我们首先要厘清以下几个问题:
聊天软件是基于1对1聊天还是群组聊天还是都需要?
是移动端软件还是网页端软件还是说都需要
用户规模是怎样的?(DAU)
对于群组聊天,人员上限是多少人?
聊天软件必须要有什么样的功能呢?是否需要支持上传附件?
有没有信息大小限制?
是否需要加密?
聊天记录需要保存多少时间?
现在假设我们要设计的聊天软件是基于一对一聊天且支持小规模群组聊天(上限100人),同时有在线显示。支持多种设备,同一个账号能同时登陆多台设备,支持推送提醒。
在设计聊天系统之前,我们需要了解一些概念。
比如说客户端和服务器之间是如何沟通的。客户端可能是移动端应用也有可能是网络应用。客户端之间并不会直接沟通。他们是会连接到一个聊天服务,这个聊天服务支持上述所有功能。比如说以下:
从其他用户那里接收到信息
找到每条信息对应的接收方并发送信息
如果接收方并不在线,在服务器中保存这条信息直到用户上线

当一个客户端想要开始聊天,它会使用一个或多个网络协议来连接到聊天服务。对于一个聊天服务来说,网络协议是非常重要的。当发送方通过聊天服务发送信息到接收方,使用的是HTTP 协议,这个最常用的网络协议。在这种场景下,客户端通过HTTP连接到聊天服务并且发送信息,通知服务发送信息给到接收方。在这种情境下保持活动状态是高效的因为这允许客户端与聊天服务保持持久的连接,减少TCP 握手次数。对于发送方来说HTTP时一个好的选择,许多主流的聊天应用已开始都是使用HTTP来发送信息。
然而,对于接收方来说可能会有一些复杂。因为HTTP是客户端发起的,从服务器发送信息并非易事。多年来,许多技术被用来模拟服务器发起的连接:轮询、长轮询和WebSocket。
轮询
轮询是指客户端会周期性的询问服务器是否有信息。根据轮询频率,轮询可能会很耗费资源。它可能会消耗宝贵的服务器资源来回答一个大多数时间答案为“否”的问题。

长轮询
长轮询解决了轮询的低效问题
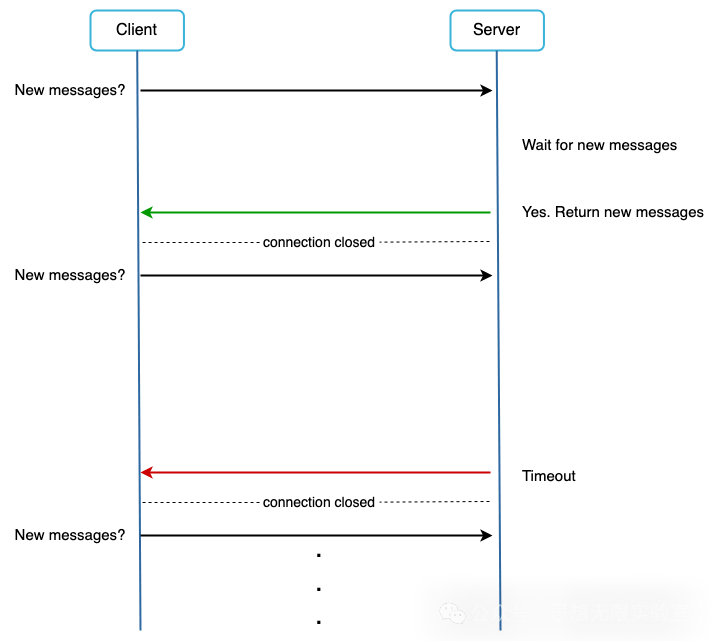
在长轮询中,客户端会保持连接打开状态直到有新信息或者达到超时阈值。一旦客户端接收到新信息,它会马上发送另外的请求到服务器,重启流程。长轮询有以下几个缺点:
发送方和接收方可能并没有连接到同一个聊天服务。 基于HTTP的服务器通常是无状态的。如果使用轮询算法进行负载均衡,接收信息的服务器可能没有与接收消息的客户端建立长轮询连接。
服务器并没有一个好的方式显示是否客户端失联了
如果一个用户并不经常聊天,长轮询仍然会在超时后发起周期性连接,这样导致了低效。
WebSocket!
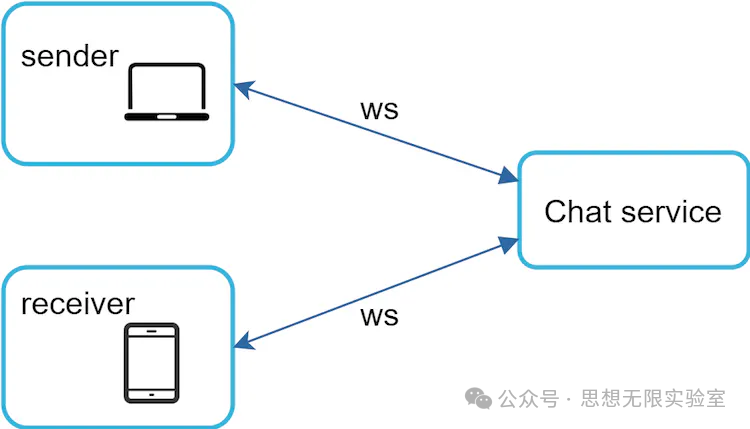
Websocket 是最常用于发送从服务器端到客户端异步更新的解决方式。
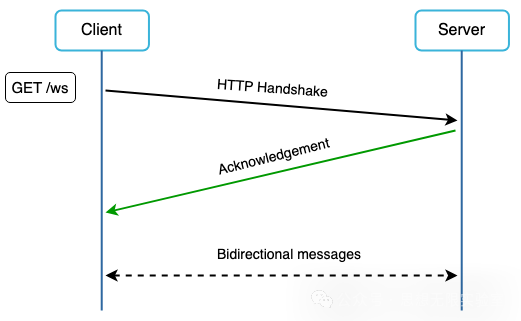
Websocket 连接由客户端发起。它是双向且持续的。它一开始是一个HTTP连接,并且可以通过一些明确定义的握手过程被升级为Websocket 连接。通过这个持续性的连接,服务器可以发送更新到客户端。
在发送和接收时使用websocket 简化了设计并且在客户端和服务器端的实施变得更为直接。由于websocket连接是持续的,高效的服务器端的连接管理是很重要的。
高阶设计
我们选择websocket作为客户端和服务器之间双向沟通的主要通信协议,重点提一下的是其他的部分不一定使用websocket。事实上,大多数功能(注册,登陆,用户资料等)可以通过HTTP上的传统请求/响应方法来使用。
可以看到,架构图中分为3个主要部分:无状态服务,有状态服务和第三方集成。
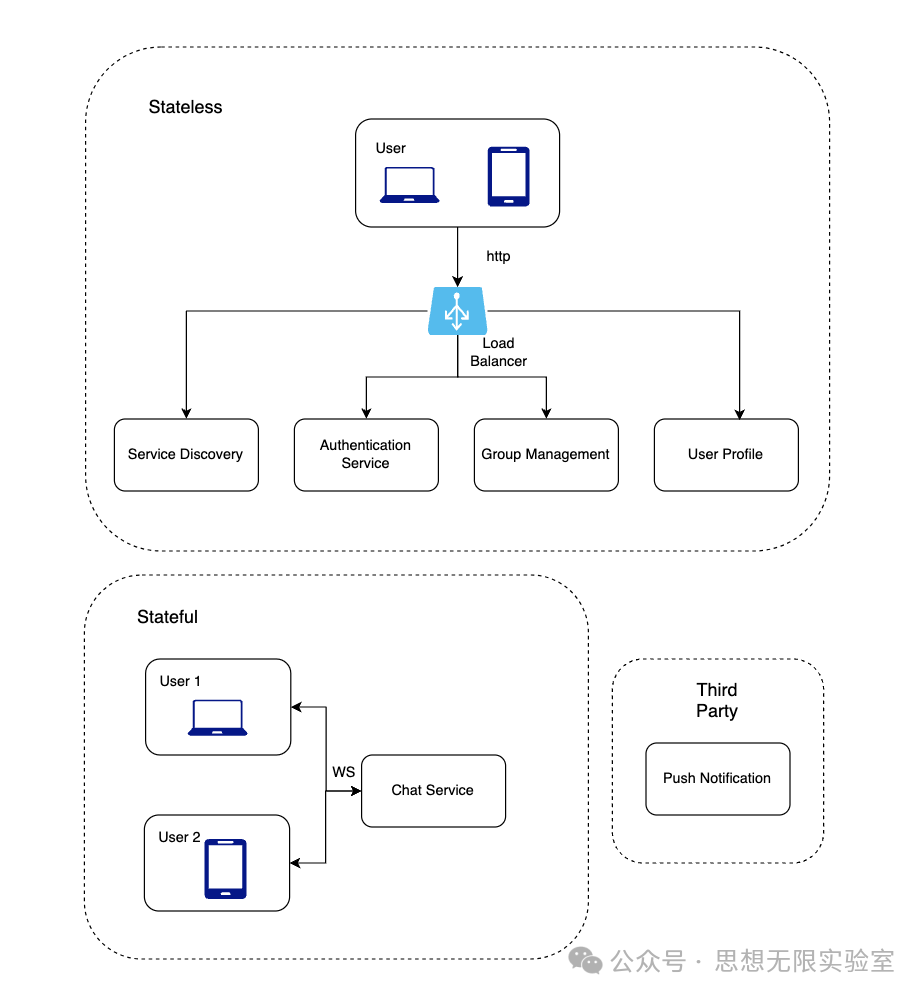
无状态服务
无状态服务是传统的面向公众的请求/响应服务,用于管理登录、注册、用户资料等。这些是许多网站和应用中的常见功能。
无状态服务位于负载均衡器后面,其工作是基于请求路径将请求路由到正确的服务。这些服务可以是单体式的或单独的微服务。我们不需要自己构建许多这样的无状态服务,因为市场上有可以轻松集成的服务。我们将更深入讨论的一个服务是Service Discovery。它的主要工作是向客户端提供一系列聊天服务器的DNS主机名,客户端可以连接到这些服务器。
有状态服务
唯一的有状态服务是聊天服务。该服务是有状态的,因为每个客户端都维持着与聊天服务器的持久网络连接。在这项服务中,只要服务器仍然可用,客户端通常不会切换到另一个聊天服务器。Service Discovery与聊天服务紧密协调,以避免服务器过载。我们将在深入探讨中详细讨论。
第三方集成
对于一款聊天app来说,推送信息是最重要的第三方集成。即使app没有在跑,它也能通知用户有新信息。
规模化
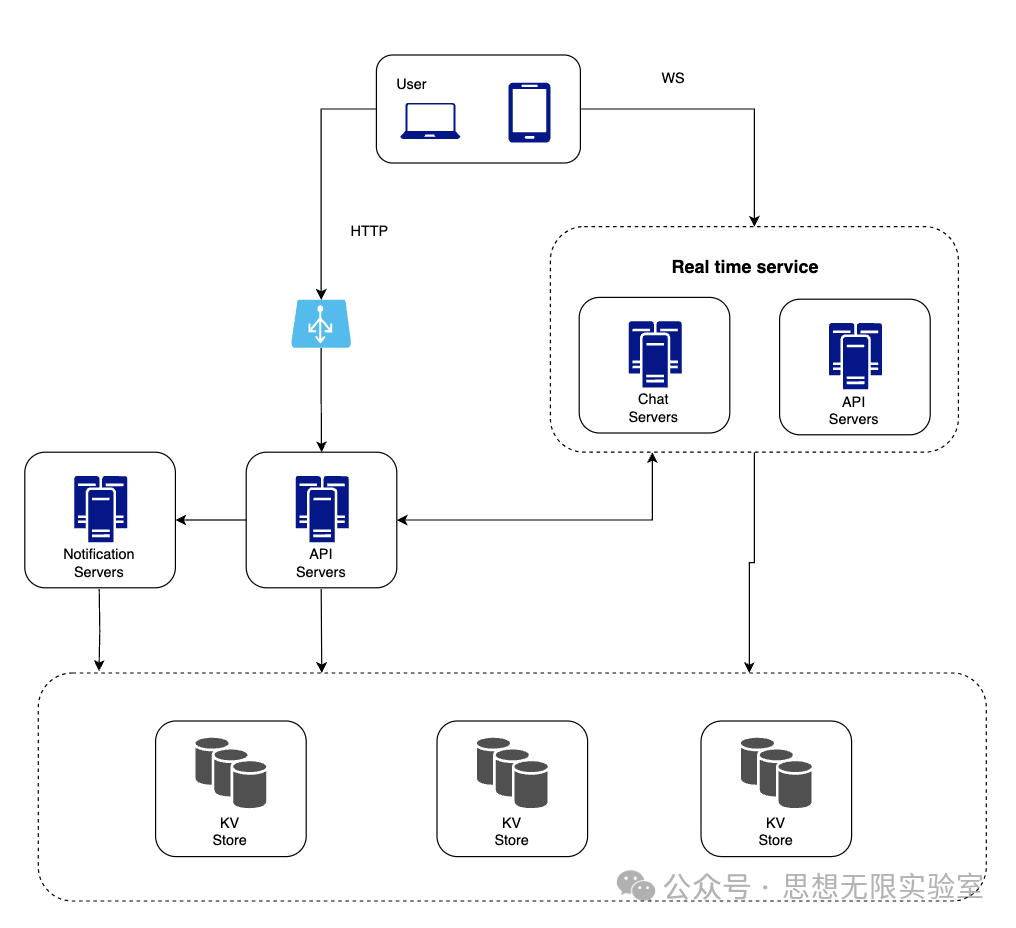
上图中,
客户端维持着与聊天服务器的持久WebSocket连接,以实现实时消息传递。
聊天服务器促进消息的发送/接收。
存在服务器管理在线/离线状态。
API服务器处理包括用户登录、注册、修改资料等在内的所有事务。
通知服务器发送推送通知。
键值存储用于存储聊天历史。当一个离线用户上线时,将看到之前的所有聊天历史。
存储
到目前为止,服务器已准备就绪,服务搭建以及第三方集成也已经完成。下一步便是数据层。首先一个重要的决定是我们需要用什么类型的数据库:关系型的还是NoSQL?
这时候我们应该从数据类型和读写模式入手。
在典型的聊天系统中,存在两种数据。第一种是通用类数据,比如说用户资料,设置,用户好友列表。这些数据被存储在关系型数据库中。复制和分片是通常用户可用性和规模化的技术。
第二种数据聊天历史记录。我们首先要了解下读写模式:
对于聊天系统来说,数据量是巨大的
只有最近的聊天是会被经常访问的
尽管大多数情况下是访问最近的聊天历史,用户可能需要随机访问数据,例如搜索,查看提到自己的信息,跳到特定信息等。数据访问层应该支持这些功能
对于1对1 的聊天软件来说,读写比大约为1:1
选择正确的存储系统来支持所有的用例是重要的。推荐使用键值存储:
键值存储支持轻松的水平扩展
键值存储提供非常低的数据访问延迟
关系型数据库不擅长处理数据的长尾。当索引增长到一定规模的时候,随机访问成本很高。
数据模型
1对1 聊天的消息表
主键是message_id,决定消息顺序。我们不能依赖于created_at来决定消息顺序因为两条消息能够同时创建。

群聊的消息表
复合主键是(channel_id, message_id)。channel_id是分区键,因为群聊中的所有查询都在一个频道内进行。

message id
如何生成message_id是一个值得探讨的有趣话题。message_id承担着确保消息顺序的作用。它必须满足以下两个要求:
ID 必须是唯一的
ID 必须可按时间排序,意思是新ID要比之前的ID要大
那么我们如何确保这两点呢?在MySQL中有auto_increment功能,然而,NoSQL数据库通常不提供这样的功能。
第二种方式是使用类似Snowflake的全局64位序列号生成器。
最后一种方式是使用本地序列号生成器。本地也就意味着ID只能在一个群组内确保其唯一性。但是对于一对一聊天或者群聊来说已经是足够的了。这种方式对比起全局ID唯一性要简单。
