间的区别
回顾DeepFakes的发展历程,不难得出与我们平时写论文时的思维有些不同。 第一个显着的特点是,在论文上,我们更加注重论文的可发表性。 比如论文作品是否时尚,理论是否优美。 比如深度学习流行起来之后,深度学习被运用在各个领域,有的是突破,有的只是为了吸引眼球。 GAN火了之后,他们又涌向GAN。 从工程上来说,很大程度上是这些趋势模型==疗效不错的心态。 知乎上对此问题有更广泛的讨论[7]。 上面还强调了,与使用 LSGAN 相比,SAGAN 在 DeepFakes 上并没有带来足够的优势。
第二点是了解论文的一些套路。 很多事情,比如实验结果上的一些统计陷阱,或者结果显示的选择,都会给读者带来困惑。 例如,即使是 BigGAN 级别的网络也会形成无意义的输出,而其余的 GAN 不太可能像论文中显示的那样稳定。 与隐藏失败样本的论文不同,在线应用程序有时对错误更加敏感。 其实事物的发展需要一个过程。 如果太严格,很多论文可能会被杀掉。
对模型影响最大的是数据。 大家可能都知道GIGO原理。 然而,由于你写论文并在公共数据集上测试它们,而公共数据集通常相对干净,随着时间的推移,你可能会忘记并习惯忽略它们。 而一旦你经历过在线项目或者个人项目,当你需要自己收集数据或者清理数据的时候你就能体会到其中的滋味。 70%的时间都在处理数据本身,这并非危言耸听。
论文[8]比较了几种常见的数据增强对模型性能的影响。 可见,在公共数据集上使用不同的数据处理方案也会影响模型的性能,但只做数据预处理的文章很难发表,除非有mixup等新方法达到令人震惊的疗效影响。
还有对业务场景的理解,这种情况经常见到,但新人会一头雾水。 对业务场景的理解是什么? 回顾上面,思考单帧视频和人脸爆头的规格,如何提出更合适的假设,以及遮挡物是否影响人们对“脸”及其身份的感知,这就是思考的应用场景。 只有了解了业务场景,才能做出合适的模型架构、数据预处理和后处理。 比如有些场景,需要先进行关键点对齐,也是这个原因。 总的来说,深度学习具有巨大的潜力,但前提是它用在正确的地方。
另一方面,相比论文中开源的训练脚本,如果有更成熟的工业库,还是值得学习的。 因为在工程项目中,当数据规模达到一定程度时,在分布式环境下,一些模型的实现有很多种变体。 例如[9]中提到的跨卡同步BN。 有兴趣的朋友可以看一些工程驱动的论文,比如YouTube的推荐系统上的论文,比如阿里的鲁班,还有美团的类似的智能海报技术。 事实上,它是一个“生成”的海报,但实际上GAN只是其中的一个组成部分,并且非常巧妙地将这种看起来像imagegenerate的黑盒问题替换为需要更好控制和干预的Seq2Seq问题。
后记
关于上面论文和项目的区别,你可能在很多场合都见过,其中有一些是事实推论,但如果你问身边的人掌握某一点,他们往往什么也不说。 本文继续DeepFakes的发展,加上个人观点,分析当我们预见到这样的问题时,可以从这几个方面进行分析和改进。
至于为什么选择DeepFakes,虽然这不是一个小项目,但DeepFakes开始在应用程序上而不是脚本上进行开发。 相应的,DeepFakes的设计和考虑始终是面向工程的,还是有参考价值的。
参考
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
